
Алексей Акулович (AterCattus) бэкенд-разработчик в команде ВКонтакте. Расшифровка этого доклада — собирательный ответ на часто задаваемые вопросы про работу платформы, инфраструктуры, серверов и взаимодействия между ними, но не про разработку, а именно про железо. Отдельно — про базы данных и то, что вместо них у ВК, про сбор логов и мониторинг всего проекта в целом. Подробности под катом.
Больше четырех лет я занимаюсь всевозможными задачами, связанными с бэкендом.
- Загрузка, хранение, обработка, раздача медиа: видео, live стриминг, аудио, фото, документы.
- Инфраструктура, платформа, мониторинг со стороны разработчика, логи, региональные кэши, CDN, собственный протокол RPC.
- Интеграция с внешними сервисами: рассылки пушей, парсинг внешних ссылок, лента RSS.
- Помощь коллегам по разным вопросам, за ответами на которые приходится погружаться в неизвестный код.
За это время я приложил руку к многим компонентам сайта. Этим опытом и хочу поделиться.
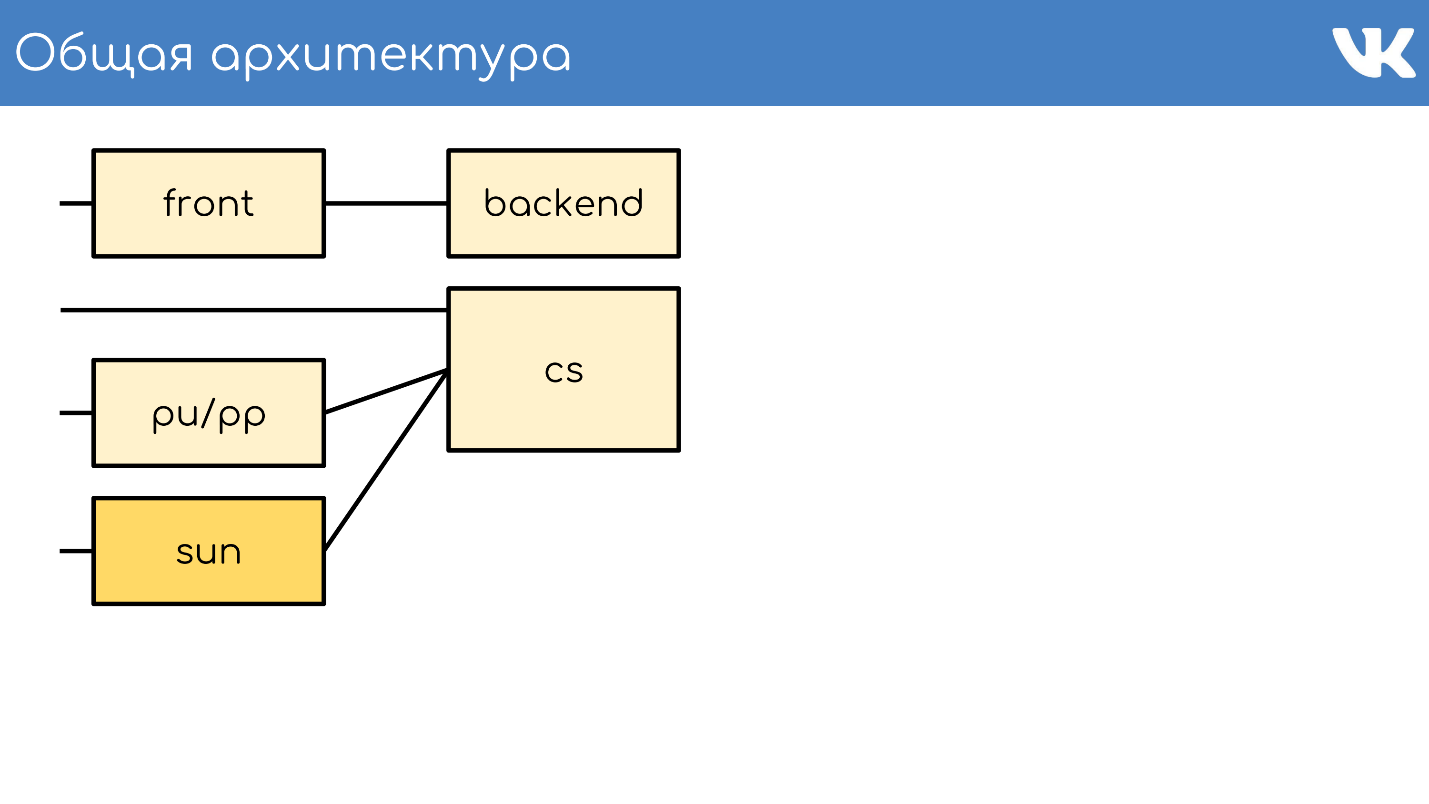
Общая архитектура
Все, как обычно, начинается с сервера или группы серверов, которые принимают запросы.
Front-сервер
Front-сервер принимает запросы по HTTPS, RTMP и WSS.
HTTPS — это запросы для основной и мобильной веб-версий сайта: vk.com и m.vk.com, и другие официальные и неофициальные клиенты нашего API: мобильные клиенты, мэссенджеры. У нас есть прием RTMP-трафика для Live-трансляций с отдельными front-серверами и WSS-соединения для Streaming API.
Для HTTPS и WSS на серверах стоит nginx. Для RTMP трансляций мы недавно перешли на собственное решение kive, но оно за пределами доклада. Эти серверы для отказоустойчивости анонсируют общие IP-адреса и выступают группами, чтобы в случае проблемы на одном из серверов, запросы пользователей не терялись. Для HTTPS и WSS эти же серверы занимаются шифровкой трафика, чтобы забирать часть нагрузки по CPU на себя.
Дальше не будем говорить про WSS и RTMP, а только про стандартные запросы HTTPS, которые обычно ассоциируются с веб-проектом.
Backend
За front обычно стоят backend-серверы. Они обрабатывают запросы, которые получает front-сервер от клиентов.
Это kPHP-серверы, на которых работает HTTP-демон, потому что HTTPS уже расшифрован. kPHP — это сервер, который работает по prefork-модели: запускает мастер-процесс, пачку дочерних процессов, передает им слушающие сокеты и они обрабатывают свои запросы. При этом процессы не перезапускаются между каждым запросом от пользователя, а просто сбрасывают свое состояние в первоначальное zero-value состояние — запрос за запросом, вместо перезапуска.
Распределение нагрузки
Все наши бэкенды — это не огромный пул машин, которые могут обработать любой запрос. Мы их разделяем на отдельные группы: general, mobile, api, video, staging… Проблема на отдельной группе машин, не повлияет на все остальные. В случае проблем с видео пользователь, который слушает музыку, даже не узнает о проблемах. На какой backend отправить запрос, решает nginx на front’е по конфигу.
Сбор метрик и перебалансировка
Чтобы понять, сколько машин нужно иметь в каждой группе, мы не опираемся на QPS. Бэкенды разные, у них разные запросы, у каждого запроса разная сложность вычисления QPS. Поэтому мы оперируем понятием нагрузки на сервер в целом — на CPU и perf.
Таких серверов у нас тысячи. На каждом физическом сервере запущена группа kPHP, чтобы утилизировать все ядра (потому что kPHP однопоточные).
Content Server
CS или Content Server — это хранилище. CS — это сервер, который хранит файлы, а также обрабатывает залитые файлы, всевозможные фоновые синхронные задачи, которые ему ставит основной веб-фронтенд.
У нас десятки тысяч физических серверов, которые хранят файлы. Пользователи любят загружать файлы, а мы любим их хранить и раздавать. Часть этих серверов закрыты специальными pu/pp серверами.
pu/pp
Если вы открывали в VK вкладку network, то видели pu/pp.

