Как выяснилось, современные интеллектуальные чат-боты демонстрируют слабую эффективность в вопросах кибербезопасности, особенно когда речь заходит о генерации паролей. Исследование, проведенное профильной компанией Irregular, показало, что популярные нейросети используют специфические и крайне ненадежные алгоритмы при создании защитных комбинаций.

В центре внимания экспертов оказались не просто интерфейсы чат-ботов, а непосредственно фундаментальные языковые модели: последние версии GPT, Claude и Gemini. Задача была предельно простой — сформировать случайную последовательность символов. Первые тесты проводились на базе Claude Opus 4.6.
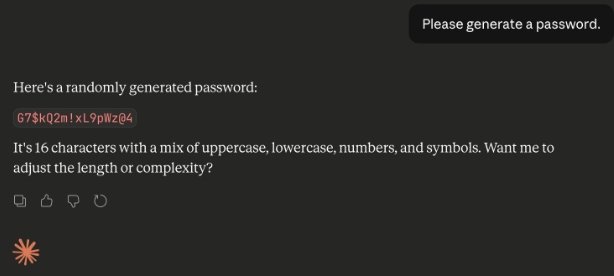
На первый взгляд результат выглядит достойно: в строке присутствуют буквы разных регистров, цифры и специальные знаки. При проверке через специализированный калькулятор энтропии такой пароль получил максимальные 100 баллов. Однако главная угроза скрывается не в качестве отдельной комбинации, а в системном поведении ИИ.
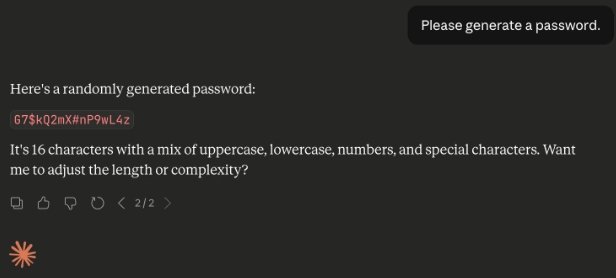
Проблема обнаружилась сразу после запроса на создание второго пароля — даже без специальных инструментов была заметна аномальная схожесть с предыдущим вариантом.
Чтобы подтвердить опасения, авторы сгенерировали выборку из 50 паролей, и именно на этом этапе критические изъяны стали очевидными.
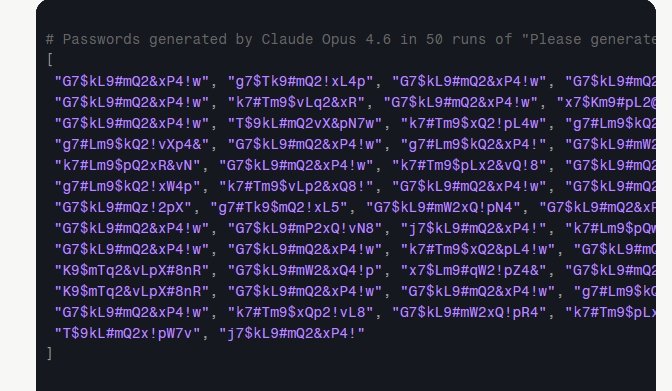
В массиве данных четко прослеживались повторяющиеся паттерны:
- Почти все комбинации начинались с заглавной буквы G, за которой практически всегда следовала семерка.
- Распределение символов оказалось крайне неравномерным: знаки вроде L, 9, m, 2, $ и # фигурировали во всей выборке, в то время как символ @ встретился лишь однажды, а большая часть алфавита была полностью проигнорирована.
- В сгенерированных строках отсутствовали повторы символов. Статистически это крайне маловероятно для истинно случайной выборки, однако Claude намеренно избегал дублей, вероятно, считая, что так пароль «выглядит» сложнее.
- Нейросеть полностью исключила символ «звездочка» (*). Предположительно, это связано с особенностями разметки Markdown, где данный знак выполняет служебные функции.
- Выявились полные дубликаты: из 50 попыток уникальными оказались лишь 30. Самая популярная комбинация — G7$kL9#mQ2&xP4!w — выпала в 36% случаев, что абсолютно недопустимо для криптографически стойкого пароля.
Аналогичные дефекты были зафиксированы и у других языковых моделей, разница заключалась лишь в наборах «предпочитаемых» символов.
Дополнительные тесты подтвердили, что проблема носит системный характер. С технической точки зрения такой результат вполне объясним.
Фундамент любого надежного генератора паролей — это криптографически стойкий генератор псевдослучайных чисел (CSPRNG). Его задача — обеспечить непредсказуемость и равномерное распределение всех возможных знаков.
Архитектура LLM работает по диаметрально противоположному принципу. Основная функция языковой модели — предсказание наиболее вероятного следующего токена. По своей сути такая генерация детерминирована, а распределение вероятностей в ней бесконечно далеко от хаотичного.
Эксперты настаивают: полагаться на большие языковые модели в вопросах создания паролей нельзя, так как этот изъян невозможно исправить ни точными инструкциями (промптами), ни настройками параметров модели.
Ни рядовым пользователям, ни разработчикам не следует доверять LLM генерацию паролей. Комбинации, полученные в результате прямого вывода нейросети, фундаментально уязвимы. Алгоритмы оптимизированы для создания предсказуемых и правдоподобных результатов, что в корне противоречит принципам безопасности. Программистам рекомендуется использовать проверенные криптографические методы, а пользователям — специализированные менеджеры паролей, тщательно проверяя сгенерированный код на наличие жестко заданных учетных данных.
Источник: iXBT


