Думаю, вы знакомы с графиками сравнения точности архитектур. Их применяют в задачах по классификации изображений на ImageNet.
В каждом сравнении которые я мог встретить ранее в Интернете, как правило это было сравнение небольшого количества архитектур нейросетей, произведенными разными командами, и возможно в разных условиях.
Кроме того в последнее время я наблюдаю изменения: появилось большое количество архитектур. Однако их сравнений с ранее созданными архитектурами я не встречал, либо оно было не столь масштабным.
Мне захотелось столкнуть большое количество существующих архитектур для решения одной задачи, при это объективно посмотреть как поведут себя новые архитектуры типа Трансформер, так и ранее созданные архитектуры.

Цель исследования:
Сравнить большое количество существующих архитектур предобученных сетей, и их результаты для решения задачи классификации изображений.
Моя задача
В качестве задачи для такого масштабного сравнения, я полностью отказался от самостоятельного дообучения нейросетей, и использовал методику сравнения близости векторов признаковых представлений с выхода предобученных нейросетей.
При этом если косинусная близость векторов с изображений одного класса максимальная, то считалось, что эта архитектура наиболее подходит, для последующего дообучения под конкретную задачу.
В используемой задачи брались изображения с 8326 различных классов. При этом многие изображения разных классов могли быть достаточно похожи между собой.
В качестве входных данных брались цветные изображения 224х224 пикселя. Если вход у нейросети отличался от указанного разрешения, то изображением предварительно масштабировались до необходимого.
В качестве метрики качества использовалась доля правильных ответов (в процентах) в топ1 (acc), и доля правильных ответов в топ5 (acc5) наиболее близких векторов.
Все представленные предобученные архитектуры сетей брались из библиотеки timm.
Анализ результатов
Так как использовалось большое количество архитектур, то для сравнения результатов я решил разбить все архитектуры на группы.
-
Группа сетей VGG
Наверное, одна из старейших архитектур в данном рейтинге.

Лидером здесь стала сеть RepVGG-B1 — это одна из моделей классификации изображений RepVGG, предварительно обученная на наборе данных ImageNet. RepVGG – это улучшенная, более глубокая модель VG, выпущенная в 2021 году.
-
Группа сетей DenseNet
Достаточно известная архитектура, которая очень хорошо себя показывает в различных задачах, не оказалась и здесь без внимания.
В это группе первое место заняла архитектура с большим количеством параметров
-
Группа сетей ResNet
Самая большая группа, одной из популярнейших сетевых архитектур. Представлена в виде двух графиков.

Группа “30 лучших”.
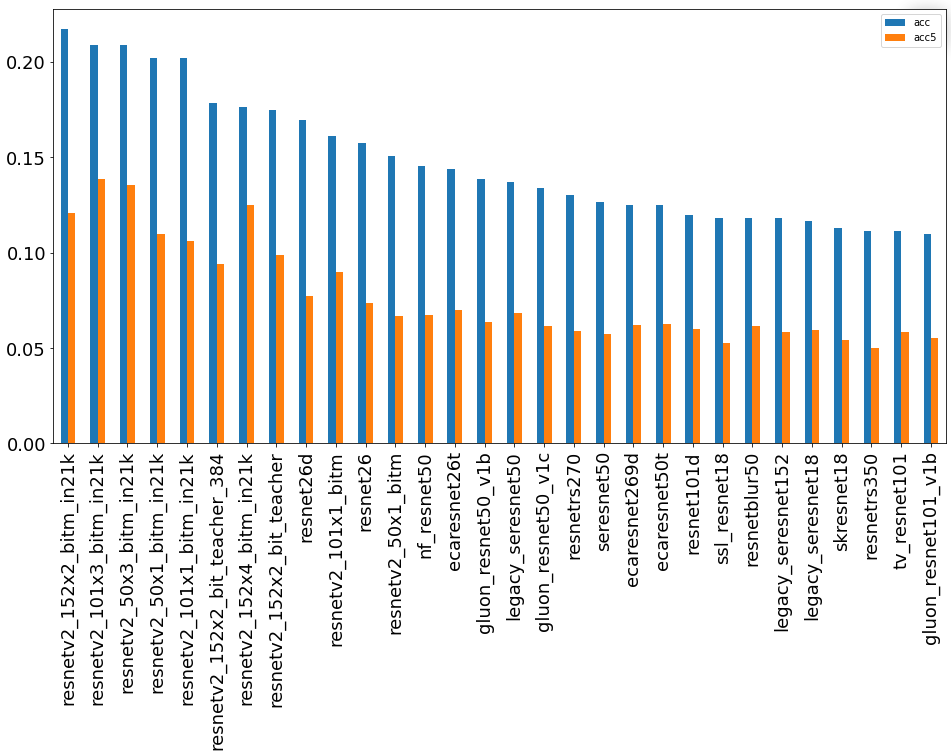
Группа остальных сетей.
