Крупнейший в истории США блэкаут, случившийся в 2003 году, это один из тех случаев, когда едва ли не ведущую роль в развитии аварии сыграли неисправности ПО. Хотя хватает там и того, что все мы любим в любых авариях: халатность, нарушение протоколов или их отсутствие, несогласованность действий и полный шок, когда ситуация выходит окончательно из под контроля. В общем заваривайте чай, у нас очередной технодетектив.

Пара слов о том, почему линии электропередач могут отключаться
Энергосистема — это довольно сложный организм, состоящий из множества узлов генерации электроэнергии и узлов потребления, соединённых между собой линиями электропередач. Когда-то на заре энергетики электростанции были маленькими и находились рядом с потребителями, а потому были соединены напрямую. Но со временем станции становились больше, возникала задача транспортировки электроэнергии на всё большие расстояния, что требовало усложнять тракт передачи.
Вспомним школу
Как вы должны помнить из школьного курса физики, при протекании тока по проводу тот нагревается. Энергия, которая тратится на нагрев проводника – это потери, а терять электричество – это терять и деньги. Потери на нагрев определяются по формулам:

Соответственно, чтобы снизить потери на нагрев мы можем увеличить напряжение в проводнике или его сечение, причём так как напряжение у нас в квадрате, то увеличение его оказывает гораздо больший эффект на величину потерь, чем увеличение площади сечения проводника. Более того, увеличение сечения крайне негативно сказывается на массе проводника и экономической целесообразности. Отсюда очевидный вывод: надо делать для передачи на дальние расстояния линии с большим напряжением. Но при этом чем выше напряжение – тем больше размеры оборудования и требования к безопасности, а значит, для потребителей в большинстве случаев придётся сохранять низкие значения напряжения.
Это приводит к тому, что энергосистема выстраивается по следующему принципу: есть ЛЭП высокого напряжения, которые осуществляют транзит больших мощностей на большие расстояния, есть линии меньшего напряжения, которые дублируют их и распределяют энергию между более мелкими узлами потребления, и есть линии низкого напряжения в распределительной сети, к которой подключают потребителей.
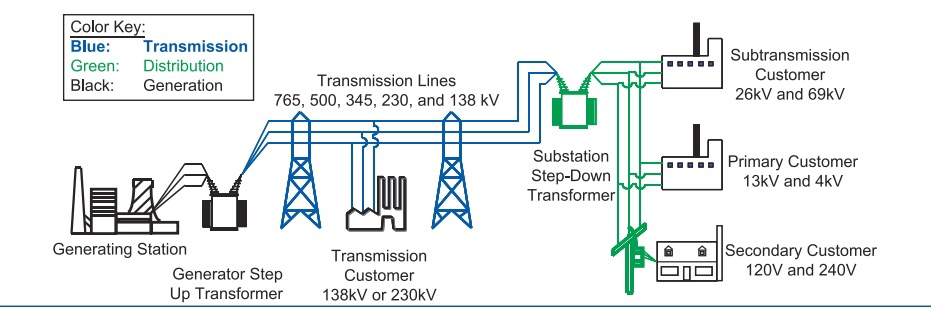
Принципиальная схема сетей США
Но у нагрева проводов есть и ещё одно следствие. Опять же, вспоминаем школьный курс физики: при нагреве проводник расширяется во все стороны, то есть и удлиняется тоже, что вызывает ещё больший рост потерь. Провод из-за удлинения провисает и может либо оборваться, либо задеть какие-то объекты внизу, например ветку дерева, что вызовет замыкание. Худший случай – это перехлёст двух или трёх проводов, что вызовет междуфазное короткое замыкание. Поэтому перегрузку линии током (термическую перегрузку) требуется жёстко ограничивать по значению и длительности.

Ключевая проблема провисания ЛЭП в одной картинке: в данном случае при провисании до 38 футов ветер в 5 узлов может привести к касанию дерева; при 36 — уже даже в отсутствии ветра может произойти касание; при 34 — критический провис по механической прочности самого провода
Что такое короткое замыкание?
Электрический ток, как вода, течёт по пути наименьшего сопротивления. Из двух линий больший ток и мощность потекут по той, у которой меньшее сопротивление. Короткое замыкание случается, когда сопротивление линии внезапно резко падает по одной из озвученных выше причин, и по линии начинает протекать гораздо больший ток, чем допустимо. Ток короткого замыкания может быть в сотни раз больше, чем номинальный, что может привести к повреждению оборудования электростанций и подстанций. Поэтому короткое замыкание требуется как можно скорее устранить, пока оно не нанесло вреда, путём отключения повреждённого элемента энергосистемы.
