
Планета Земля богата не только разнообразной флорой и фауной, но и культурами, народностями и языками. По данным 2020 года в мире насчитывается порядка 7139 языков. Какие-то из них очень похожи, так как относятся к одному семейству, какие-то радикально отличаются. При этом отличия могут быть не только в сложных и замысловатых словах, но и в ономатопеях (звукоподражаниях). К примеру, русскоговорящий человек скажет «гав-гав», англоговорящий «woof» (или же ruff, bow-wow), а франкоговорящий — «ouaf». В принципе, нам несложно догадаться, что англичанин или француз говорят о собаках, учитывая звучание их эквивалента нашего «гав-гав». Это интуитивное связывание слова (звуков) и того, что оно обозначает (смысла), близко к эффекту «буба/кики». Это явление описывает ситуацию, когда большинство людей относят выдуманное слово «буба» к более округлой форме, а слово «кики» — к угловатой, ориентируясь исключительно по их звучанию. Ученые из Бирмингемского университета (Великобритания) установили, что эффект «буба/кики» не имеет границ и распространяется на все народности и языковые группы. Какие опыты провели ученые, что они показали, и какие выводы исследования могут помочь в понимании развития разговорного языка? Ответы на эти вопросы мы найдем в докладе ученых. Поехали.
Основа исследования
Ученые отмечают, что многие годы в исследовании эволюции разговорных языков преобладала теория произвольности, согласно которой форма слова не соответствует его значению. Например, в звучании английского слова «tree» нет ничего, что могло бы у представителя другой языковой группы вызвать мысли о дереве. Тот факт, что в других языках есть совершенно разные формы для одного и того же понятия (нем. «baum», исп. «arbor», кит. «shu»), предполагает, что пары «форма-значение» в значительной степени являются условностью.
В противовес отсутствию логической связи между формой и смыслом в большинстве слов, существуют и те, звучание и смысл которых очень даже хорошо сопоставимы, что называют термином «иконичность». Сами же слова, относящиеся к иконичности, называют ономатопеи, т.е. звукоподражания (к примеру, рус. «бах» и анг. «bang»).
Пример звукоподражания «гав» на 14 языках.
За последние годы было собрано немало данных, которые указывают на то, что иконичность формирует словари разговорных языков далеко за пределами звукоподражания. Это, к примеру, проявляется через иконические соответствия формы и значения в основных словарных элементах (цвет, форма, размер, текстура и т.д.). В добавок существуют доказательства того, что иконичность помогает в изучении языка. К примеру, было показано, что говорящие повышают / понижают свою основную частоту при описании маленького или большого объекта или объекта, расположенного высоко или низко. Подобные наблюдения привели к тому, что иконичность более не считается чем-то случайным, а является важной составляющей эволюции языков.
Учитывая вышесказанное, ученые предположили, что эффект «буба/кики» может быть международным, т.е. не быть связанным с какой-то конкретной языковой группой.
Впервые этот эффект был продемонстрирован в 1929 году психологом Вольфгангом Кёлером. Он провел эксперимент с жителями острова Тенерифе, в котором показывал им две фигуры (округлую и остроугольную) и просил определить, какая из них называется «такете» и « балуба». В результате большинство опрошенных называли округлую форму «балуба», а угловатую «такете».

Вольфганг Кёлер
В 2001 году Вилейанур Рамачандран и Эдвард Хаббард провели схожий эксперимент, заменив слова на «буба» и «кики». В итоге 95% опрошенных (в США и в Индии, так было представлено 2 отличные языковые группы) назвали округлую форму «буба», а остроугольную — «кики». Этот простой опыт показал, что о образование слов, обозначающих какой-то предмет, не на 100% произвольный процесс.
Суть эффекта «буба/кики» связана с разностью фонетических/фонологических измерений этих двух слов, что дает совершенно разные акустические и артикуляционные профили. Попробуйте произнести эти слова, вы увидите, насколько они отличаются как по звучанию, так и по положению губ в момент произношения.

Изображение №1: какое из изображений вы бы назвали «буба», а какое «кики»?
Эти различия касаются формант* гласных, основной частоты гласных, возмущений основных частот, вызванных согласными, продолжительности, звучания согласных, времени начала произношения, округления гласных и т.д. Все эти аспекты могут каким-то образом влиять на эффект «буба/кики».