В данной группе в лидеры выбрались архитектуры с большим количеством параметров и обученные на большем количестве классов. В лидерах архитектура ResNetV2 обученная на 21 тысяче классов и с использованием технологии Big Transfer. При этом посмотреть на распределение очков внутри группы тоже достаточно интересно. Например resnet18 показала себя очень достойно, что для меня оказалось сюрпризом, а resnet26d попала в топ10 по группе

-
Группа сетей ResNeXt
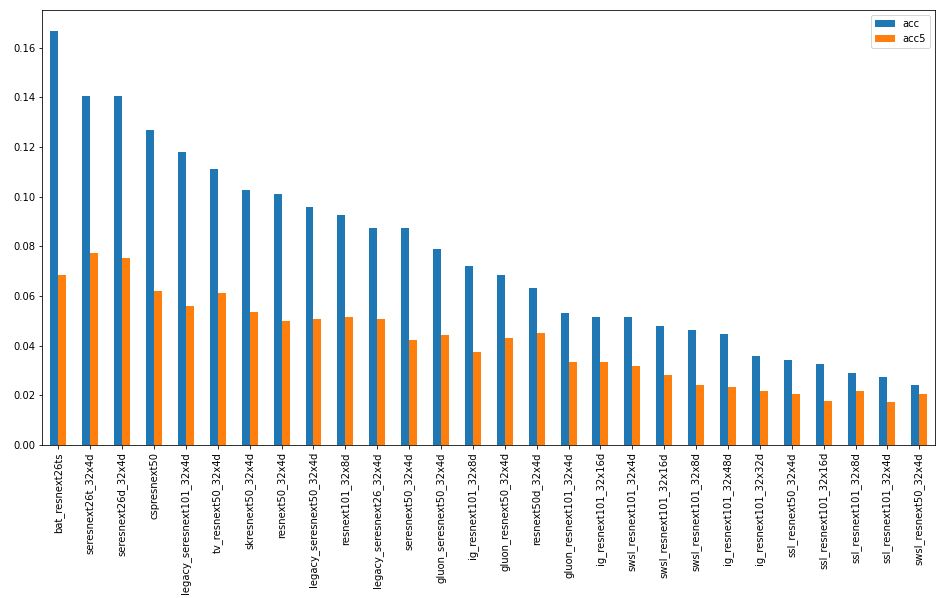
Другая реализация архитектуры ResNet с увеличенной мощностью не показала существенной разницы.
-
Группа сетей ReXNet/ResNeSt/Res2Net

ReXNet– достаточно интересная группа сетей с уменьшенным количеством параметров. Показала неплохие результаты, заняв 13 место в итоговом рейтинге архитектур. Притом, что rexnet_130 (при меньшем количествое параметров (7.5 млн) показало более высокое качество, чем rexnet_200
ResNeSt – реализация сети ResNet с блоками внимания между ветвями, показала неплохие результаты, так как результаты оказались в целом лучше чем у аналогичных архитектур ResNet без таких блоков.