После отключения повреждённого элемента электрическая мощность, которую мы должны передать потребителям, распределится между оставшимися в работе элементами. Обычно отключение даже одной ЛЭП высокого напряжения не должно оказывать существенного влияния на состояния системы. Тем не менее из-за изменившихся потоков мощности становится возможна термическая перегрузка отдельных элементов энергосистемы, и для исключения их отключения требуется вмешательство оперативно-диспетчерского управления.
Этих знаний нам будет достаточно для понимания процесса развития аварии.
Предпосылки
Любая авария в энергосистеме – это сочетание множества факторов. Как бы ни была сложна система передачи электроэнергии, она обычно имеет достаточный запас надёжности по отказам, а также большую инерцию из-за чего даже в случае неблагоприятного стечения обстоятельств обычно есть время провести компенсирующие мероприятия. Но проблема в том, что для начала опасную для энергосистемы ситуацию нужно вовремя распознать, а с этим в 14 августа 2003 в Северо-Восточной энергосистеме США случились большие проблемы.
Начало аварии положило незначительное на первый взгляд происшествие: в 13:30 остановился блок №5 ТЭЦ Eastlake мощностью 680 МВт. Причина аварии крылась в неправильных действиях персонала, приведших к выходу из строя регулятора возбуждения турбины. Само по себе это происшествие было некритичным. Да, возник локальный дефицит мощности, но его компенсировало увеличение перетоков мощности по линиям из других частей энергосистемы.

Перетоки мощности между сетями энергокомпаний перед аварией
Вторым фактором стало отключение в 14:02 линии 345 КВт Stuart-Atlanta: из-за незначительной перегрузки провода провисли и произошло касание с деревьями, растущими под ЛЭП. Опять же, и этот инцидент не должен был значительно повлиять на состояние энергосистемы при внимательном наблюдении за режимом оператором диспетчерского пункта. Но именно с этим у энергообъединения First Energy Corporation (FE), в чьей зоне ответственности и происходили описанные события, в этот момент случились проблемы.
Ничего не вижу. Ничего не слышу
Для начала разберёмся с инструментарием, с помощью которого диспетчер управляет энергосистемой. Основным инструментом взаимодействия с энергосистемой у диспетчера является Supervisory control and data acquisition (диспетчерское управление и сбор данных) или попросту SCADA. SCADA служит для обеспечения работы систем сбора, обработки, отображения и архивирования информации об объекте мониторинга или управления. Условно её можно разделить на 3 крупных составных части: система сбора информации, система пользовательского интерфейса, система реализации управляющих воздействий.
- Система сбора информации осуществляет сбор данных со всех датчиков (трансформаторов тока и напряжения, датчиков мощности, направления перетока мощности и т.д), информации о срабатывании защит и автоматик, расчёт дополнительных необходимых для контроля параметров и передачу их в систему пользовательского интерфейса.
- Система пользовательского интерфейса предоставляет полученные данные в удобном для оператора формате: мнемосхемы, отображающей состояние элементов сети; графиков изменения ключевых параметров; окон данных параметров по ключевым узлам и каждому объекту сетевого хозяйства; оповещений о событиях.
- Система реализации управляющих воздействий, позволяющая либо отправлять запросы на объекты электросетевого хозяйства об изменениях режима, либо напрямую управлять отдельными её элементами.

А это уже техническая реализация
Резервирует все эти три системы обычный телефон, с помощью которого оператор может узнать о текущем положении напрямую и также напрямую отдать указания. Фактически же, в то время всё оперативно-диспетчерское управление осуществлялось с помощью звонков по телефону, а SCADA выполняла лишь функцию информирования о режиме.
Более того, из-за размеров энергообъединения FE мнемосхема на экране диспетчера при максимальном масштабе отображения была крайне малоинформативна, поэтому диспетчеры полностью полагались на подсистему генерации оповещений, которая выдавала сообщения по факту любых изменений в энергосистеме: включение/отключение объектов, выход контролируемых параметров за допустимые пределы и так далее. По факту получения оповещения диспетчер увеличивал масштаб схемы, рассматривал нужный район и решал о том, какие дальнейшие действия следует предпринять.