Форманта* — акустическая характеристика звуков речи (прежде всего гласных), связанная с уровнем частоты голосового тона и образующая тембр звука.
Например, остановки звуков (прерывания), круглые гласные и губные согласные связаны с круглыми формами. А резкие спектральные изменения от беззвучного состояния до высоких частот, вызванные безмолвными остановками, могут иметь отношение к угловатости в визуальной области. Напротив, непрерывная основная частота (например, в словах bouba и maluma) сочетается с более низкими частотами и менее резкими модуляциями амплитуды, что может вызывать ощущение «округлости» произнесенного слова.
Следовательно, существуют четко выраженные фонетические/фонологические элементы слов «буба» и «кики», которые связывают их с округлой и остроугольной формой.
Но, несмотря на всю красоту теории, есть и небольшой нюанс. В предыдущих опытах со словами «буба» и «кики» (анг. bouba и kiki) участвовали представители западного языкового региона. Глядя на англоязычную версию слов, можно заметить, что буквы «k» и «i» визуально более острые (угловатые), а буквы «b», «o», «u», «a» — округлые. Следовательно, результаты опытов могут свидетельствовать не о связи звуков и смысла, а о связи внешнего вида слова и его смысла. Ученые отмечают, поскольку письмо является глубоко укоренившимся когнитивным процессом орфографические представления могут автоматически активироваться даже в полностью слуховых задачах. То есть орфография может сбавить испытуемого с толку даже в опытах, где слова воспринимаются только на слух.
Однако опыты со слепыми людьми, которые никогда не видели латинского алфавита, все равно показали похожий результат, т.е. они относили слово «буба» к округлой форме, а слово «кики» — к остроугольной. Такой же результат показали и представители народности банту (Намибия), которые не знают, как выглядит латинский алфавит.
