В последний год в моей ленте ВК и в большом Интернете множатся новости о том, что искусственный интеллект научился рисовать картинки по текстовому описанию. Широко известна нейронная сеть DALL-E от Microsoft, предназначенная для этой цели; она вышла в мае 2021 года. Слегка шизофреническое творчество нейросеток не то чтобы сильно впечатлило меня, но навело на мысль: а какие процессы можно автоматизировать при помощи таких технологий? Наиболее интересным утилитарным направлением мне показалось рисование пользовательских интерфейсов и генерация подписей к рисункам. Сегодня расскажу как раз о таких разработках.
Искусственный интеллект с человеческим лицом
Феномен «искусственного интеллекта» сравнительно новый. В 1950 и 1951 году соответственно вышли фундаментальные статьи Алана Тьюринга «Может ли машина мыслить»? и Джона фон Неймана «Общая и логическая теория автоматов», их переводы на русский язык размещены здесь. Также в этот ряд я добавил бы постоянно обновляемую статью Леонида Ашкинази, впервые опубликованную в 2005 году, и древнюю по меркам Хабра статью «Может ли машина мыслить» (9.02.2009) под авторством Степана Овчинникова. Начнем с того, что искусственный интеллект в современном понимании – это ANI (ограниченный искусственный интеллект), и он представляет собой совокупность алгоритмов, призванных облегчить человеку некоторые задачи, для человека особенно сложные. Например, просчитывать тенденции. Некоторые задачи, решаемые человеком практически непроизвольно, скажем, распознавание образов или эмоций, для современного ИИ очень сложны или практически неразрешимы.
Сегодня под искусственным интеллектом все чаще понимается машинное обучение (ML), глубокое обучение (DL) и обучение с подкреплением (RL). Все эти парадигмы сводятся к логическому выводу на материале предоставленного множества данных, в соответствии с заложенными алгоритмами. Но на самом деле такие системы просто имитируют функции человеческого мозга, в частности, обучение и решение задач. ИИ программируют люди, а все люди предвзяты, и поэтому ИИ также может быть объективен лишь до некоторой степени. У ИИ нет сознания, поэтому (пока) он ничего по-настоящему не «понимает». В моем блоге с переводами я однажды размещал статью о некоторых причинах, по которым прогресс машинного обучения замедляется (комментарии получились не менее интересными, чем статья). При этом одним из важнейших направлений развития искусственного интеллекта является развитие человеко-машинных взаимодействий. Эта работа требует учитывать и предугадывать поведение человека при коммуникации, тем самым особенно сближая «машинный» и «человеческий» интеллект. Рассмотрим, каким образом такие взаимодействия и сами пользовательские интерфейсы (прежде всего, графические) превращаются в датасет и поддаются обработке современным искусственным интеллектом.
AI и UI
Искусственный интеллект особенно хорош для выполнения сложных, рутинных и чётко сформулированных задач. Человеческий интеллект, напротив, склонен заниматься вещами простыми и/или интересными. Человек учится на опыте и доводит некоторый приобретённый опыт до автоматизма. Искусственный интеллект учится на множествах данных именно потому, что неспособен приобретать опыт.
Выдающимся примером такого доведения до автоматизма является работа с пользовательским интерфейсом, в особенности, сенсорным. Моторная память в некоторых контекстах оказывается надежнее зрительной и слуховой – так, мне случалось из-за стресса забывать пин-код от банковской карты, но, собравшись с мыслями, я верно набирал его на банкомате, стараясь не смотреть на клавиатуру. Пользовательский опыт – превосходное множество данных, и искусственному интеллекту должно быть вполне по силам изучить человеческие привычки и проектировать пользовательские интерфейсы лучше, чем человек-дизайнер. Здесь отметим, что работа с пользовательским интерфейсом – это, прежде всего, коммуникация: обмен данными между человеком и компьютером, а в социальных сетях – преимущественно между человеком и человеком.
Межчеловеческая коммуникация много лет изучается в рамках теории коммуникации, а коммуникация между машинами, по-видимому, пока не породила полноценную теорию и находится на этапе формулирования машинных онтологий. Промежуточная дисциплина – это изучение коммуникации между человеком и машиной, а такая коммуникация всегда происходит через те или иные пользовательские интерфейсы. Важнейшей частью человеко-машинной коммуникации является проектирование, внедрение и оценка пользовательских интерфейсов. В настоящее время интерес к пользовательским интерфейсам только растет, сами интерфейсы становятся одновременно проще и сложнее. Простоту интерфейса называют «интуитивностью», и ценой такой «простоты» является абстрагирование растущей сложности, которая складывается под капот. Здесь приведены основные качества GUI, из которых складывается его понятность. Обеспечение понятности интерфейса – это сведение его простых свойств до очевидных, а сложных – до логически выводимых. Пользователь должен легко узнавать:
-
Какой элемент интерфейса для чего предназначен
-
Где именно в интерфейсе находятся панели инструментов с какими функциями
-
Какие есть ограничения и допущения (аффордансы) при работе с интерфейсом .