Примерно так выглядела мнемосхема на экране оператора. Упустить какое-то изменение статуса линии очень легко
В 14:14 из-за ошибки сервера SCADA подсистема генерации оповещений была потеряна без всяких сообщений об ошибке и диспетчер не узнал об этом, считая отсутствие оповещений за признак нормальной работы энергосистемы, а не отказ функции SCADA. В результате диспетчер на протяжении следующих двух часов был уверен, что у него в энергосистеме всё в порядке. Решением проблемы могло бы быть использование видеостены с большой мнемосхемой, где были бы удобно отображены все объекты и планшеты с основными параметрами сети в ключевых точках. На такой мнемосхеме диспетчер мог бы вовремя увидеть отключение сетевых элементов и изменения параметров режима. Но по неизвестной причине в FE решили сэкономить на этом, из-за чего диспетчер оказался в полной ситуационной неосведомлённости о положении в его энергосистеме.

А вот так должен выглядеть диспетчерский пункт в идеале, с большой мнемосхемой
Что же произошло с серверами FE?
Подсистема генерации отчётов SCADA GE Energy’s XA/21, использовавшейся FE, исполнялась на отдельном резервированном сервере, вместе с другими вспомогательными подсистемами. Такое решение должно было увеличить надёжность работы всей системы и обеспечить большее быстродействие. Принцип работы системы был простой: она обрабатывала входящую информацию о событиях в энергосистеме и изменении параметров, как расчётных, так и измеряемых, и в случае, если один из параметров вызывал срабатывание заранее заданных триггеров, то формировалось оповещение в виде текстового сообщения и звукового сигнала.
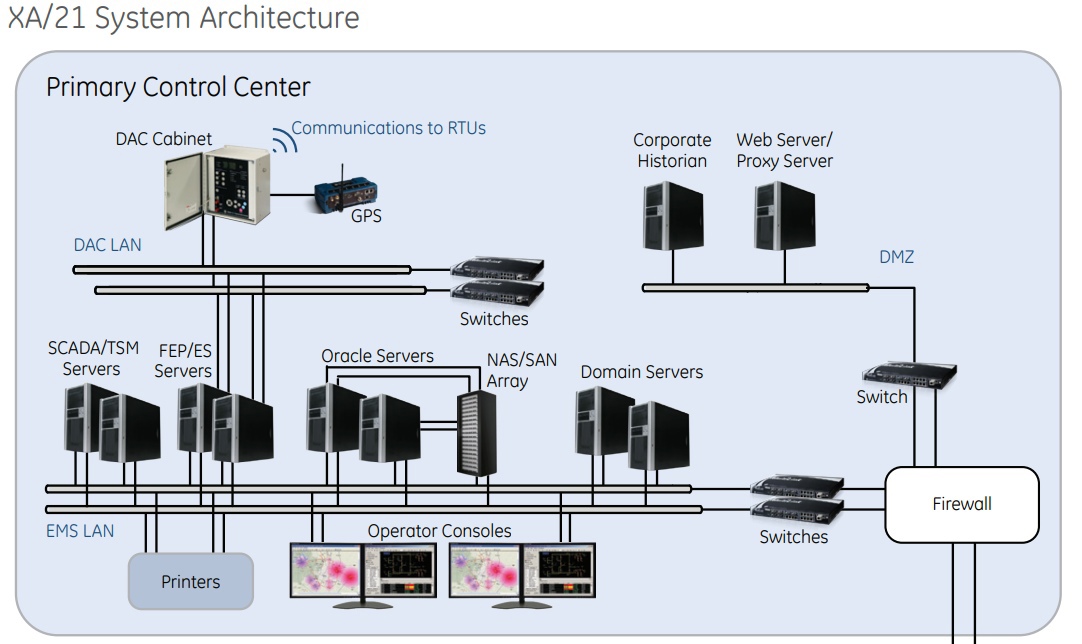
Архитектура SCADA GE XA/21

Окно отчётов о событиях
Во время расследования первоначально предположили, что сервер подсистемы генерации отчётов был поражён червём “Slammer”, бушевавшем тогда в США и уже поразившем ранее несколько ТЭЦ. Но разбор логов и кода не подтвердил эту теорию, система кибербезопасности сетей FE была признана адекватной и нескомпрометированой. Тогда начали искать причину в самом коде и после анализа миллионов строк таки нашли. Проблема заключалась в самом принципе работы генератора отчётов и крайне маловероятном стечении обстоятельств. После срабатывания триггера на вход генератора подаётся запрос на создание оповещения. Из-за кратковременной задержки обработки запросов, не более чем на пару миллисекунд, два процесса одновременно обратились к записи в одну и ту же ячейку памяти. Это привело к «состоянию гонки» (race condition) и зависанию генератора отчётов в бесконечном цикле обращения к ячейке памяти. Из-за этого уже с 14:14 оповещения не генерировались SCADA.