Если рассматривать картину целиком, то метаанализ 13 различных экспериментов с носителями шести разных языков (английский, французский, итальянский, химба, сьюба и хунджара) показал, что на разных языках 89% всех ответов соответствовали эффекту»буба/кики».
Подготовка к эксперименту
В рассматриваемом нами сегодня труде ученые описывают результаты самого масштабного эксперимента «буба/кики», включающего носителей 25 языков. Было решено использовать классическую модель эксперимента, предложенную Кёлером.
Всего в эксперименте приняли участие 917 человек, говорящих на 25 языках из 9 языковых семейств (таблица ниже). Для разных языков использовался разный алфавит. Латинский был использован в большинстве языков, кроме девяти: армянский, фарси, грузинский, греческий, японский, корейский, китайский, русский и тайский.
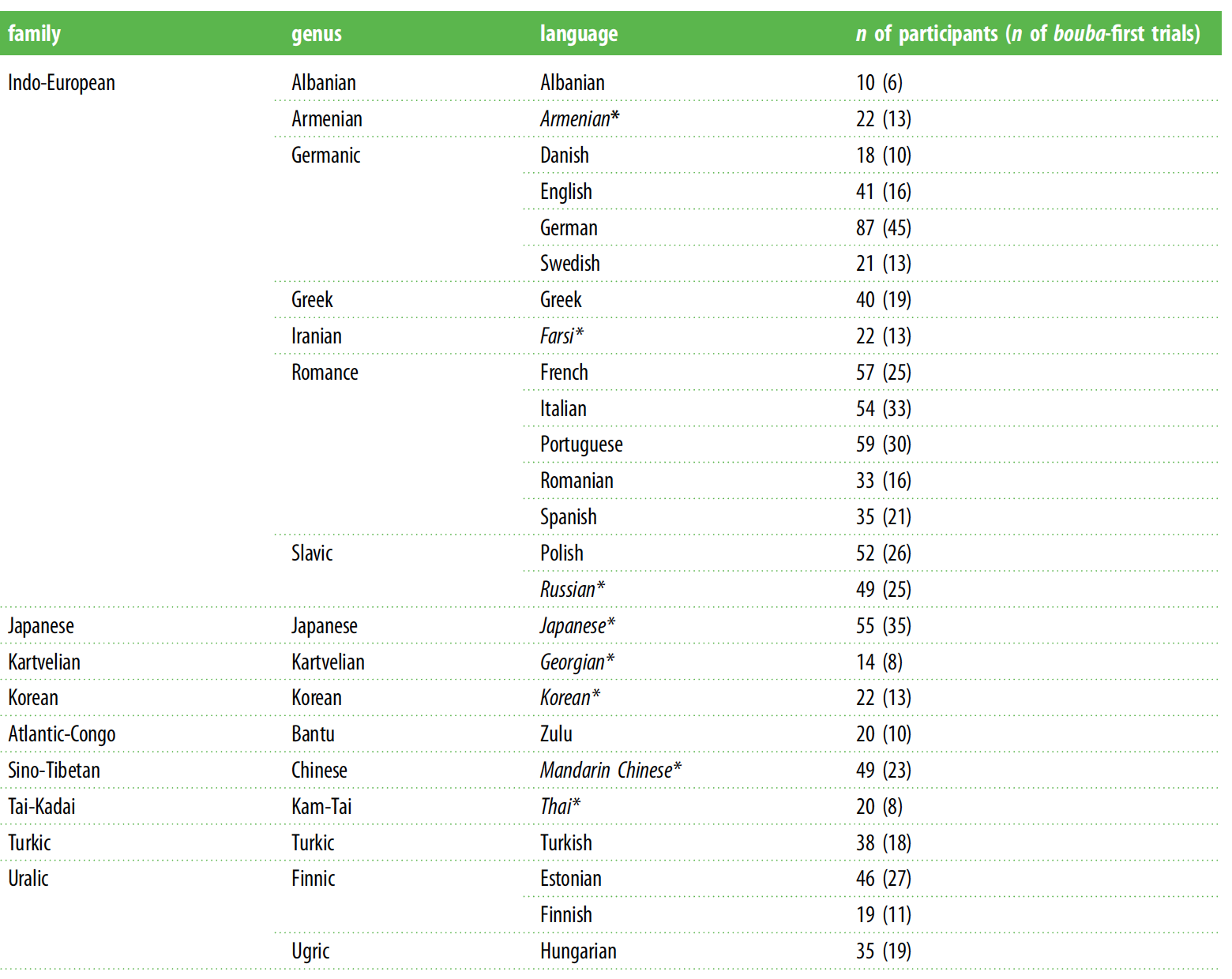
Таблица №1: распределение участников (и испытания, где слово «буба» было первым). В языках, отмеченных звездочкой (*), использовались алфавиты без латинских букв.
Дополнительно ученые спросили участников, не говорят ли они на еще каком-то языке (кроме родного). 86% опрошенных сообщили, что говорят на еще одном языке. При этом 80% участников говорили на английском в качестве основного (L1) или второго (L2) языка. Тех, кто не говорил на английском, было 179 человек. Среди 293 человек, родной язык которых не содержал латиницу, было 55 человек, которые при этом не владели вторым языком, содержащем латиницу.
В качестве стимулов использовались вышеупомянутые изображения «клякс» с округлой и остроугольной формой (изображение №1). Слова «буба» и «кики» произносились женщиной (носитель польского), которая является опытным фонетиком. Буба был представлен как [′bu:ba], а кики как [′khikhi], оба с ударением в начале слова. Стимулы доступны для ознакомления через репозиторий Open Science Framework (OSF) по ссылке.