Что такое pu/pp? Если мы закрываем один сервер за другой, то есть два варианта отдачи и загрузки файла на сервер, который был закрыт: напрямую через http://cs100500.userapi.com/path или через промежуточный сервер — http://pu.vk.com/c100500/path.
Pu — это исторически сложившееся название для photo upload, а pp — это photo proxy. То есть один сервер, чтобы загружать фото, а другой — отдавать. Теперь загружаются уже не только фотографии, но название сохранилось.
Эти серверы терминируют HTTPS-сессии, чтобы снять процессорную нагрузку с хранилища. Также, так как на этих серверах обрабатываются пользовательские файлы, то чем меньше чувствительной информации хранится на этих машинах, тем лучше. Например, ключи от шифрования HTTPS.
Так как машины закрыты другими нашими машинами, то мы можем позволить себе не давать им «белые» внешние IP, и даем «серые». Так сэкономили на пуле IP и гарантированно защитили машины от доступа извне — просто нет IP, чтобы на неё попасть.
Отказоустойчивость через общие IP. В плане отказоустойчивости схема работает так же — несколько физических серверов имеют общий физический IP, и железка перед ними выбирает, куда отправить запрос. Позже я расскажу о других вариантах.
Спорный момент в том, что в этом случае клиент держит меньше соединений. При наличии одинакового IP на несколько машин — с одинаковым их хостом: pu.vk.com или pp.vk.com, браузер клиента имеет ограничение на количество одновременных запросов к одному хосту. Но во время повсеместного HTTP/2, я считаю, что это уже не так актуально.
Явный минус схемы в том, что приходится прокачивать весь трафик, который идет в хранилище, через еще один сервер. Так как мы прокачиваем трафик через машины, то пока не можем прокачивать по такой же схеме тяжелый трафик, например, видео. Его мы его передаем напрямую — отдельное прямое соединение для отдельных хранилищ именно для видео. Более легкий контент мы передаем через proxy.
Не так давно у нас появилась улучшенная версия proxy. Сейчас расскажу, чем они отличаются от обычных и зачем это нужно.
Sun
В сентябре 2017 компания Oracle, которая до этого купила компанию Sun, уволила огромное количество сотрудников Sun. Можно сказать, что в этот момент компания прекратила свое существование. Выбирая название для новой системы, наши админы решили отдать дань уважения и памяти этой компании, и назвали новую систему Sun. Между собой мы называем ее просто «солнышки».
У pp было несколько проблем. Один IP на группу — неэффективный кэш. Несколько физических серверов имеют общий IP-адрес, и нет возможности контролировать, на какой сервер придет запрос. Поэтому если разные пользователи приходят за одним и тем же файлом, то при наличии кэша на этих серверах, файлик оседает в кэше каждого сервера. Это очень неэффективная схема, но ничего нельзя было сделать.
Как следствие — мы не можем шардировать контент, потому что не можем выбрать конкретный сервер этой группы — у них общий IP. Также по некоторым внутренним причинам у нас не было возможности ставить такие серверы в регионы. Они стояли только в Санкт-Петербурге.
С солнышками мы изменили систему выбора. Теперь у нас anycast маршрутизация: dynamic routing, anycast, self-check daemon. У каждого сервера свой собственный индивидуальный IP, но при этом общая подсеть. Все настроено так, что в случае выпадения одного сервера трафик размазывается по остальным серверам той же группы автоматически. Теперь есть возможность выбрать конкретный сервер, нет избыточного кэширования, и надежность не пострадала.
Поддержка весов. Теперь мы можем себе позволить ставить машины разной мощности по необходимости, а также в случае временных проблем менять веса работающим «солнышкам» для уменьшения нагрузки на них, чтобы они «отдохнули» и снова заработали.
Шардирование по id контента. Забавная вещь, связанная с шардированием: обычно мы шардируем контент так, что разные пользователи идут за одним файлом через одно «солнышко», чтобы у них был общий кэш.
Недавно мы запустили приложение “Клевер”. Это онлайн-викторина в live-трансляции, где ведущий задает вопросы, а пользователи отвечают в реальном времени, выбирая варианты. В приложении есть чат, где пользователи могут пофлудить. К трансляции одновременно могут подключаться больше 100 тысяч человек. Они все пишут сообщения, которые рассылаются всем участникам, вместе с сообщением приходит еще аватарка. Если 100 тысяч человек приходит за одной аватаркой в одно «солнышко», то оно может иногда закатиться за тучку.
Чтобы выдержать всплески запросов одного и того же файла, именно для некоторого вида контента у нас включается тупая схема, которая размазывает файлики по всем имеющимся «солнышкам» региона.
Sun изнутри
Реверс proxy на nginx, кэш либо в RAM, либо на быстрые диски Optane/NVMe. Пример: http://sun4-2.userapi.com/c100500/path — ссылка на «солнышко», которое стоит в четвертом регионе, второй сервер-группы. Он закрывает собой файл path, который физически лежит на сервере 100500.
Cache
В нашу архитектурную схему мы добавляем еще один узел — среду кэширования.

Ниже схема расположения региональных кэшей, их примерно 20 штук. Это места, где стоят именно кэши и «солнышки», которые могут кэшировать трафик через себя.

Это кэширование мультимедиа-контента, здесь не хранятся пользовательские данные — просто музыка, видео, фото.
Чтобы определить регион пользователя, мы собираем анонсированные в регионах BGP-префиксы сетей. В случае fallback у нас есть еще парсинг базы geoip, если мы не смогли найти IP по префиксам. По IP пользователя определяем регион. В коде мы можем посмотреть один или несколько регионов пользователя — те точки, к которым он ближе всего географически.
Как это работает?
Считаем популярность файлов по регионам. Есть номер регионального кэша, где находится пользователь, и идентификатор файла — берем эту пару и инкрементируем рейтинг при каждом скачивании.
При этом демоны — сервисы в регионах — время от времени приходят в API и говорят: «Я кэш такой-то, дай мне список самых популярных файлов моего региона, которых на мне еще нет». API отдает пачку файлов, отсортированных по рейтингу, демон их выкачивает, уносит в регионы и оттуда отдает файлы. Это принципиальное отличие pu/pp и Sun от кэшей: те отдают файл через себя сразу, даже если в кэше этого файла нет, а кэш сначала выкачивает файл на себя, а потом уже начинает его отдавать.
При этом мы получаем контент ближе к пользователям и размазывание сетевой нагрузки. Например, только с московского кэша мы раздаем больше 1 Тбит/с в часы наибольшей нагрузки.
Но есть проблемы — серверы кэшей не резиновые. Для суперпопулярного контента иногда не хватает сети на отдельный сервер. Серверы кэшей у нас 40-50 Гбит/с, но бывает контент, который забивает такой канал полностью. Мы идем к тому, чтобы реализовать хранение более одной копии популярных файлов в регионе. Надеюсь, что до конца года реализуем.
Мы рассмотрели общую архитектуру.
- Front-серверы, которые принимают запросы.
- Бэкенды, которые обрабатывают запросы.
- Хранилища, которые закрыты двумя видами proxy.
- Региональные кэши.
Чего в этой схеме не хватает? Конечно, баз данных, в которых мы храним данные.
Базы данных или движки
Мы называем их не базами, а движками — Engines, потому что баз данных в общепринятом смысле у нас практически нет.