Так как запросы обрабатывались по очереди поступления, то из-за зависания генератора вскоре в буфере скопились необработанные запросы. К 14:41 буфер сервера переполнился и он отключился. На этот случай был резервный сервер, в котором мгновенно из бэкапа были развёрнуты все процессы, ранее запущенные на основном сервере, в том числе и зависший генератор отчётов. Этот сервер протянул гораздо меньше из-за всё большего числа данных на входе и отрубился в 14:54. При этом никаких сообщений об этом диспетчеру сгенерировано не было, автоматически был создан только тикет в службу технической поддержки FE и то только после отключения второго сервера. Из-за отсутствия в протоколе ТП требования сообщать о неисправностях оборудования диспетчерам, техподдержка, естественно, этого не сделала и отправилась чинить сервера, в то время, как диспетчер был свято уверен, что весь последний час они работают нормально.
В 15:08 были «мягко» перезапущены сервера, но при этом инженеры проверили только сам факт восстановления работы серверов, но не функциональность их ПО. А ПО подсистемы генерации отчётов после ребута серверов из-за ошибки при завершении работы оказалось нефункциональным. То есть перезапуск серверов никак не решил проблему. В 15:42 звонок из техподдержки сильно удивил диспетчеров, сообщением, что «мы восстановили работоспособность сервера генерации отчётов». При этом подсистема генерации отчётов всё ещё не работала и диспетчер пребывал в полной уверенности, что у него-то в энергосистеме всё в порядке. Хотя на самом деле к моменту этого звонка всё уже 10 минут как катилось к чёрту и точка невозврата была очень близка.
Потерянное время
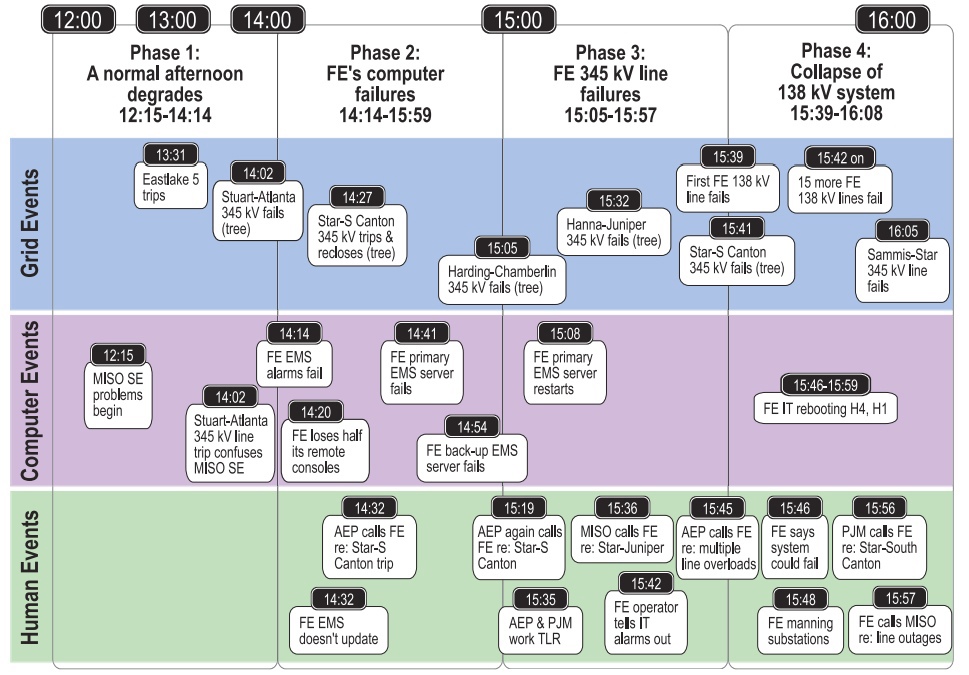
Таймлайн блэкаута
Так как диспетчер FE не знал об отказе генерации отчётов, а потому считал, что в его зоне ответственности всё в порядке, то он естественно пропустил роковое для энергосистемы событие – отключение ЛЭП 345 кВ Chamberlin-Harding. Она отключилась в 15:05 при нагрузке всего 45,5% от номинальной из-за касания фазой дерева, растущего под ЛЭП. Первой очевидной причиной такого развития событий было пренебрежение FE ухаживанием за трассами ЛЭП, так как это было уже второе за два часа, но не последнее за день, отключение линии из-за касания деревьев. Второй же причиной, непосредственно приведшей к первой, стал рост перетоков по линиям и их нагрев из-за уже случившегося ранее ослабления сети. Тот факт, что перегрузка на них так и не наступила был скорее лишь отягчающим обстоятельством, так как незначительный провис из-за термического расширения провода привёл к короткому замыканию, чего в нормальной ситуации быть не должно.