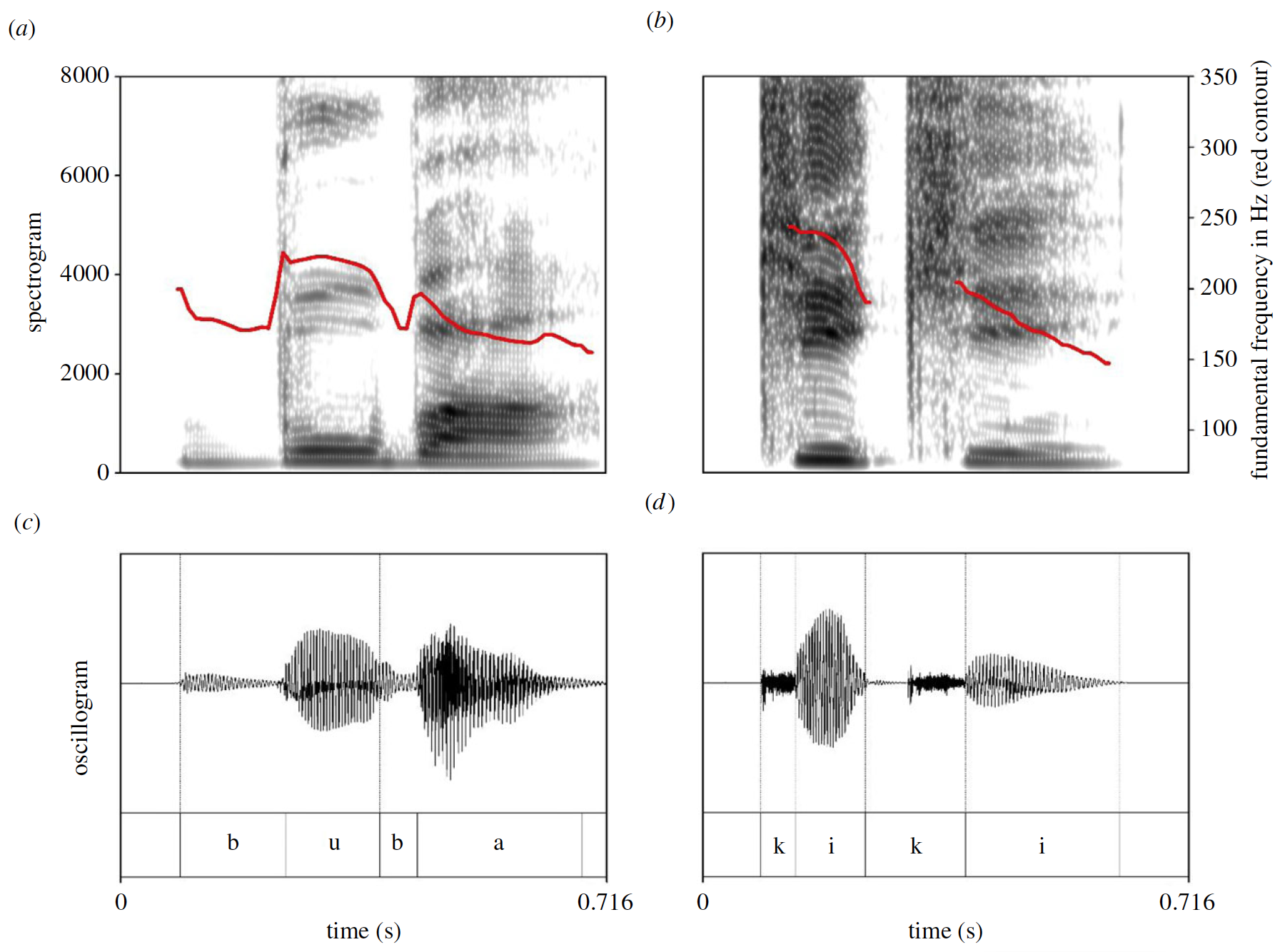
Изображение №2: Спектрограммы (a, b) с основной частотой, отмеченной красным контуром, и осциллограммы (c, d) слов буба (a, c) и кики (b, d).
Опрос участников проводился онлайн с помощью программного обеспечения Percy («Percy – an HTML5 framework for media rich web experiments on mobile»). Участники рассматривали округлые и остроконечные формы, слушая произносимые слова «буба» и «кики» в двух последовательных испытаниях. Стимулы предъявлялись каждому участнику в случайном порядке (в результате 52.5% участников сначала слышали слово «буба»). В каждом испытании, после прослушивания слова, они выбирали, какая из двух форм, по их мнению, лучше соответствует слову (задача с принудительным выбором).
Результаты эксперимента
Средняя доля совпадений буба/кики на разных языках составила 72%, при этом 95% вероятного интервала попадало в диапазон от 56% до 82%. Логит-коэффициент точки пересечения был выше нуля (+0.93).