Res2Net – реализация сети заточенная под задачи поиска объектов в разных масштабах и задачах сегментации, точности в приведённой задаче показала одни из худших результатов.
-
Группа сетей RegNet

Группа небольших по количеству параметров сетей как последовательное развитие сетей ResNet показывают очень хорошую точность, так как качество в целом оказалось лучше чем у сетей архитектуры ResNet.
-
Группа сетей Inception/Xception
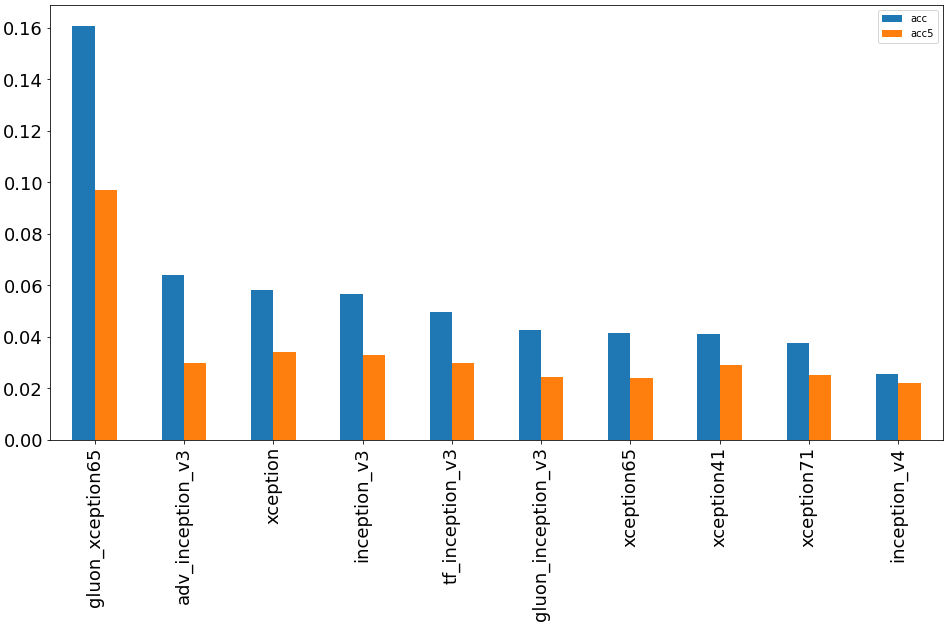
Архитектуры Inception и её модификация Xception оказались в числе отстающих в данной задаче.
Внимание привлекла сеть gluon_xception65, которая, по сравнению xception65, показала существенное улучшение качества. Веса этой модели были перенесены из Gluon.
-
Группа сетей MNASNet/NASNet/PnasNet/SelecSLS/DLA/DPN

Я объединил различные архитектуры сети в эту группу, чтобы можно было сравнить.
SelecSLS – архитектура нейронной сети, предложенная в качестве использования к задаче 3D-захвата движения людей в реальном времени. В задаче классификации показала себя на уровне сетей ResNet.
DLA – архитектура сети глубокой агрегации, имеет иерархические структуры объединения слоев, повышает распознавание объектов. Схожее качество с SelecSLS.
DPN – двойные сети классификации изображений, оказались в списке отстающих по точности.
NASNet архитектура нейронных сетей, оптимизирована с точки зрения производительности
При этом в данной группе, выиграла архитектура NASNet, с небольшим количеством параметров, лучшая в данной группе spnasnet_100, насчитывает всего 4 млн параметров, что более чем в 6 раз меньше, чем в resnet50. Полученная точность существенно выше.
-
Группа сетей MobileNet/MixNet/HardCoRe-NAS

MobileNet – очень популярная группа сетей, оптимизированная для мобильных устройств, показала просто выдающиеся результаты! Сеть mobilenetv2_140 с 6 млн. параметров – на уровне лучших сетей группы ResNet.
MixNet – усовершенствованный потомок от MobileNet: отличные результаты при минимальном количестве параметров сети.