Так как в SCADA никаких уведомлений не было, то диспетчер FE был уверен, что ЛЭП 345 кВ Chamberlin-Harding находится в работе и на звонки с вопросом о её состоянии отвечал, что «всё ОК». В 15:32 из-за выросшей нагрузки коснулась деревьев и отключилась ещё одна линия — 345 кВ Hanna-Juniper. Отключение уже трёх системообразующих линий 345 кВ привело к росту нагрузки на все остальные линии. Диспетчер FE всё ещё бездействовал, так как не знал о всех этих авариях.

Диспетчер FE
Точкой невозврата стал отказ линии 345 кВ The Star-South Canton расположенной на стыке FE and AEP (American Electric Power). Эта линия уже дважды отключалась из-за выросшей нагрузки по ней: в 14:27 и в 15:38. Оба раза причиной были всё то же сочетание факторов перегрузка + деревья, растущие под ЛЭП. В 15:41 линия 345 кВ The Star-South Canton отключилась в третий раз и восстановить её работу на этот раз не вышло.
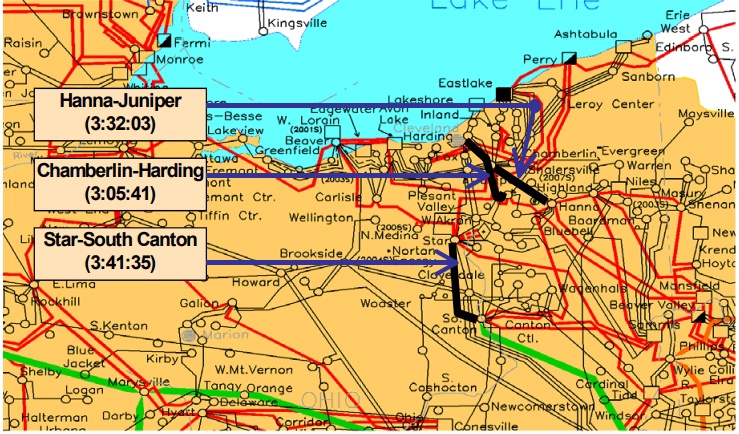
Схема сети и три первые отключившиеся линии 345 кВ
Всё, точка невозврата была пройдена – сеть потеряла 4 системообразующие ЛЭП из-за чего началась перегрузка сети меньшего напряжения 138 кВ. Первая линия 138 кВ отключилась в 15:39, то есть за две минуты до отключения 345 кВ The Star-South Canton, но после процесс принял лавинообразный характер, так как чем меньше линий оставалось в работе – тем больше была перегрузка оставшихся.
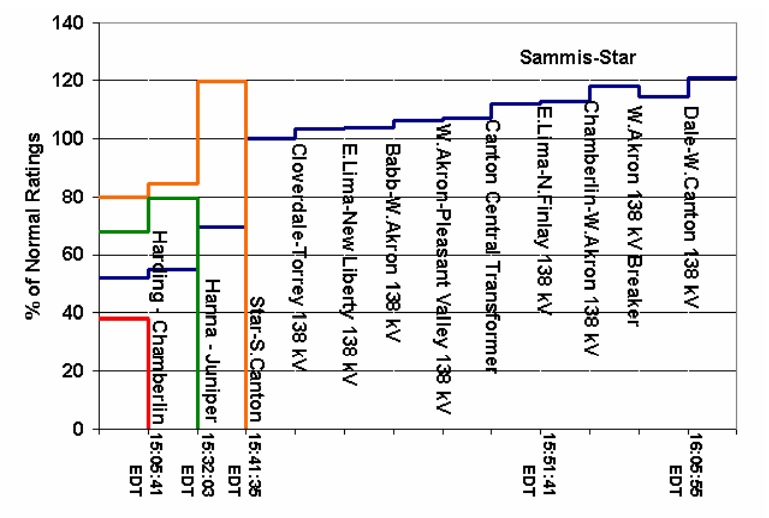
Таймлайн роста перегрузки линий
При всём при этом оператор FE не делал НИЧЕГО, так как всё ещё не знал об отказе SCADA, а на все звонки отвечал, что «проблема не в моей зоне ответственности, ищите у себя». Время на предотвращение аварии было упущено и процесс вошёл в самоподдерживающуюся стадию – впереди был только блэкаут. Но неужели система была столь плохо выстроена, что отказ одного диспетчерского пункта привёл к неминуемому коллапсу энергосистемы? Конечно нет, но в тот день США очень не повезло.