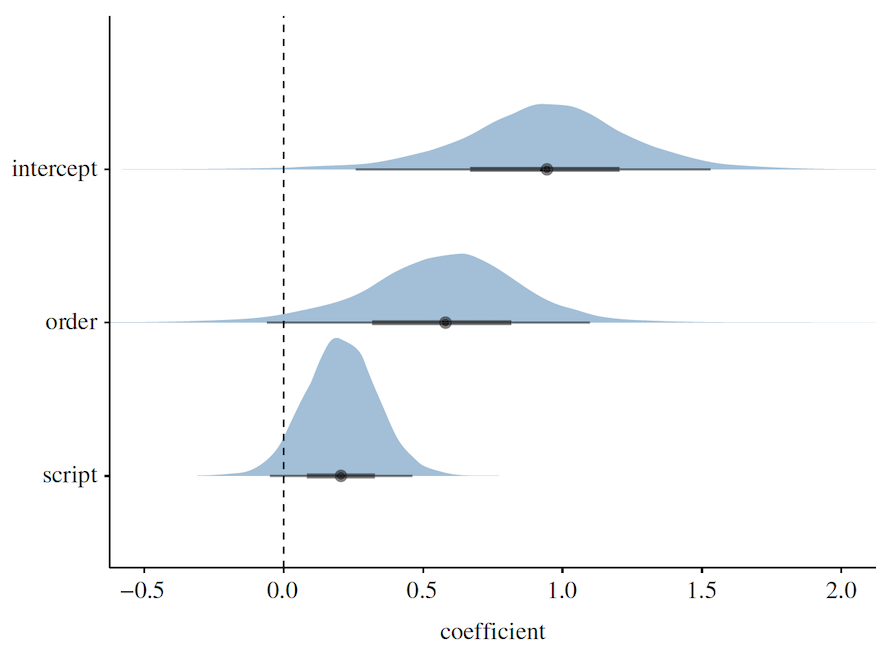
Изображение №3: апостериорные распределения коэффициентов из основной модели.
При анализе результатов опроса по отдельным языкам описательные проценты варьировались от 100% (шведский) до 36% (румынский).
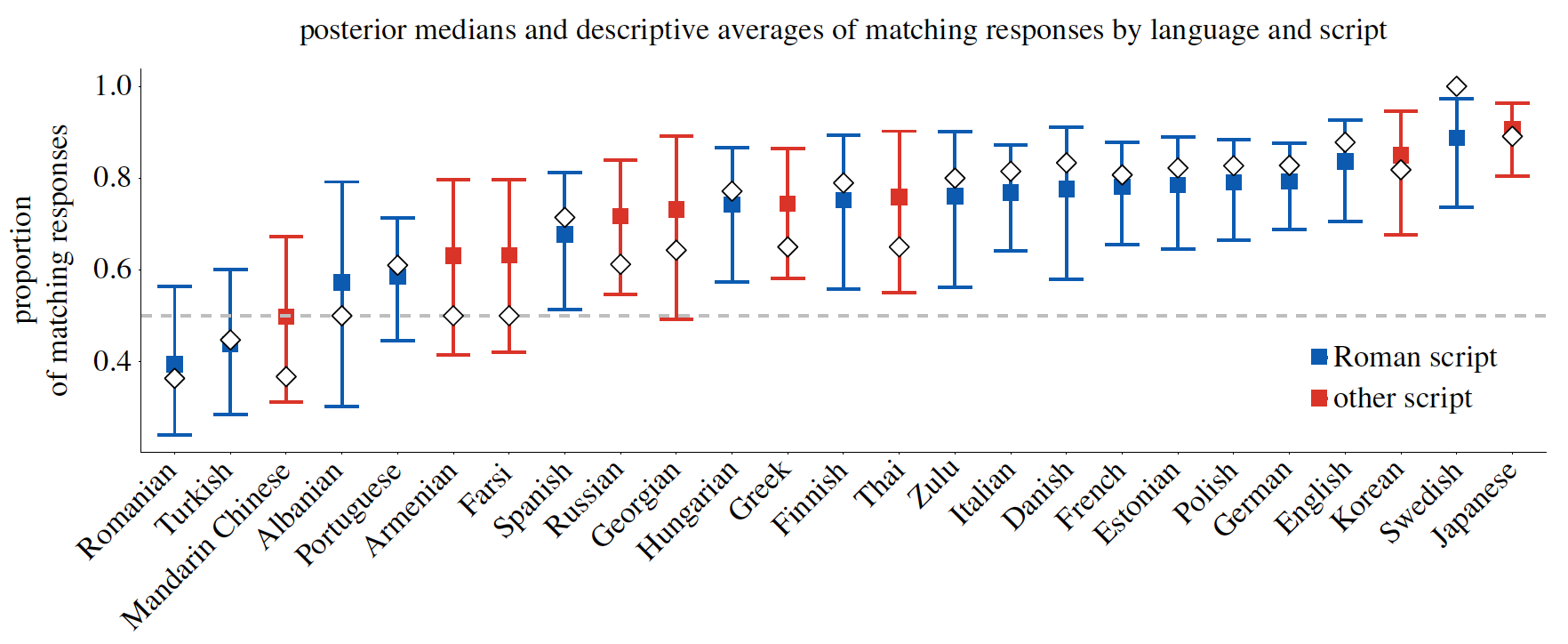
Изображение №4: апостериорные оценки для каждого языка.