Это вынужденная мера. Так получилось, потому что в 2008-2009 году, когда у VK был взрывной рост популярности, проект полностью работал на MySQL и Memcache и были проблемы. MySQL любил упасть и испортить файлы, после чего не поднимался, а Memcache постепенно деградировал по производительности, и приходилось его перезапускать.
Получается, что в набирающем популярность проекте было персистентное хранилище, которое портит данные, и кэш, который тормозит. В таких условиях развивать растущий проект тяжело. Было принято решение попробовать переписать критические вещи, в которые проект упирался, на собственные велосипеды.
Решение оказалось успешным. Возможность это сделать была, как и крайняя необходимость, потому что других способов масштабирования в то время не существовало. Не было кучи баз, NoSQL еще не существовал, были только MySQL, Memcache, PostrgreSQL — и все.
Универсальная эксплуатация. Разработку вела наша команда C-разработчиков и все было сделано единообразно. Независимо от движка, везде был примерно одинаковый формат файлов, записываемых на диск, одинаковые параметры запуска, одинаково обрабатывались сигналы и примерно одинаково вели себя в случае краевых ситуаций и проблем. С ростом движков админам удобно эксплуатировать систему — нет зоопарка, который надо поддерживать, и заново учиться эксплуатировать каждую новую стороннюю базу, что позволяло быстро и удобно наращивать их количество.
Типы движков
Команда написала довольно много движков. Вот лишь часть из них: friend, hints, image, ipdb, letters, lists, logs, memcached, meowdb, news, nostradamus, photo, playlists, pmemcached, sandbox, search, storage, likes, tasks, …
Под каждую задачу, которая требует специфическую структуру данных или обрабатывает нетипичные запросы, C-команда пишет новый движок. Почему бы и нет.
У нас есть отдельный движок memcached, который похож на обычный, но с кучей плюшек, и который не тормозит. Не ClickHouse, но тоже работает. Есть отдельно pmemcached — это персистентный memcached, который умеет хранить данные еще и на диске, причем больше, чем влезает в оперативную память, чтобы не терять данные при перезапуске. Есть разнообразные движки под отдельные задачи: очереди, списки, сеты — все, что требуется нашему проекту.
Кластеры
С точки зрения кода нет необходимости представлять себе движки или базы данных как некие процессы, сущности или инстанции. Код работает именно с кластерами, с группами движков — один тип на кластер. Допустим, есть кластер memcached — это просто группа машин.
Коду вообще не нужно знать физическое расположение, размер и количество серверов. Он ходит в кластер по некому идентификатору.
Чтобы это работало, требуется добавить еще одну сущность, которая находится между кодом и движками — proxy.
RPC-proxy
Proxy — связующая шина, на которой работает практически весь сайт. При этом у нас нет service discovery — вместо него есть конфиг этого proxy, который знает расположение всех кластеров и всех шардов этого кластера. Этим занимаются админы.
Программистам вообще не важно, сколько, где и что стоит — они просто ходят в кластер. Это нам многое позволяет. При получении запроса proxy перенаправляет запрос, зная куда — он сам это определяет.