Координировали, координировали, да не выкоординировали
Естественно, что в США управлением энергетики страны занимались не дураки и понимали, что для координации деятельности разных диспетчерских центров нужен единый орган. И он на Северо-Востоке США был – координатор надёжности энергосистемы или Midcontinent Independent System Operator (MISO), объединявший значительную часть операторов энергосистем Северо-востока. К MISO в автоматическом режиме поступали все данные энергообъединений о состоянии объектов сетевого хозяйства (включены/отключены), а также результаты измерения основных параметров. По этим данным информационная система MISO должна была проводить анализ надёжности, сводящийся к расчёту режима и поиску опасных для работоспособности системы ситуаций. Выполнение таких расчётов должно было проводиться как автоматически по таймеру и при отключении/включении объектов, так и вручную в случае необходимости проверки верности предлагаемых управляющих воздействий.
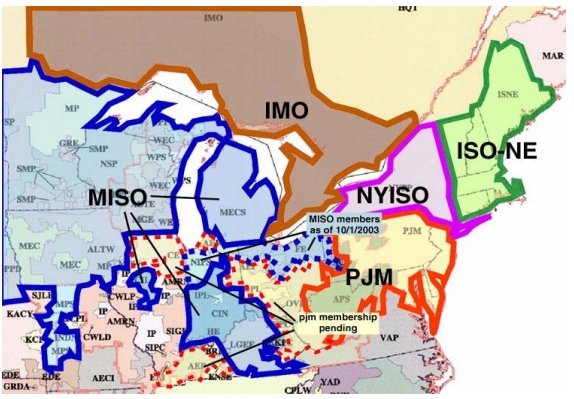
Операционная зона MISO
В идеальном мире для этого использовалась бы real-time система, как SCADA, но MISO развивало свой собственный продукт, в основном методом добавления костылей. Система в распоряжении MISO была не real-time, да она получала данные с низовых устройств, но расчёт надёжности проводился по таймеру раз в 5 минут, таким образом оператор имел срез состояния энергосистемы, который мог за следующий промежуток времени сильно устареть. Автоматический расчёт надёжности проводился по скрипту, который днём в 13:07 был отключён для проведения работ с системой. Причиной стала необходимость привязать сигналы включенного/отключенного состояния линии 230 кВ Bloomington-Denois Creek к её отображению в расчётной модели. После окончания процесса диспетчер попросту забыл активировать скрипт и ушёл на ланч, из-за чего до 14:40 автоматический расчёт надёжности не производился.

При этом даже после восстановления работы скрипта и получения результатов расчёта, свидетельствующих о нарастании кризиса в энергосистеме, эти расчёты оказались неадекватны ситуации. Как выяснится уже в ходе расследования, линия 345 КВт Stuart-Atlanta, отключившаяся ещё в 14:02, тоже не была подключена к автоматическому обновлению статуса по данным, получаемым от автоматик. Из-за этого расчётная модель обсчитывала более лёгкий режим и диспетчер MISO не понимал всю тяжесть ситуации.
Как результат, MISO до 14:40 вообще не понимало о существовании кризисной ситуации. После 14:40 ситуация оценивалась куда легче, чем была в реальности. Сомнения в том, что результаты расчётов адекватны, появились у диспетчера MISO лишь в начале 15 часов, когда стало ясно, что реальные замеры мощности и расчётные сильно расходятся. И только в 15:29 после телефонного звонка оператору линии 345 КВт Stuart-Atlanta (фирма PJM), была найдена ошибка в модели, устранённая к 16:04, когда каскадная авария уже охватила всю энергосистему. В результате MISO не смог выполнить свою основную функцию – сохранить надёжность работы энергосистемы. При этом, как выяснится в ходе расследования, схожая же проблема была и у SCADA оператора PJM.

