
Об игре Montezuma’s Revenge на Хабре писали не так, чтобы очень много. Это сложная классическая игра, которая ранее была очень популярна, но сейчас в нее играют либо те, у кого она вызывает ностальгические чувства, либо же исследователи, разрабатывающие ИИ.
Летом этого года появилась информация о том, что компания DeepMind смогла научить свой ИИ проходить игры для Atari, включая Montezuma’s Revenge. На примере этой же игры обучали свою разработку и создатели OpenAI. Сейчас аналогичным проектом занялась компания Uber.
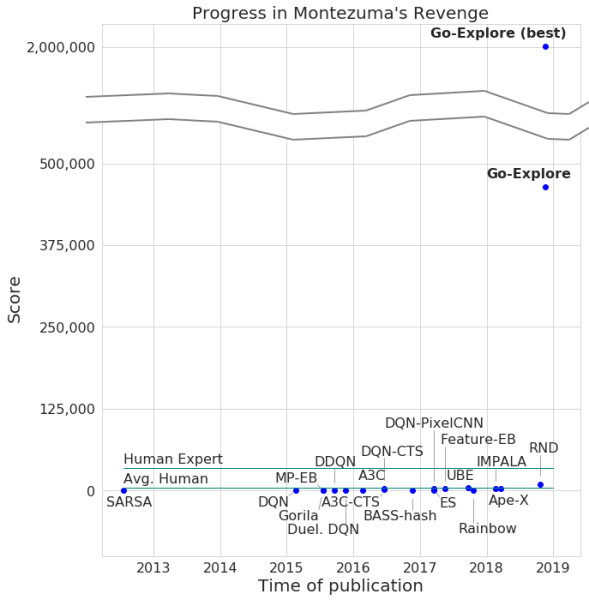
Разработчики заявили о прохождении игры их нейросетью, с достижением максимального количества очков в 2 млн. Правда, в среднем система зарабатывала не более 400 000 для каждой попытки. Что касается прохождения, то компьютер добрался до 159 уровня.
Кроме того, Go-Explore научился проходить и Pitfall, причем с отличным результатом, который превосходит результат среднего геймера, не говоря уже о других ИИ-агентах. Количество очков, набранных Go-Explore в этой игре, составляет 21000.
Отличием Go-Explore от «коллег» является то, что нейросети не нужно демонстрировать прохождение разных уровней для обучения. Система учится всему сама в процессе игры, показывая результаты, гораздо выше тех, что демонстрируют нейросети, которым требуется визуальное обучение. По словам разработчиков Go-Explore, технология значительно отличается от всех прочих, а ее возможности позволяют использовать нейросеть в ряде сфер, включая робототехнику.
Большинству алгоритмов сложно справиться с Montezuma’s Revenge потому, что в игре не слишком явная обратная связь. К примеру, нейросеть, которая «заточена» на получение награды в процессе прохождения уровня, скорее будет сражаться с врагом, чем запрыгнет на лестницу, которая ведет к выходу и позволяет быстрее идти вперед. Прочие ИИ-системы предпочитают получить награду здесь и сейчас, а не идти вперед в «надежде» на большее.
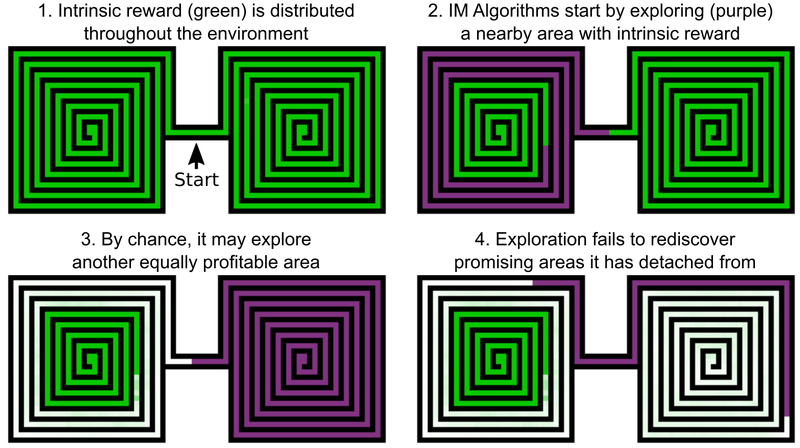
Одно из решений инженеров Uber — добавление бонусов за изучение игрового мира, это можно назвать внутренней мотивацией ИИ. Но даже ИИ-элементы с добавленной внутренней мотивацией не слишком хорошо справляются с Montezuma’s Revenge и Pitfall. Проблема в том, что ИИ «забывает» о перспективных локациях после их прохождения. В итоге ИИ-агент застревает на уровне, где уже вроде бы все исследовано.
В качестве примера можно привести ИИ-агента, которому необходимо изучить два лабиринта — восточный и западный. Он начинает проходить один из них, но затем внезапно решает, что можно было бы пройти и второй. Первый остается изученным на 50%, второй — на 100%. И в первый лабиринт агент не возвращается — просто потому, что «забыл» о том, что он не пройден до конца. А поскольку проход между восточным и западным лабиринтом уже изучен, у ИИ нет мотивации возвращаться.
Решение этой проблемы, по мнению разработчиков из Uber, включает два этапа: исследование и усиление. Что касается первой части, то здесь ИИ создает архив различных игровых состояний — клеток (cells) — и различных траекторий, которые к ним приводят. ИИ выбирает возможность получить максимальное количество очков при обнаружении оптимальной траектории.
Клетки представляют собой упрощенные игровые кадры — 11 по 8 изображений в оттенках серого с 8-ми пиксельной интенсивностью, с кадрами, которые различаются в достаточной степени — для того, чтобы не препятствовать дальнейшему прохождению игры.