HardCoRe-NAS – группа сетей, полученная в результате автоматического поиска оптимальных архитектур, с малым количеством параметров, но при этом показывающая стабильную и хорошую точность на нашей классификационной задаче.
-
Группа сетей трансформеров BeiT/CaiT/DeiT/PiT/CoaT/LeViT/ConViT/Twins
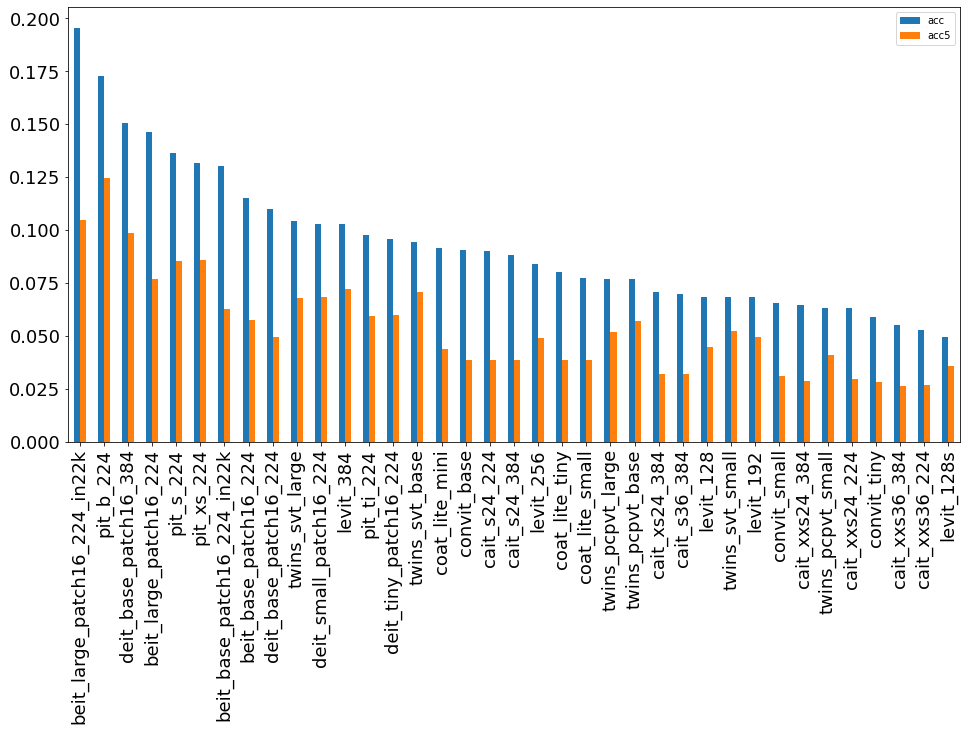
BeiT – сети класса двунаправленного кодировщика от Image Transformers, показали неплохие результаты, заняв 7ое место в данном рейтинге, но количество параметров в этих сетях, конечно, очень велико (325 млн. параметров) для лидера.
CaiT – сети классификации с блоками внимания и Image Transformers с небольшим количеством параметров показали результаты, сопоставимые с группой ResNet.
DeiT – архитектура сетей класса небольших Vision Transformer, которые не требуют долгого обучения и многомиллионных данных, проиграли BeiT архитектуре.
PiT Vision Transformer (PiT) модели с применением пулинга (Pooling) – достаточно небольшие, однако, дали хорошие результаты.
CoaT, Co-scale conv-attention Transformers — классификатор изображений на основе Transformer с небольшим количеством параметров. Несмотря не средние результаты, возможно, стоит посмотреть на эту группу сетей. Так как количество параметров в них меньше, чем в CaiT, но результаты лучше.
Twins — архитектура сетей, которая содержит в себе блоки внимания.
LeViT — гибридная нейронная сеть для быстрой классификации изображений, с блоками внимания.
ConViT — гибридная сеть, представленная как конкурент сети DeiT.