При этом proxy — точка защиты от отказа сервиса. Если какой-то движок тормозит или упал, то proxy это понимает и соответствующе отвечает клиентской стороне. Это позволяет снять таймаут — код не ждет ответа движка, а понимает, что он не работает и надо как-то по-другому себя вести. Код должен быть готов к тому, что базы не всегда работают.
Специфичные реализации
Иногда мы все-таки очень хотим иметь какое-то нестандартное решение в качестве движка. При этом было принято решение, не использовать наш готовый rpc-proxy, созданный именно для наших движков, а сделать отдельный proxy под задачу.
Для MySQL, который у нас еще кое-где есть используем db-proxy, а для ClickHouse — Kittenhouse.
Это работает в целом так. Есть некий сервер, на нем работает kPHP, Go, Python — вообще любой код, который умеет ходить по нашему RPC-протоколу. Код ходит локально на RPC-proxy — на каждом сервере, где есть код, запущен свой локальный proxy. По запросу proxy понимает куда нужно идти.
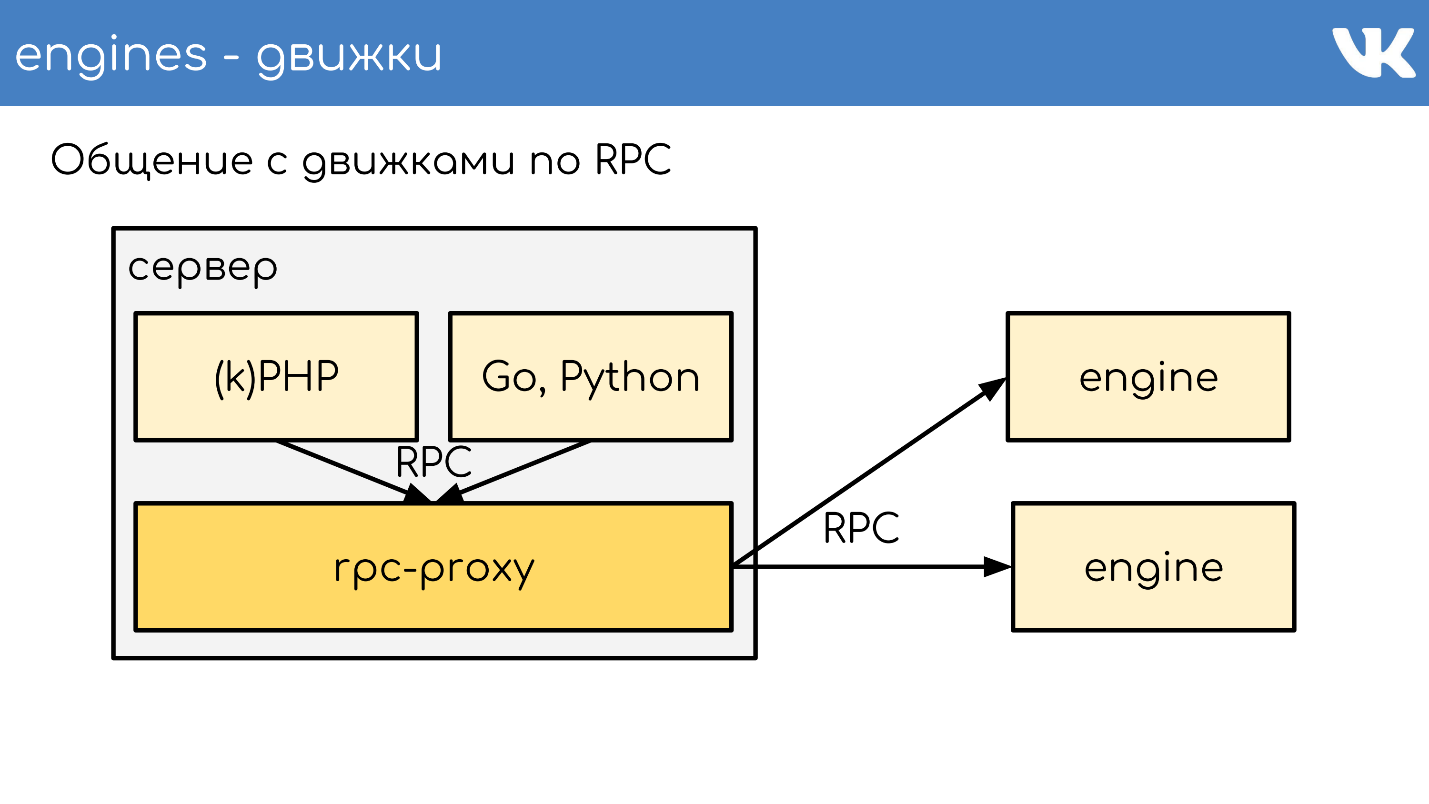
Если один движок хочет пойти в другой, даже если это сосед, то идет через proxy, потому что сосед может стоять в другом дата-центре. Движок не должен завязываться на знание расположения чего-либо, кроме самого себя — у нас это стандартное решение. Но исключения, конечно, бывают 🙂
Пример TL-схемы, по которой работают все движки.
memcache.not_found = memcache.Value; memcache.strvalue value:string flags:int = memcache.Value; memcache.addOrIncr key:string flags:int delay:int value:long = memcache.Value; tasks.task fields_mask:# flags:int tag:%(Vector int) data:string id:fields_mask.0?long retries:fields_mask.1?int scheduled_time:fields_mask.2?int deadline:fields_mask.3?int = tasks.Task; tasks.addTask type_name:string queue_id:%(Vector int) task:%tasks.Task = Long;Это бинарный протокол, ближайший аналог которого protobuf. В схеме заранее описаны опциональные поля, сложные типы — расширения встроенных скаляров, и запросы. Все работает по этому протоколу.
RPC over TL over TCP/UDP… UDP?
У нас есть RPC-протокол выполнения запросов движка, который работает поверх TL-схемы. Это все работает поверх TCP/UDP соединения. TCP — понятно, а зачем нам UDP часто спрашивают.
UDP помогает избежать проблемы огромного количества соединений между серверами. Если на каждом сервере стоит RPC-proxy и он, в общем случае, может пойти в любой движок, то получается десятки тысяч TCP-соединений на сервер. Нагрузка есть, но она бесполезна. В случае UDP этой проблемы нет.