Кроме того, пользователь должен легко получать от интерфейса обратную связь.
Все эти задачи решаемы при помощи современного искусственного интеллекта. Важнейшие роли здесь отводятся компьютерному зрению/распознаванию образов и обучению с подкреплением. Распознавание образов позволяет разлагать интерфейс на составляющие и присваивать значение и вес каждой картинке, а обучение с подкреплением позволяет машине определить по действиям пользователя наиболее востребованные стратегии работы в интерфейсе и, соответственно, оптимизировать их.
Двоякая природа пользовательского интерфейса
Автор книги «Being Digital» Николас Негропонте охарактеризовал пользовательский интерфейс как «место встречи битов и человека» и указал, что при человеко-машинном взаимодействии пользователь одновременно и воспринимает интерфейс, и использует его как канал связи с машиной. Наиболее удобным и эффективным является прямое взаимодействие пользователя с интерфейсом, как, например, в текстовых и табличных редакторах, а также в видеоиграх. .
Успех прямой манипуляции заключается в постоянной обратной связи, которую пользователь получает в ответ на любое действие, сразу видит все изменения как на экране, так и в протекании процессов. Тем не менее, не каждый элемент такой манипуляции может быть описан как конкретный объект, и не каждая решаемая задача чётко разложима на этапы. Кроме того, человек может быть не в состоянии держать в уме все потенциальные последствия некоторого действия. Искусственный интеллект может обучиться статистически предугадывать развитие действий пользователя и снижать эту когнитивную нагрузку. Такие возможности особенно актуальны в инструментах для программирования. В качестве примера поговорим ниже об инструменте pix2code, который генерирует код на основе скриншота пользовательского интерфейса, но сначала рассмотрим подобный процесс в общем виде.
Когда программист создаёт пользовательский интерфейс, он реализует в коде идеи и отношения, выраженные дизайнером в каркасной модели.
Может ли ИИ сделать то же самое? Вполне, например, вот так:

Сначала искусственный интеллект распознаёт объекты, из которых состоит интерфейс (виджеты, панели, надписи), затем находит в учебном датасете, как на практике обычно выстраиваются цепочки использования таких элементов – и выдает собственный вариант пользовательского интерфейса.
При автоматическом описании изображений (image captioning) ИИ пытается угадать, что находится на картинке, подписать каждый объект, а затем кластеризовать и классифицировать то, что у него получилось.

ИИ трактует любую картинку как сцену, вычленяет из нее объекты (планшет, тарелка, бутылка), после чего может составить на естественном языке высказывание, описывающее объекты и характеризующее отношения между ними.
При сборке UI средствами искусственного интеллекта интерфейс может восприниматься как точно такая же картинка, содержащая объекты (кнопка, ползунок, меню), и эту картинку можно охарактеризовать как совокупность отношений между этими объектами. Такой частный случай алгоритмизируется существенно легче общего случая, поскольку и множество элементов более узкое, и возможные отношения между ними более предсказуемы. Характеристики проектируемого интерфейса выражаются не на естественном языке, а в программном коде. Примеры отношений, выражаемых в коде – положение на экране, место в иерархии.
Генерация UI-кода проходит в два этапа.
Стадия обучения
Допустим, некоторый юнит (unit_1), обучающийся просматривать как можно больше изображений UI и генерировать для каждого из этих UI список найденных в нем элементов. Другой юнит (unit_2) учится читать код, описывающий такие UI. Третий юнит (child_3) учится находить взаимосвязи между результатами обучения первого и второго юнита. Все вместе они учатся наблюдать UI и создавать код, который максимально точно описывал бы этот интерфейс.
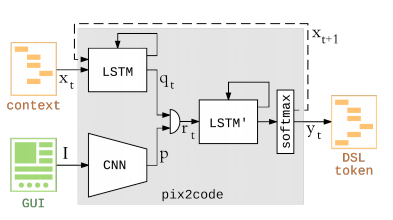
В инструменте pix2code роль первого юнита отводится CNN (сверточной нейронной сети), а на месте юнита 2 и юнита 3 действуют две сети LSTM (сеть долгой краткосрочной памяти.