-
Группа сетей ViT (Visual Transofrmer)

ViT (Visual Transofrmer) — архитектура Трансформера, предварительно обученного на больших объемах данных. Тестировалась на различных датасетах изображений среднего и малого размера, стала лидером нашего рейтинга и заняла практически весь пьедестал в задаче Топ-5.
-
Группа сетей ConvNeXt

Современная архитектура ConvNeXt, разработанная как конкурентная альтернатива Трансформерам, при этом не уступающая им в точности и масштабируемости.
-
Группа сетей ResMLP/MLP-Mixer
Группы сетей, полностью построенные на многоуровневых персептронах для классификации изображений.
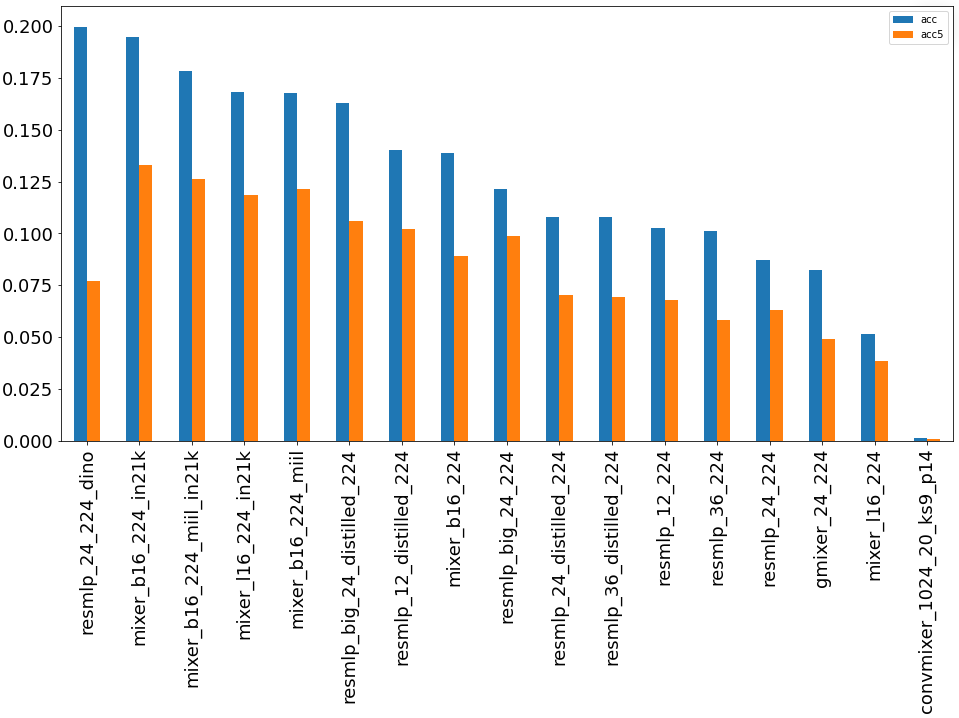
ResMLP – очень интересная архитектура сетей, при этом показала хорошие результаты в данной задаче классификации, и заняла 5 место в данном рейтинге архитектур.
MLP-Mixer – группа сетей, которая основана на многослойных персептронах и обучена на больших наборах данных, и заняла достойное место в данном рейтинге, не сильно уступив при этом ResMLP.
Результаты сопоставимы с другими группами сетей, в том числе, сетями Vision Transformer.