Heт избыточного TCP-handshake. Это типичная проблема: когда поднимается новый движок или новый сервер, устанавливается сразу много TCP-соединений. Для маленьких легковесных запросов, например, UDP payload, все общение кода с движком — это два UDP-пакета: один летит в одну сторону, второй в другую. Один round trip — и код получил ответ от движка без handshake.
Да, это все работает только при очень небольшом проценте потерь пакетов. В протоколе есть поддержка для ретрансмиттов, таймаутов, но если мы будем терять много, то получим практически TCP, что не выгодно. Через океаны UDP не гоняем.
Таких серверов у нас тысячи, и там та же самая схема: на каждый физический сервер ставится пачка движков . В основном они однопоточные, чтобы работать максимально быстро без блокировок, и шардируются как однопоточные решения. При этом у нас нет ничего более надежного, чем эти движки, и персистентному хранению данных уделяется очень большое внимание.
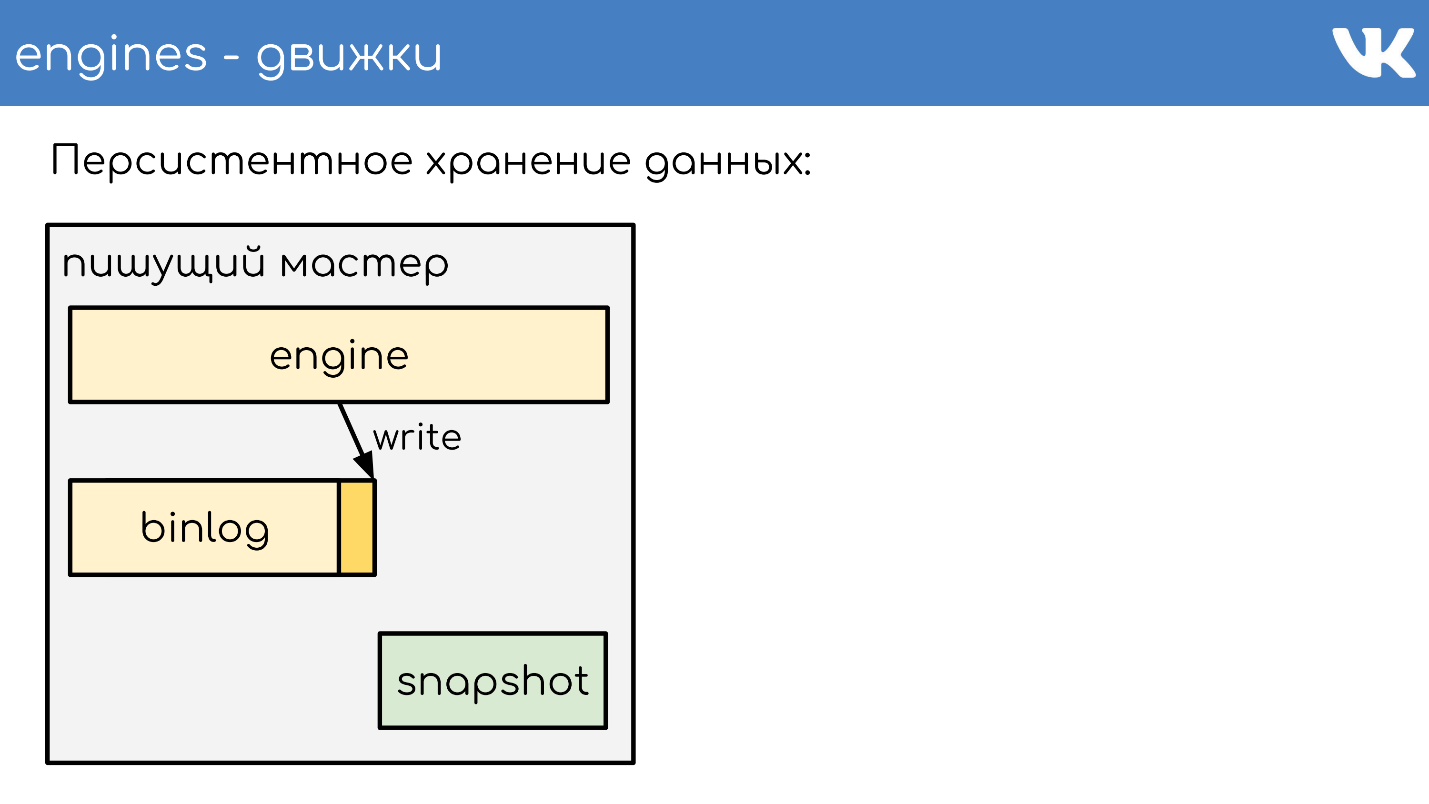
Персистентное хранение данных
Движки пишут бинлоги. Бинлог — это файлик, в конце которого дописывается событие на изменение состояния или данных. В разных решениях называется по-разному: binary log, WAL, AOF, но принцип один.
Чтобы движок при перезапуске не перечитывал весь бинлог за много лет, движки пишут снапшоты — состояние на текущий момент. При необходимости они читают сначала из него, а потом дочитывают уже из бинлога. Все бинлоги пишутся в одинаковом бинарном формате — по TL-схеме, чтобы админы могли их своими инструментами одинаково администрировать. Для снапшотов такой необходимости нет. Там есть общий заголовок, который указывает чей снапшот — int, magic движка, а какое тело — никому не важно. Это проблема движка, который записал снапшот.
Бегло опишу принцип работы. Есть сервер, на котором работает движок. Он открывает на запись новый пустой бинлог, пишет в него событие на изменение.

В какой-то момент он либо сам решает сделать снапшот, либо ему приходит сигнал. Сервер создает новый файл, полностью записывает в него свое состояние, дописывает текущий размер бинлога — offset на конец файла, и продолжает писать дальше. Новый бинлог не создается.
В какой-то момент, когда движок перезапустился, на диске будет и бинлог и снапшот. Движок читает полностью снапшот, поднимает свое состояние на определенный момент.