У MISO кроме ПО для расчёта надёжности были и альтернативные решения, которые выступали вспомогательными средствами и могли бы помочь быстрее сориентироваться. Так, в комплексе ПО MISO была ещё и программа Flowgate Monitoring Tool (FMT), которая была альтернативным средством, рассчитывавшим перегрузки наиболее важных линий и сигнализировавшей об этом. Данное ПО работало в тот день штатно и могло бы вовремя сработать, но оно не смогло вовремя выявить аварийную ситуацию из-за особенностей сбора данных. В отличии от расчёта надёжности, FMT получала данные о состоянии линий не от их автоматик, а из базы данных NERC SDX, куда владельцы линий должны были сообщать в течении 24 часов(!) о всех выполняемых переключениях. В результате эта система обсчитывала подчас режимы, отстоящие от реальных на часы, и никто этого вообще не замечал. По какой причине FMT брало данные не из обновляющейся автоматически информации о состоянии линий, неизвестно.
Кроме того, была и система оповещений об отключении линий, похожая на имевшуюся в SCADA FE. Но и она оказалась бесполезна, так как, во-первых, диспетчер просто не заметил оповещения. А во-вторых, пользовательский интерфейс был таков, что диспетчеру после получения оповещения требовалось найти на схеме нужный выключатель и уже, кликнув по нему, проверить его состояние. Система не подсвечивала выключатели, изменившие состояние, и не имела функции перехода к объекту по щелчку на уведомление. Все эти недостатки вместе стали фатальны для работы MISO в тот день.
Коллапс
После 15:42 энергосистему Северо-востока было уже не спасти. Лавинообразный процесс нарастания перегрузок и отключений линий привёл к тому, что за следующие 25 минут отключилось из-за перегрузки 11 линий 138 кВ и 1 – 345 кВ. За следующие 5 минут отключилось 6 линий 345 кВ. Каскад перегрузок линий и их отключений привёл к ещё одному каскадному процессу – лавине напряжения, так как баланс нагрузки и генерации стал смещаться в сторону нагрузки и напряжение в сети стало проседать. А когда напряжение в сети уменьшается, то уменьшается и производительность питательных насосов электростанций, из-за чего их эффективность падает и ещё больше увеличивается дефицит генерации. В течении следующих 5 секунд с 16:10:39 по 16:10:46 отключилось 5 линий 345 кВ и 19 энергоблоков станций (в том числе 1 блок АЭС) суммарной мощностью 4700 Мвт.
При этом никто из диспетчеров так и не понимал, что и почему происходит. MISO только-только восстановили нормальную работу ПО для оценки надёжности, но всё новые отключения приводили к расхождениям их схемы и реальности. Операторы AEP и PJM, на энергосистемы которых начали накатывать перегрузки, тоже потеряли контроль за ситуацией, так как не понимали причину возникших сложностей, а оператор FE клятвенно уверял, что «проблемы не в сети FE, у нас всё в порядке». При этом в работе SCADA AEP и PJM тоже были недостатки, в частности проблемы с обновлением статуса состояния линий, но это уже мало влияло на ситуацию.
Диспетчеры FE начали понимать, что что-то, возможно, идёт не так, когда после 15:42 на них обрушилась просто лавина звонков от соседних диспетчерских пунктов и низового персонала FE о всё новых отключениях линий. Только после этого диспетчер решил таки позвонить в техподдержку и попросить проверить работу сервера ещё раз. К 16:05 был произведён полный перезапуск подсистемы генерации отчётов и она заработала. Внезапное прозрение, что проблема таки в сети FE, произошло — но было уже слишком поздно. Диспетчеры FE и других операторов, могли лишь наблюдать за разворачивающимся апокалипсисом, так как сделать что либо было уже решительно невозможно.

Диспетчер FE в 16:00
Диспетчер FE в 16:05
История сохранила записи телефонных звонков операторов, в которых сквозит полное непонимание происходящего:
Оператор AEP: “У нас большие проблемы… много линий отключается. East Lima и New Liberty отключились. Посмотри на это.”
Оператор AEP: “О боже, я в глубокой …”
Оператор PJM: “Ты и я, мы оба, брат. Что мы собираемся делать? Если тебе что-нибудь нужно, дай мне знать.”
Оператор AEP: “Только что еще что-то отключилось. Много чего происходит.”