-
Группа сетей NFNet-F
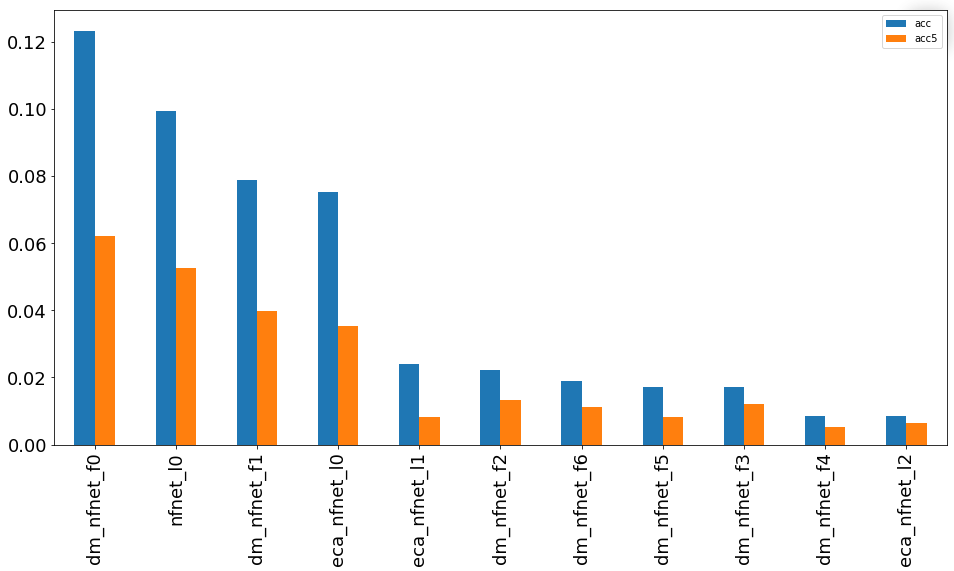
Модели для распознавания крупномасштабных изображений без необходимости нормализации показали плохие результаты по отношению к количеству используемых параметров.
-
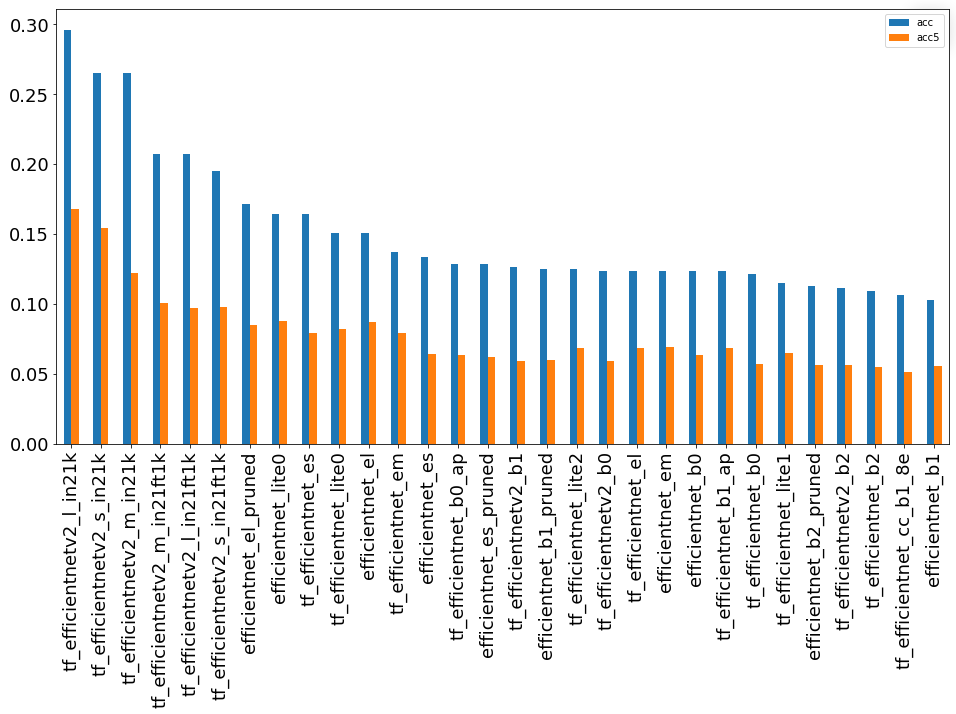
Группа сетей EfficientNet
Целый класс моделей, полученные с помощью автоматического поиска архитектур.
Очень популярная архитектура и представлена в виде двух графиков.