Вычитывает позицию, которая была на момент создания снапшота, и размер бинлога.
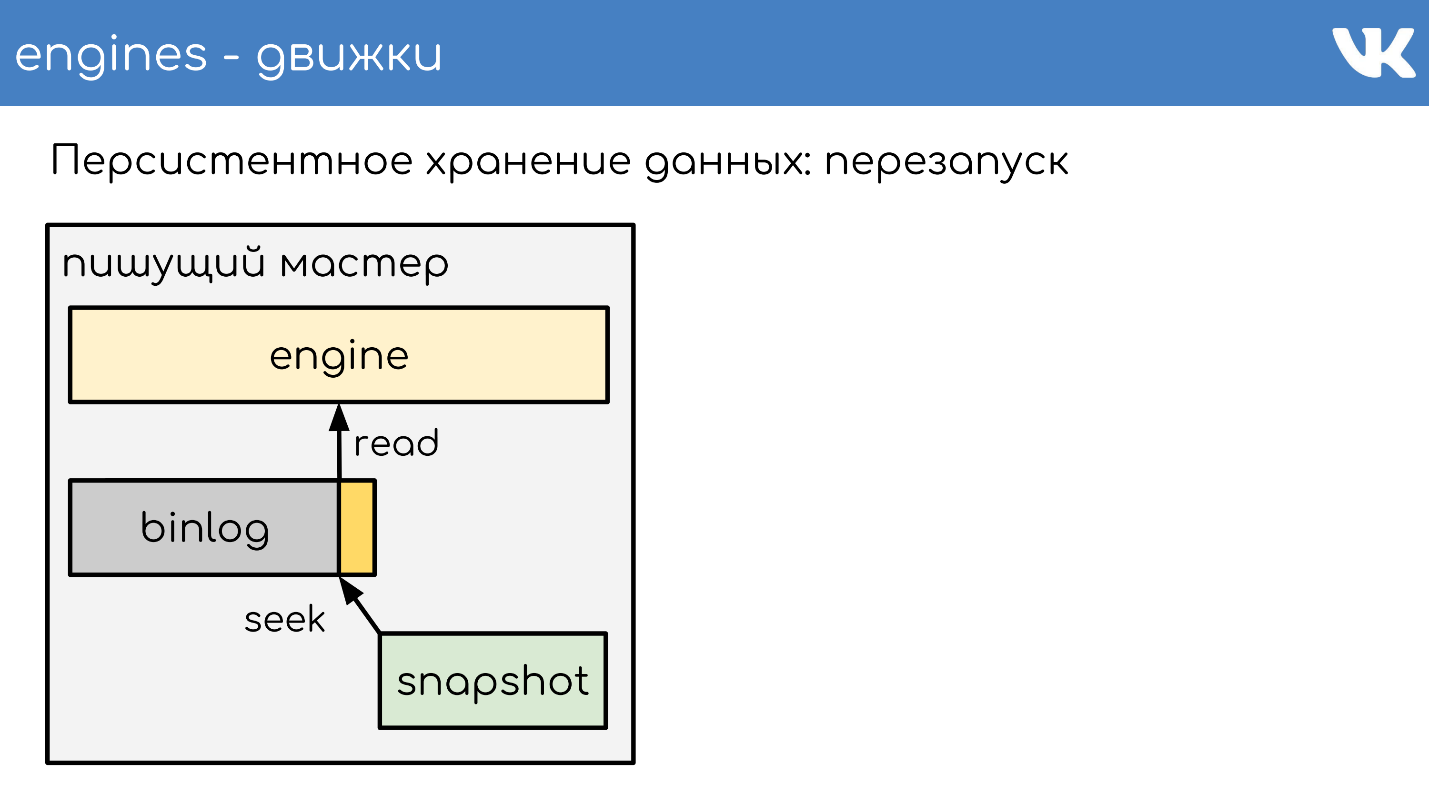
Дочитывает конец бинлога для получения текущего состояния и продолжает писать дальше события. Это простая схема, все наши движки работают по ней.
Репликация данных
В результате репликация данных у нас statement-based — мы пишем в бинлог не какие-нибудь изменения страниц, а именно запросы на изменения. Очень похоже на то, что приходит по сети, только чуть измененное.
Эта же схема используется не просто для репликации, но еще и для создания бэкапов. У нас есть движок — пишущий мастер, который пишет в бинлог. В каком угодно другом месте, куда настроят админы, поднимается копирование этого бинлога, и все — у нас есть бэкап.

Если нужна читающая реплика, чтобы снизить нагрузку на чтение по CPU — просто поднимается читающий движок, который дочитывает конец бинлога и выполняет эти команды в себе локально.
Отставание здесь очень маленькое, и есть возможность узнать, насколько реплика отстает от мастера.
Шардирование данных в RPC-proxy
Как работает шардирование? Как proxy понимает, на какой шард кластера отправить? Код не сообщает : «Отправь на 15 шард!» — нет, это делает proxy.
Самая простая схема — firstint — первое число в запросе.
get(photo100_500) => 100 % N.
Это пример для простого memcached текстового протокола, но, конечно, запросы бывают сложные, структурированные. В примере берется первое число в запросе и остаток от деления на размер кластера.
Это полезно, когда мы хотим иметь локальность данных одной сущности. Допустим, 100 — юзер или ID группы, и мы хотим, чтобы для сложных запросов все данные одной сущности были на одном шарде.
Если нам все равно, как запросы размазаны по кластеру, есть другой вариант — хеширование шарда целиком.
hash(photo100_500) => 3539886280 % N
Также получаем хеш, остаток от деления и номер шарда.
Оба этих варианта работают только если мы готовы к тому, что при наращивании размера кластера мы будем дробить или увеличивать его в кратное количество раз. Например, у нас было 16 шардов, нам не хватает, хотим больше — можно безболезненно получить 32 без даунтайма. Если хотим наращивать не кратно — будет даунтайм, потому что не получится аккуратно передробить все без потерь. Эти варианты полезны, но не всегда.
Если нам нужно добавлять или убирать произвольное количество серверов, используется консистентное хеширование на кольце a la Ketama. Но при этом мы полностью теряем локальность данных, приходится делать merge запроса на кластер, чтобы каждый кусочек вернул свой маленький ответ, и уже объединять ответы на proxy.
Есть супер-специфические запросы. Это выглядит так: RPC-proxy получает запрос, определяет, в какой кластер пойти и определяет шард. Тогда есть либо пишущие мастеры, либо, если кластер имеет поддержку реплик, он отсылает в реплику по запросу. Этим всем занимается proxy.

Логи
Мы пишем логи несколькими способами. Самый очевидный и простой — пишем логи в memcache.
ring-buffer: prefix.idx = line
Есть префикс ключа — имя лога, строка, и есть размер этого лога — количество строчек. Берем случайное число от 0 до числа строк минус 1. Ключ в memcache — это префикс сконкатенированный с этим случайным числом. В значение сохраняем строчку лога и текущее время.
Когда необходимо прочитать логи, мы проводим Multi Get всех ключей, сортируем по времени, и таким образом получаем продакшн лог в реальном времени. Схема применяется, когда нужно что-то продебажить в продакшн в реальном времени, ничего не ломая, не останавливая и не пуская трафик на другие машины, но этот лог не живет долго.
Для надежного хранения логов у нас есть движок logs-engine. Именно для этого он и создавался, и широко используется в огромном количестве кластеров. Самый большой известный мне кластер хранит 600 Тбайт запакованных логов.
Движок очень старый, есть кластеры, которым уже по 6–7 лет. С ним есть проблемы, которые мы пытаемся решить, например, начали активно использовать ClickHouse для хранения логов.
Сбор логов в ClickHouse
Эта схема показывает, как мы ходим в наши движки.