Учитывая эти данные, можно уверенно сказать, что 17 из 25 языков показали эффект буба/кики, превышающий 50%. Ученые отмечают, что эта мера довольно консервативна, так как для большинства языков основная часть апостериорного распределения была выше нуля. Что касается описательных средних значений, только три языка (румынский, китайский и турецкий) показали менее 50% совпадений.
Языки, в которых преобладает латинский алфавит, имели более высокие числовые соответствия буба/кики (75%), чем языки, использующие другие письменности (63%).
Апостериорная вероятность того, что эффект алфавита будет выше нуля, была относительно высокой, но намного меньше, чем апостериорная вероятность того, что общий эффект точности будет выше нуля.
Кроме того, для тех участников, которые не говорили на языке с латинским алфавитом в качестве L1, было проанализировано, изменило ли использование языка в качестве L2, который не использовал латинский алфавит, пропорцию совпадений буба/кики. Не было никаких доказательств того, что это так, при этом коэффициентом эффекта алфавита L2 был почти нулевой (+0.08; 5a).
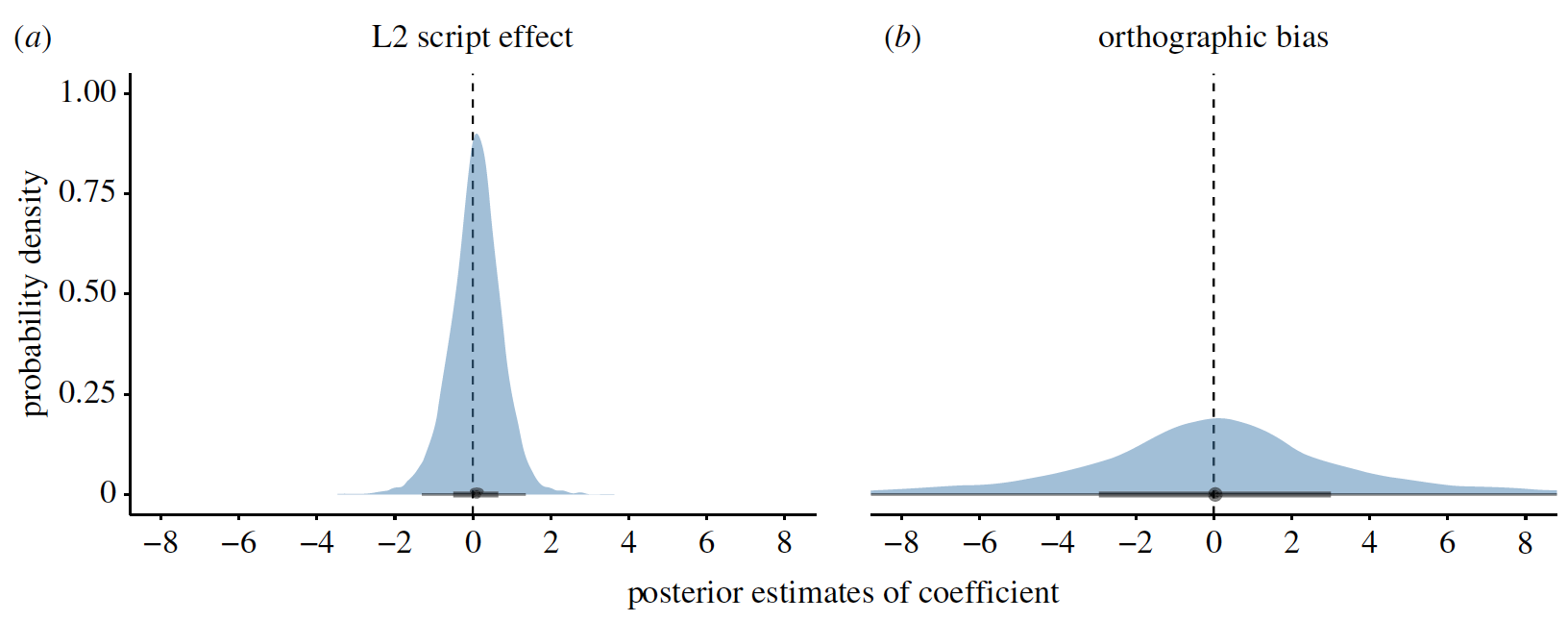
Изображение №5: a — апостериорные выборки для эффекта алфавита L2 (модель, исключающая участников, использующих латинский алфавит в своем L1); b — апостериорные выборки для оценки орфографической ошибки (модель только для языков нелатинской письменности, за исключением греческого и русского).