Группа “30 лучших”
Группа “Остальные”
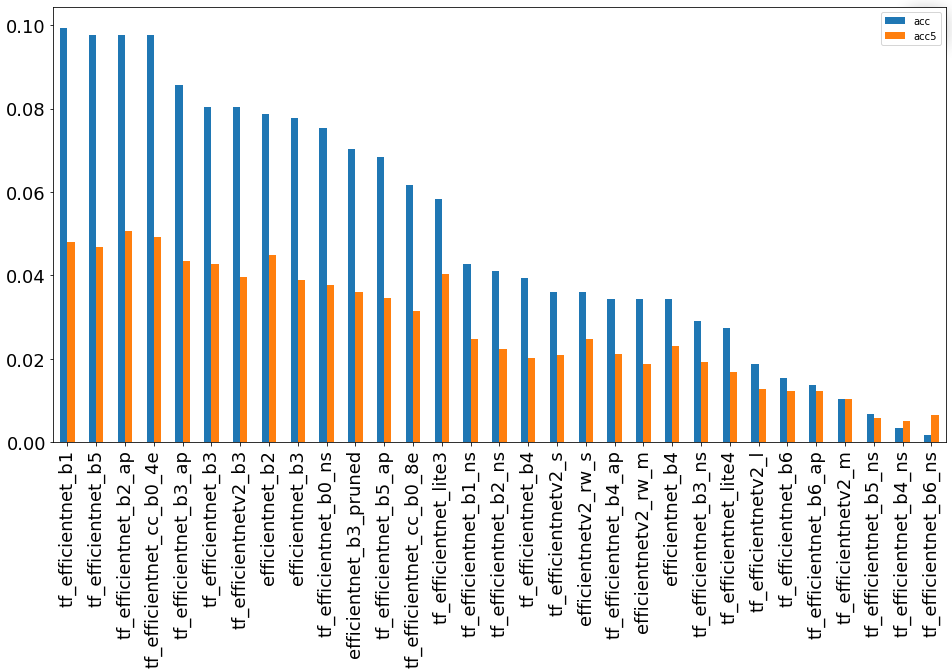
Данные модели имеют в задаче очень большой разброс по точности, однако, лучшая модель все же оказалась в этой группе. Лучшие модели также обучались на классификационных задачах с 21 тыс. классов.
-
Прочие предобученные модели сетей
VovNet – архитектура, предложенная для задач сегментации объектов.

HRNet – архитектура, рассчитанная на изображения с высоким разрешением и задач детекции и сегментации объектов.
Результаты рейтинга архитектур
Была составлена таблица лидеров из каждой группы сетей.
Вы можете провести самостоятельный дополнительный сравнительный анализ архитектуры. Я выложил файл с результатами сравнения в публичный репозиторий на GitFlic.
Выводы проведенного исследования
Действительно, в задачах классификации изображений в последнее время появилось очень большое количество новых архитектур, часть из которых требует пристального внимания.
Видно, что трансформеры присутствуют достаточно уверенно в задачах компьютерного зрения, при этом есть как большие сети Трансформеров с сотнями миллионов параметров, так и небольшие, по размеру сопоставимые с небольшими архитектурами.