Есть код, который по RPC локально ходит в RPC-proxy, а тот понимает, куда пойти в движок. Если мы хотим писать логи в ClickHouse, нам нужно в этой схеме поменять две части:
- заменить какой-то движок на ClickHouse;
- заменить RPC-proxy, который не умеет ходить в ClickHouse, на какое-то решение, которое умеет, причем по RPC.
С движком просто — заменяем его на сервер или на кластер серверов с ClickHouse.
А чтобы ходить в ClickHouse, мы сделали KittenHouse. Если мы пойдем напрямую из KittenHouse в ClickHouse — он не справится. Даже без запросов, от HTTP-соединений огромного количества машин он складывается. Чтобы схема работала, на сервере с ClickHouse поднимается локальный reverse proxy, который написан так, что выдерживает нужные объемы соединений. Также он может относительно надежно буферизировать данные в себе.

Иногда мы не хотим реализовывать RPC-схему в нестандартных решениях, например, в nginx. Поэтому в KittenHouse есть возможность получать логи по UDP.

Если отправитель и получатель логов работают на одной машине, то вероятность потерять UDP-пакет в пределах локального хоста довольно низкая. Как некий компромисс между необходимостью реализовать RPC в стороннем решении и надежностью, мы используем просто отправку по UDP. К этой схеме мы еще вернемся.
Мониторинг
У нас два вида логов: те, которые собирают администраторы по своим серверам и те, которые пишут разработчики из кода. Им соответствуют два типа метрик: системные и продуктовые.
Системные метрики
На всех серверах у нас работает Netdata, которая собирает статистику и отсылает ее в Graphite Carbon. Поэтому как система хранения используется ClickHouse, а не Whisper, например. При необходимости можно напрямую читать из ClickHouse, или использовать Grafana для метрик, графиков и отчетов. Как разработчикам, доступа к Netdata и Grafana нам хватает.
Продуктовые метрики
Для удобства мы написали много всего. Например, есть набор обычных функций, которые позволяют записать Counts, UniqueCounts значения в статистику, которые отсылаются куда-то дальше.
statlogsCountEvent ( ‘stat_name’, $key1, $key2, …) statlogsUniqueCount ( ‘stat_name’, $uid, $key1, $key2, …) statlogsValuetEvent ( ‘stat_name’, $value, $key1, $key2, …) $stats = statlogsStatData($params) Впоследствии мы можем использовать фильтры сортировки, группировки и сделать все, что хотим от статистики — построить графики, настроить Watсhdogs.
Мы пишем очень много метрик, количество событий от 600 миллиардов до 1 триллиона в сутки. При этом мы хотим хранить их хотя бы пару лет, чтобы понимать тенденции изменения метрик. Склеить это все воедино — большая проблема, которую мы еще не решили. Расскажу, как это работает последние несколько лет.
У нас есть функции, которые пишут эти метрики в локальный memcache, чтобы уменьшить количество записей. Один раз в небольшой промежуток времени локально запущенный stats-daemon собирает все записи. Дальше демон сливает метрики в два слоя серверов logs-collectors, которые агрегирует статистику с кучи наших машин, чтобы слой за ними не умирал.

По необходимости мы можем писать напрямую в logs-collectors.
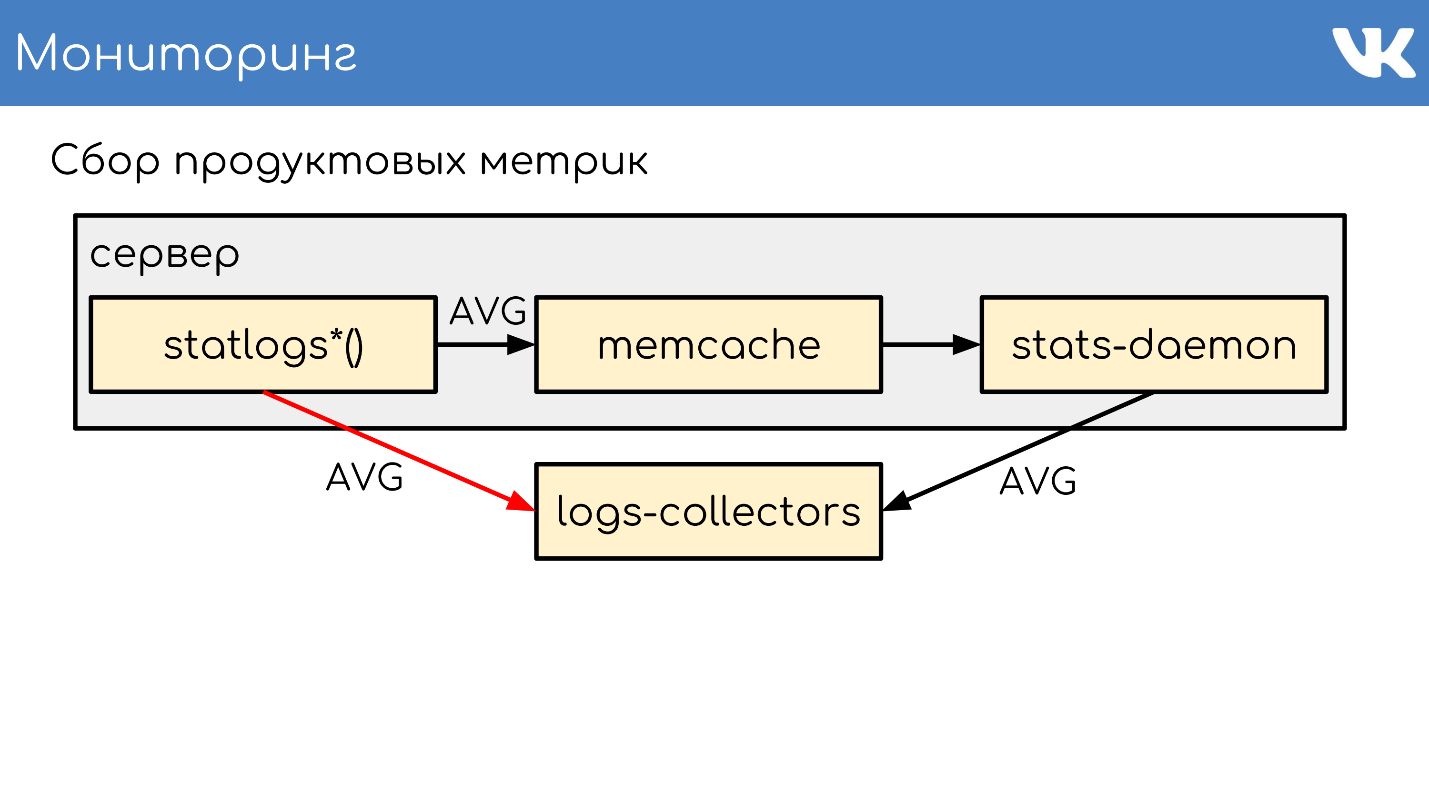
Но запись из кода напрямую в коллекторы в обход stas-daemom — плохо масштабируемое решение, потому что увеличивает нагрузку на collector. Решение подойдет, только если по какой-то причине на машине мы не можем поднять memcache stats-daemon, либо он упал, и мы пошли напрямую.
Дальше logs-collectors сливают статистику в meowDB — это наша база, которая еще и метрики умеет хранить.
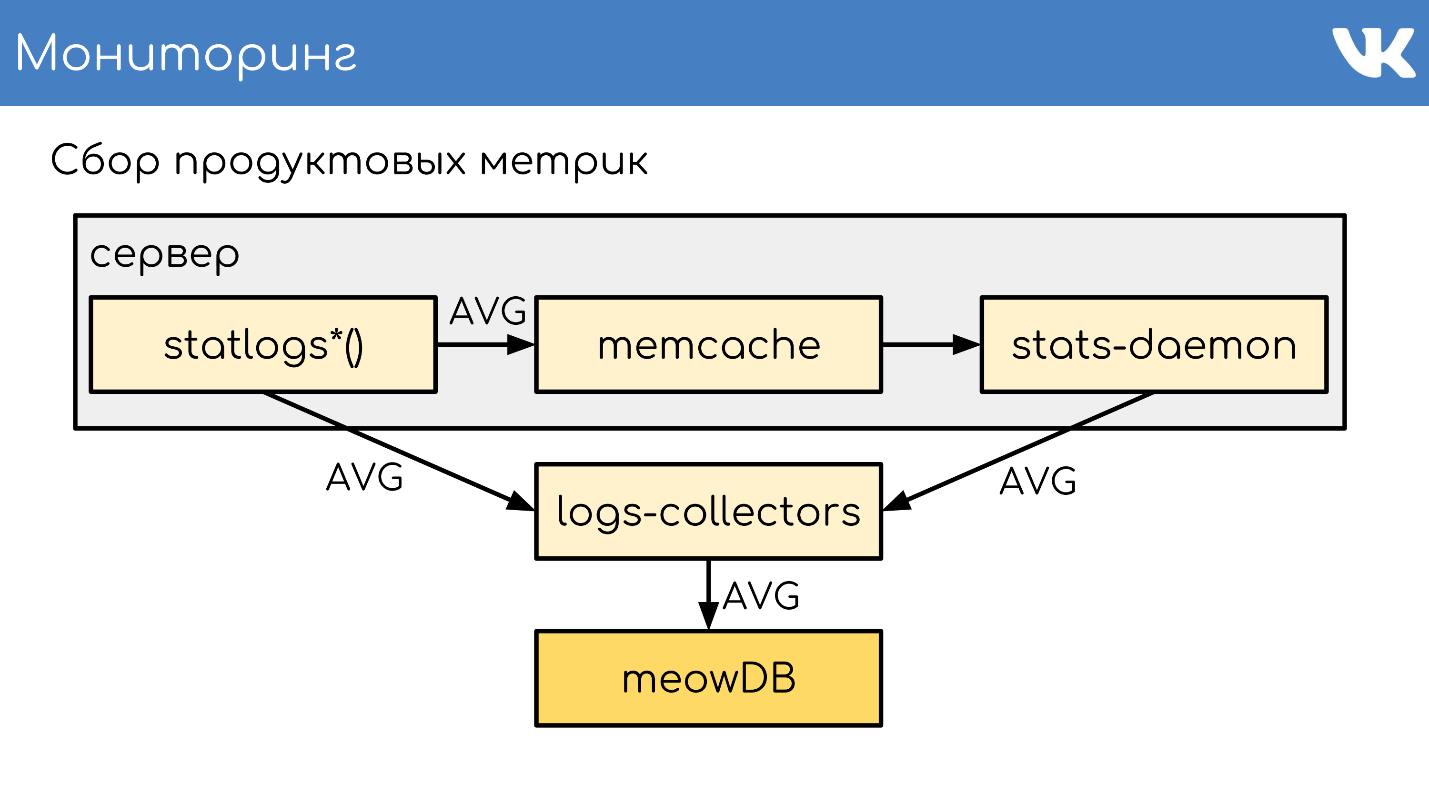
Потом из кода можем бинарным «около-SQL» производить выборки.