Далее ученые решили детальнее рассмотреть вероятную связь между эффектом «буба/кики» и алфавитами языков среди участников эксперимента.
По девяти нелатинским шрифтам участники в среднем сопоставляли написанные слова с соответствующими формами, что соответствовало эффекту буба/кики в 56% случаев (английский — 54%, немецкий — 55%, севернокитайский язык — 59%).
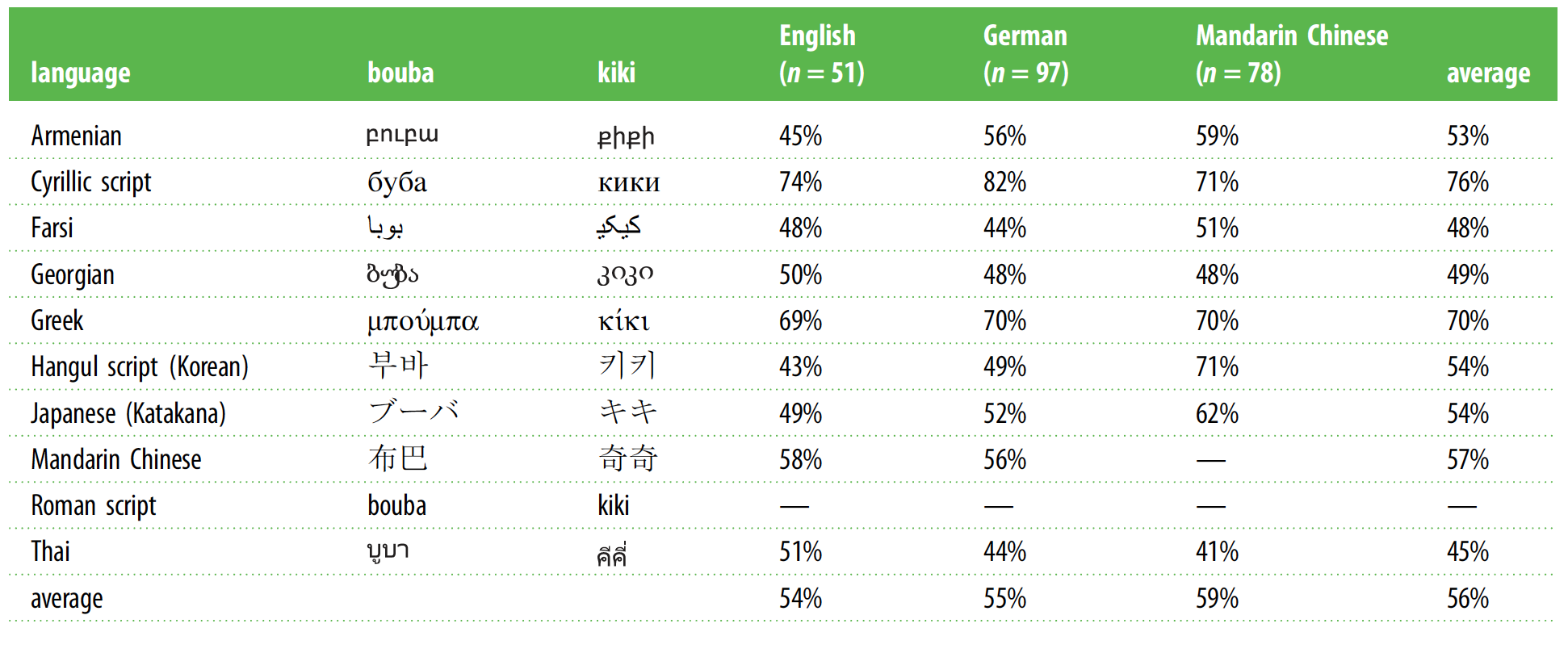
Таблица №2: орфографические изображения слов «буба» и «кики», написанные с помощью алфавитов языков, включенных в эксперимент. Также показан процент совпадения для каждого алфавита среди носителей английского, немецкого и китайского языков.