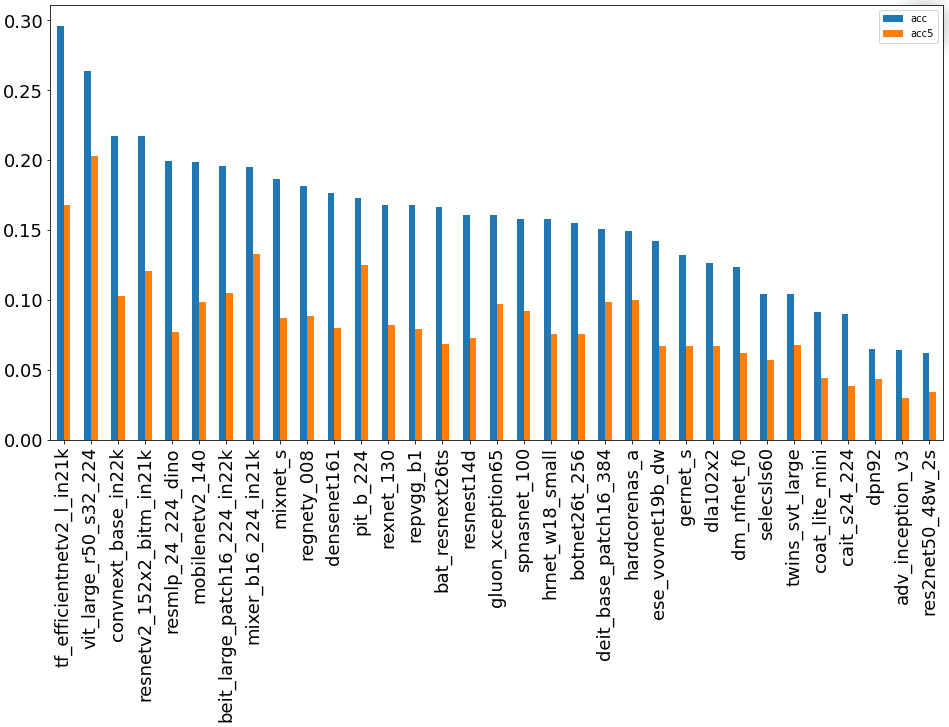
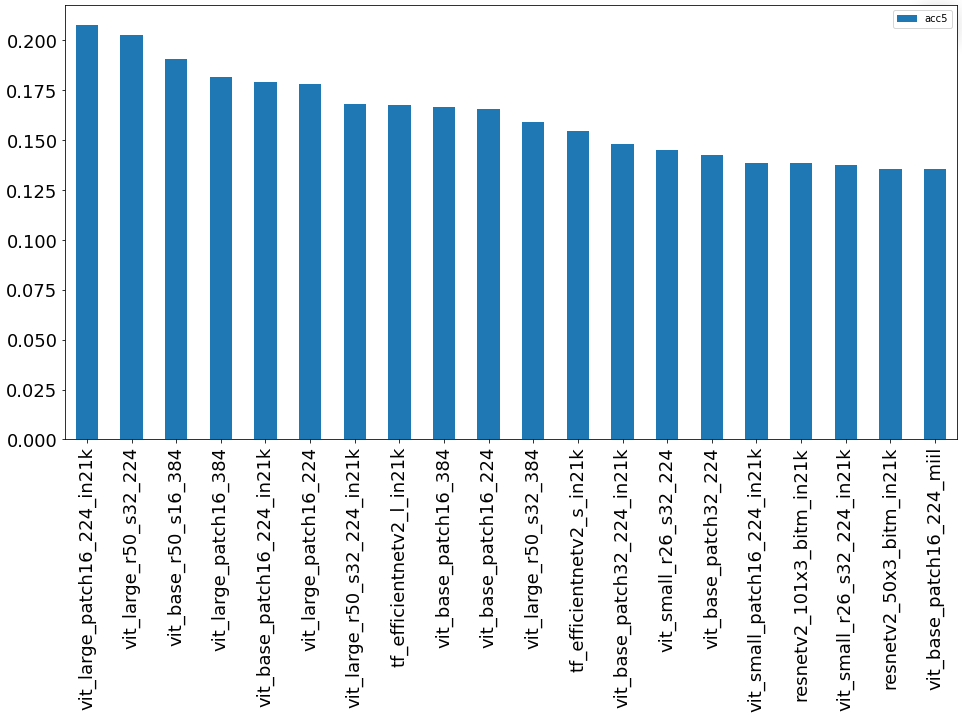
Какая же из предобученных сетей оказалась самой лучшей? Смотрим:
1) График лидеров в задаче Топ-1:

2) График лидеров в задаче Топ-5:
Из полученных данных я сделал вывод, что по точности победила предобученная модель из группы EfficientNet (Топ-1).
По полноте (Топ-5) и корректности полученных признаковых описаний первое место уверенно заняли сети из группы ViT (Visual Transformer).
Эксперт по Машинному обучению в IT-компании Lad