Оператор PJM: “И когда это произошло? Это могло бы…”
Оператор MISO: “Я еще не знаю. У меня все еще есть… У меня не было пока возможности изучить этот вопрос. Сейчас слишком много всего происходит”.
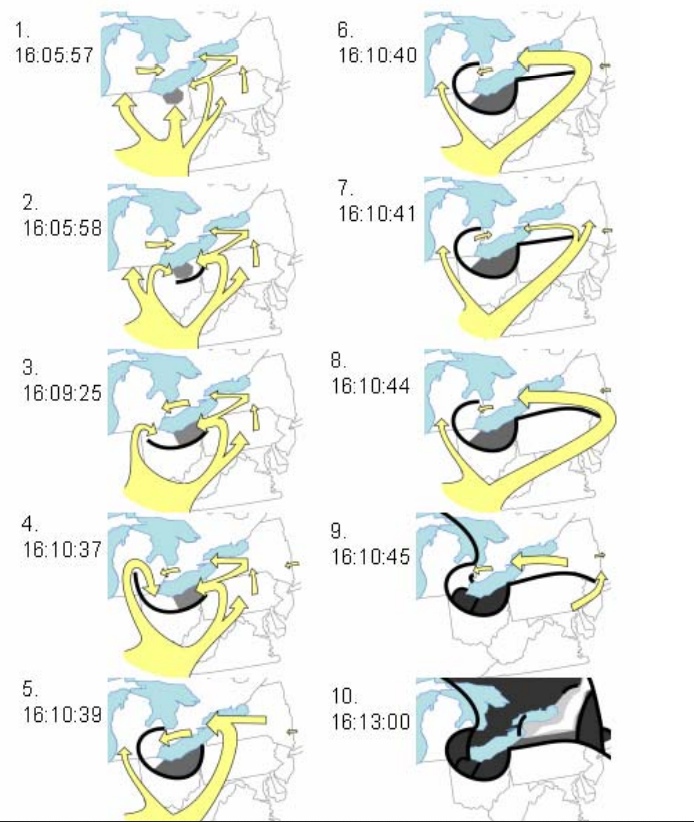
Последние минуты перед коллапсом. Жёлтым отмечены перетоки мощности
К 16:13 коллапс энергосистемы завершился, приведя к отключению сотен линий электропередач и 508 энергоблоков на 265 электростанциях, из которых 10 – это АЭС(!). В зоне отключения оказались: северная часть Огайо, восточная часть Мичигана, северная часть Пенсильвании и Нью-Джерси, большая часть Нью-Йорка, Массачусетс, Коннектикут, Вермонт, а также канадские провинции Онтарио и Квебек. Всего без света остались 40 миллионов человек в США и 15 миллионов в Канаде. Рухнула сотовая и телефонная связь, остановилась торговля на Нью-Йоркской фондовой бирже, возникли проблемы с посадкой самолётов и многочасовые задержки рейсов. Единственным плюсом было то, что авария произошла днём и власти успели наладить подобие порядка на улицах городов. На полное возвращение энергоснабжения ушло несколько дней из-за того, что многие станции вынуждены были проводить ремонтные работы из-за аварийного останова.
Эпилог
Как несложно заметить, авария развивалась 2 часа, из которых первые полтора часа было достаточно возможностей для предотвращения коллапса, но из-за бездействия диспетчеров ситуация развилась в каскадную аварию, остановить которую было уже нереально. При этом причиной «веерного отключения» стала череда из множества совершенно неожиданных отказов. Фактически только отсутствие оперативного диспетчерского управления и сделало блэкаут неизбежным, хотя если бы линии ЛЭП оператор FE вовремя очищал от деревьев, то может ничего вообще бы и не случилось. После аварии было проведено расследование, которое выявило все описанные и многие другие проблемы. Среди предложений мер реакции были, как организационные меры, в частности пересмотры внутренних регламентов и аудиты, так и технические меры: совершенствование систем SCADA, более жесткие требования к контролю состояния линий, установка автоматик отключения нагрузки при снижении напряжения и так далее. Более крупных блэкаутов в США не было, но как и в любой сложной системе, сколько бы дыр в ней не закрывали, всегда может найтись новая.
Источники
- NERC «Technical Analysis of the August 14, 2003, Blackout: What Happened, Why, and What Did We Learn?»
- U.S.-Canada Power System Outage Task Force «Final Report on the August 14, 2003 Blackout in the United States and Canada: Causes and Recommendations»
- The Availability Digest «The Great 2003 Northeast Blackout and the $6 Billion Software Bug»