Результаты были довольно схожи для трех языковых групп. Средняя доля совпадающих ответов для говорящих на английском и немецком языках очень сильно коррелировала (r = 0.88), как и средняя доля говорящих на немецком и китайском языках (r = 0.7). Корреляция между английским и китайским языком оставалась положительной, но была слабее (r = 0.43).
Чтобы проанализировать влияние этого орфографического искажения восприятия, ученые использовали среднюю долю совпадающих орфографических ответов на всех трех языках в качестве предиктора совпадений буба/кики в слуховом эксперименте.
Для этой байесовской регрессионной модели рассматривалось только подмножество участников, которые говорили на языках с нелатинским алфавитом (n = 293).
Коэффициент орфографического смещения был положительным (+0.74), но ассоциировался с чрезвычайно большим вероятным интервалом в 95%, который включал ноль (5b). Апостериорная вероятность положительного эффекта была очень мала и неубедительна (0.68). Следовательно, эффект орфографии на процент совпадений был несущественным и не мог повлиять на конечный результат эксперимента.
Любопытный результат показал сравнительный анализ совпадений формы и слова в рамках оценки «буба» и «кики» отдельно друг от друга.
Среди испытуемых, которым слово «буба» предоставлялось первым, степень точности совпадения с формой была выше, чем в случаях, когда первым представлялось слово «кики».
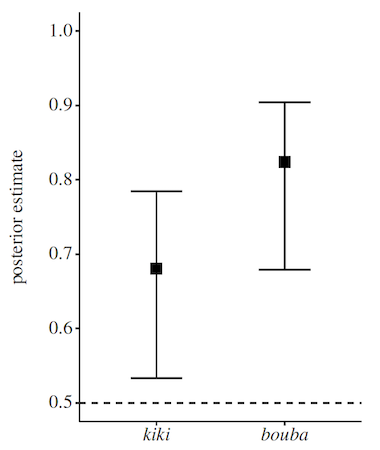
Изображение №6: сопоставление округлой формы и слова «буба» было точнее, чем сопоставление слова «кики» и угловатой формы.
Анализ показал, что участники относили слово «буба» к округлой форме в 22 из 25 языков, тогда как «кики» — в 11 из 25 языков.
Для более детального ознакомления с нюансами исследования рекомендую заглянуть в доклад ученых.
Эпилог
Результаты данного эксперимента наглядно показали, что эффект «буба/кики», описанные Кёлером в далеком 1929 году, не просто существует, а распространяется на всех людей, независимо от языка или используемого алфавита.
Раньше считалось, что между словами и объектами, которые они описывают, нет никакой связи, а иконичность присуствует только в словах, которые пытаются передать какой-то звук (гавканье, тиканье часов, выстрел пушки и т.д.), а не объект. Это, конечно, правдиво для многих слов во многих языках. Однако, учитывая результаты исследования, иконичность нельзя отметать, как нечто косвенное и малозначительное.
Ученые говорят, что эффект «буба/кики» наглядно показывает наличие у человека способности связывать звук слова и визуальные свойства объекта, которая имеет очень глубокие эволюционные корни.
Подобные труды важны для людей, особенно учитывая разнообразие языков в мире. Чем больше мы знаем о том, как формировались эти языки тысячи лет тому назад, тем лучше мы сможем понять их развитие сейчас. Возможно, когда-то человечество начнет пользоваться единым языком, как того хотел Людвик Лазарь Заменгоф — создатель универсального языка «эсперанто». Однако, учитывая то, как сложно порой примерить людей с разными взглядами, перспектива общего языка землян кажется весьма скудной.
Благодарю за внимание, оставайтесь любопытствующими и хорошей всем рабочей недели, ребята. 🙂
Немного рекламы
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас, оформив заказ или порекомендовав знакомым, облачные VPS для разработчиков от $4.99, уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5-2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps от $19 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле в дата-центре Maincubes Tier IV в Амстердаме? Только у нас 2 х Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 ТВ от $199 в Нидерландах! Dell R420 — 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB — от $99! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки?