В результате ИИ запоминает перспективные локации и возвращается в них после обследования других частей игрового мира. «Желание» исследовать игровой мир и перспективные локации у Go-Explore сильнее, чем стремление получить награду здесь и сейчас. Go-Explore также использует информацию о клетках, в которых обучается ИИ-агент. Для Montezuma’s Revenge это данные о пикселях вроде их X и Y координат, текущей комнаты, а также количества найденных ключей.
Этап усиления работает в качестве защиты от «шума». Если решения ИИ неустойчивы к «шуму», то ИИ усиливает их при помощи многоуровневой нейронной сети, работающей по примеру нейронов мозга человека.

В тестах Go-Explore показывает себя очень хорошо — в среднем ИИ изучает 37 комнат и решает 65% головоломок первого уровня. Это гораздо лучше, чем предыдущие попытки покорить игру — тогда ИИ в среднем изучал 22 комнаты первого уровня.

При добавлении усиления к существующему алгоритму ИИ стал в среднем успешно проходить 29 уровней (не комнат) со средним числом очков в 469,209.
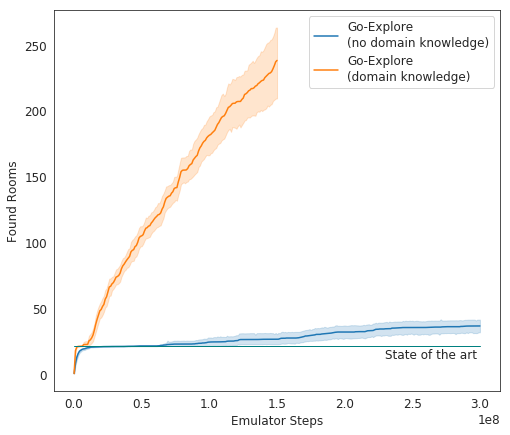
Итоговая инкарнация ИИ от Uber стала проходить игру гораздо лучше, чем другие ИИ-агенты, и лучше, чем люди. Сейчас разработчики совершенствуют свою систему с тем, чтобы она показала еще более впечатляющий результат.
Источник