Стадия сэмплинга:
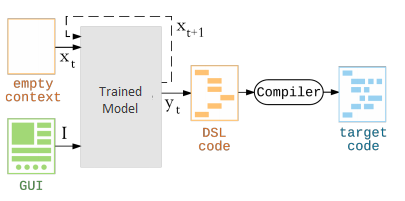
Обученная таким образом модель готова к обработке GUI, отрисованного вручную. Работа идет итерациями, причём, в каждом новом шаге прогноз обновляется с учетом последнего спрогнозированного элемента (токена). Токены в этом инструменте выстраиваются в последовательность, описываемую на специальном DSL-языке, который затем поддается компиляции в язык целевой платформы (Android, iOS, веб – в последнем случае это может быть обычный HTML).
В данном случае важна чрезвычайная абстрактность той модели, которую приходится воплощать искусственному интеллекту. Поэтому работа ИИ по созданию графического интерфейса является частным случаем проблемы «гипотетических миров», которую я немного раскрою далее.
Гипотетические миры
В настоящее время разработка интеллектуальных пользовательских интерфейсов во многом сводится к импровизации и ухищрениям, так как для такой работы не хватает ни инструментов, ни даже структур данных. При интеграции кода приложений с системами машинного обучения возникает новый класс проблем, сводимых к крайней разветвленности выбора. Разветвленность распространяется не только на все возможные допустимые варианты выбора, но и на потенциальные ошибки при выборе, а также на возможные коллизии пользовательских настроек. Кроме сложности с ветвлением выбора здесь вырисовываются ещё две основные технические проблемы: масса бойлерплейта, опосредующего взаимодействие между нейронкой и приложением, а также необходимость собирать и актуализировать множество данных сразу от множества пользователей. Фактически, третья проблема распадается на две самостоятельные: во-первых, при сборе датасета недопустимо нарушать пользовательскую приватность. Во-вторых, ИИ должен угадывать и учитывать степень опытности пользователя и, соответственно, качество поступающих от него данных. Для программирования интерфейсов с учётом всех этих нюансов, по-видимому, понадобятся новые структуры данных.
Полная интеграция моделей машинного обучения с кодом приложения потенциально осуществима, если активизируется развитие языков вероятностного программирования. Но, возможно, полностью переписывать приложение на вероятностном языке просто для улучшения юзабилити было бы перебором. Обмен информацией между клиентом и сервером, функции календаря, геолокации и многие другие не содержат вероятностной составляющей. Тем не менее, в настоящее время для взаимодействия приложения с ИИ требуется писать DSL, которые выражали бы недетерминированный выбор (скажем, предлагали список из N наиболее вероятных вариантов, исходя из контекста), а также позволяли уточнять неоднозначный выбор, сделанный пользователем. Здесь пригодились бы такие структуры данных как «гипотеза», «изменение», «следствие», «решение». Возможно, реализация таких структур данных принесла бы и фундаментальную пользу, приблизив нас к алгоритмизации эвереттовской многомировой модели квантовой механики.
Вероятные сценарии дальнейшего взаимодействия с интерфейсом должны разыгрываться в изолированных средах, при одновременном выполнении реального, «основного» сценария, а затем сливаться с ним по принципу merge. С алгоритмической точки зрения такая задача сейчас также вполне решаемая, но, вероятно, слишком сложна для мобильного устройства с точки зрения требуемых вычислительных мощностей.
Заключение
Вероятно, когда технология создания пользовательских интерфейсов будет полностью разработана (можно считать библиотеку pix2code доказательством осуществимости, proof-of-concept такой технологии), в основу ее лягут распознавание и аннотирование образов, обучение с подкреплением и многомировая интерпретация user experience. Практическая польза от такой технологии была бы огромна. Мощный искусственный интеллект, получивший на вход фотографию потенциального UI, либо, тем более, его детальную каркасную модель, мог бы компоновать макет интерфейса, закладывать шаблонный код для его конкретных реализаций, а также предусматривать расширяемость и сразу исключать целые классы пользовательских ошибок. После непродолжительного использования устройства его интерфейс вполне мог бы сам подстроиться под владельца. Упростилось бы не только тестирование интерфейсов, но и разбор ошибок (постмортемы), а программист был бы избавлен от выполнения множества рутинных задач. Мне же сложно представить общую картину (кроме повышения юзабилити мобильных устройств), к которой могут привести нас упомянутые тренды, поэтому приглашаю обсудить её в комментариях.