Эксперимент
Летом 2018 у нас был внутренний хакатон, и появилась идея попробовать заменить красную часть схемы на что-то, что может хранить метрики в ClickHouse. У нас есть логи на ClickHouse — почему бы не попробовать?

У нас была схема, которая писала логи через KittenHouse.
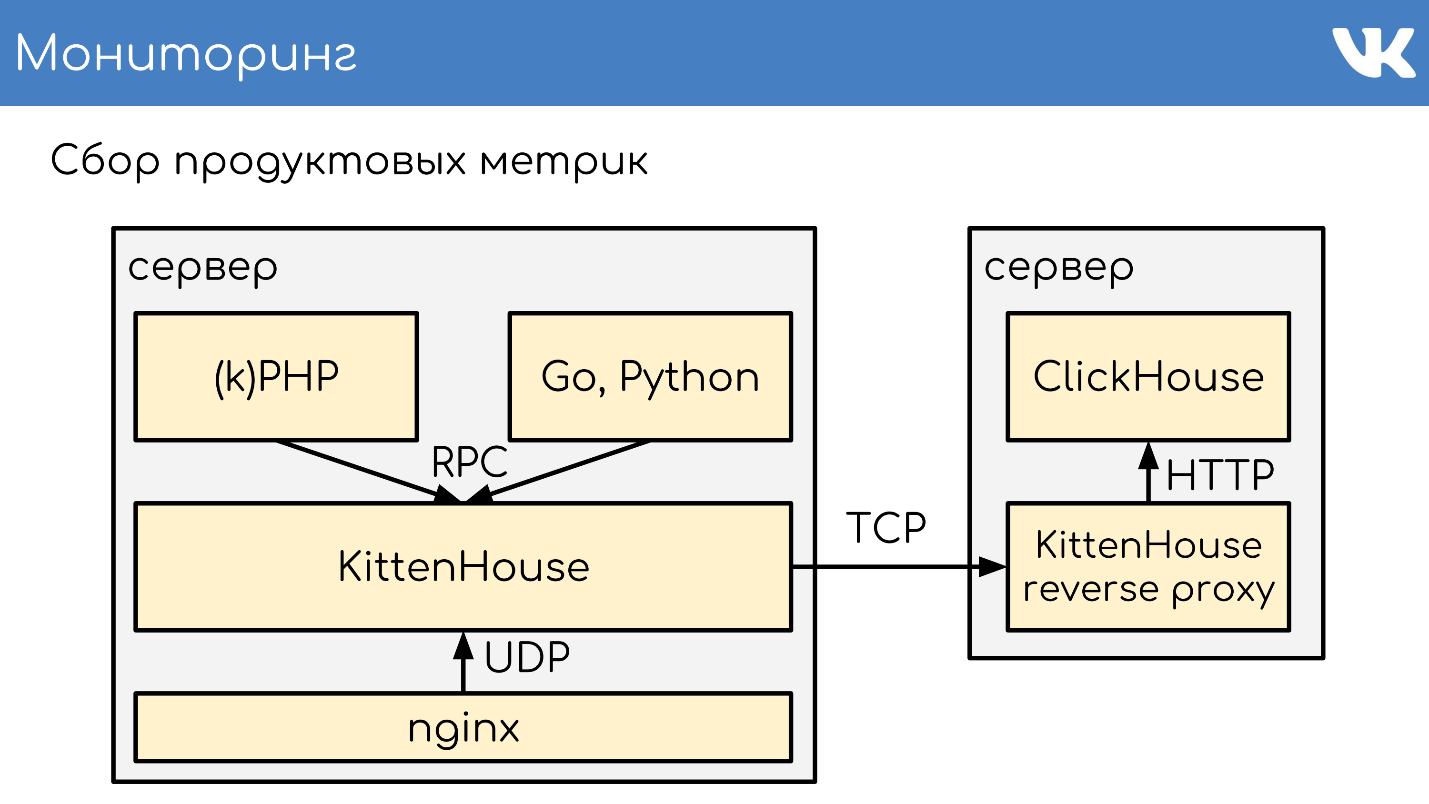
Мы решили добавить в схему еще один «*House», который будет принимать именно метрики в том формате, как их пишет наш код по UDP. Дальше этот *House превращает их в inserts, как логи, которые понимает KittenHouse. Эти логи он умеет прекрасно доставлять до ClickHouse, который должен их уметь читать.
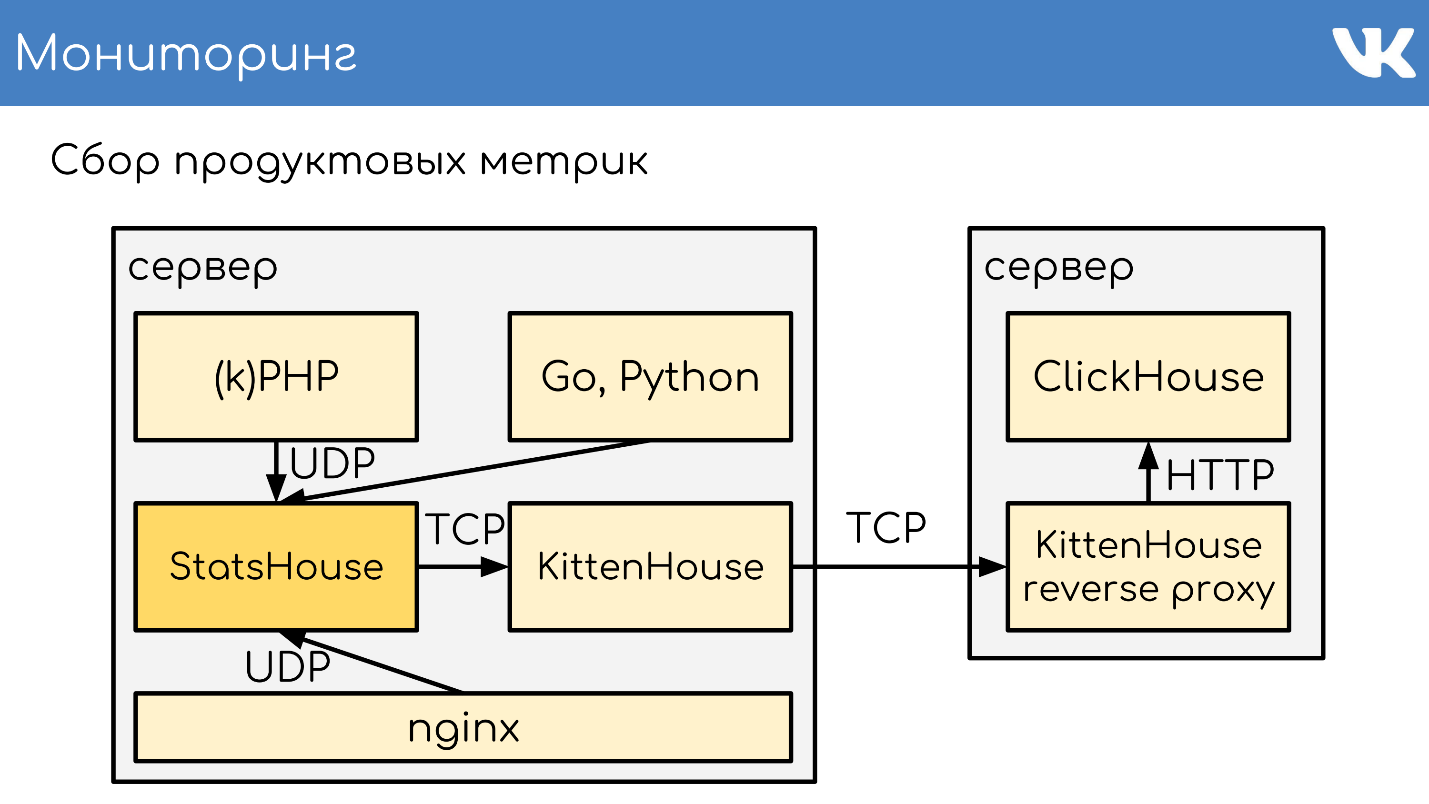
Схема с memcache, stats-daemon и logs-collectors базы заменяется на такую.

Схема с memcache, stats-daemon и logs-collectors базы заменяется на такую.
- Здесь есть отправка из кода, которая локально пишется в StatsHouse.
- StatsHouse пишет в KittenHouse UDP-метрики, уже превращенные в SQL-inserts, пачками.
- KittenHouse отсылает их в ClickHouse.
- Если мы хотим их прочитать, то читаем уже в обход StatsHouse — напрямую из ClickHouse обычными SQL.
Это все еще эксперимент, но нам нравится, что получается. Если исправим проблемы схемы, то, возможно, полностью перейдем на нее. Лично я на это надеюсь.
Схема не экономит железо. Нужно меньше серверов, не нужны локальные stats-daemons и logs-collectors, но ClickHouse требует сервера жирнее, чем те, что стоят на текущей схеме. Серверов нужно меньше, но они должны быть дороже и мощнее.
Деплой
Сначала посмотрим на деплой PHP. Разработку ведем в git: используем GitLab и TeamCity для деплоя. Ветки разработчиков вливаются в мастер-ветку, из мастера для тестирования вливаются в стейджинг, из стейджинга — в продакшн.
Перед деплоем берутся текущая ветка продакшна и предыдущая, в них считается diff файлов — изменение: создан, удален, изменен. Это изменение записывается в binlog специального движка copyfast, который может быстро реплицировать изменения на весь наш парк серверов. Здесь используется не копирование напрямую, а gossip replication, когда один сервер рассылает изменения ближайшим соседям, те — своим соседям, и так далее. Это позволяет обновлять код за десятки и единицы секунд на всем парке. Когда изменение доезжает до локальной реплики, она применяет эти патчи на своей локальной файловой системе. По этой же схеме производится и откат.
Мы также много деплоим kPHP и у него тоже есть собственная разработка на git по схеме выше. Так как это бинарник HTTP-сервера, то мы не можем производить diff — релизный бинарник весит сотни Мбайт. Поэтому здесь вариант другой — версия записывается в binlog copyfast. С каждым билдом она инкрементируется, и при откате она тоже увеличивается. Версия реплицируется на серверы. Локальные copyfast’ы видят, что в binlog попала новая версия, и тем же самым gossip replication забирают себе свежую версию бинарника, не утомляя наш мастер-сервер, а аккуратно размазывая нагрузку по сети. Дальше следует graceful перезапуск на новую версию.
Для наших движков, которые тоже по сути бинарники, схема очень похожа:
- git master branch;
- бинарник в .deb;
- версия записывается в binlog copyfast;
- реплицируется на серверы;
- сервер вытягивает себе свежий .dep;
- dpkg -i;
- graceful перезапуск на новую версию.
Разница в том, что бинарник у нас запаковывается в архивы .deb, и при выкачивании они dpkg -i ставятся на систему. Почему у нас kPHP деплоится бинарником, а движки — dpkg? Так сложилось. Работает — не трогаем.
Полезные ссылки:
- Доклад Антона Кирюшкина «Системный администратор Vkontakte. Как?» с подробностями про copyfast и gossip.
- Доклад Юрия Насретдинова «Как VK вставляет данные в CLickHouse с десятков тысяч серверов».
- Мой доклад «Архитектура растущего проекта на примере ВКонтакте», но с точки зрения разработки, а не железа.
Алексей Акулович один из тех, кто в составе Программного комитета помогает PHP Russia уже 17 мая стать самым масштабным за последнее время событием для PHP-разработчиков. Посмотрите, какой у нас крутой ПК, какие спикеры (двое из них разрабатывают ядро PHP!) — кажется, что если вы пишите на PHP, это нельзя пропустить.
Источник


