
Итак, пришёл черёд полностью официальных данных о новом графическом процессоре Nvidia поколения Ampere и о продуктах, связанных с этим GPU.
Во многом мы уже разобрались, опираясь на сторонние источники, но только что Nvidia опубликовала пресс-релиз и видео с презентаций в том числе GPU A100. И начнём мы с названия. Дело в том, что сама Nvidia создала некую путаницу с названиями. Компания везде говорит о продукте под названием Nvidia A100 GPU или Nvidia A100 Tensor Core GPU. И можно было бы подумать, что топовый графический процессор Ampere называется именно A100, однако, судя по различным данным и информации сторонних источников, это не так.
Nvidia A100 GPU — это не графический процессор сам по себе. Это графический ускоритель, который мы называли Tesla A100, но сама Nvidia на данный момент его так не называет. Либо мы имеем дело с ребрендингом, либо позже Nvidia A100 GPU просто появится на сайте Nvidia в соответствующем разделе под именем Tesla A100.
В любом случае, когда Nvidia говорит о Nvidia A100 GPU, она имеет в виду готовый ускоритель вычислений. Сам же графический процессор, лежащий в основе этого ускорителя, видимо, всё же называется GA100.
Мы уже знали, что GA100 содержит невероятные 54 млрд транзисторов и производится по семинанометровому техпроцессу на мощностях TSMC. Но была противоречивая информация относительно конфигурации. Итак, GPU GA100 содержит 8192 ядра CUDA, и это на 52% больше, чем у GPU GV100. Также GPU включает 512 тензорных ядер третьего поколения и шесть модулей памяти HBM2 с шиной памяти разрядностью в 6144 бита. Что интересно, тензорных ядер у GPU GV100 было больше, но в случае архитектуры Ampere это новые ядра третьего поколения, которые впервые поддерживают операции с плавающей запятой с одинарной и двойной точностью.
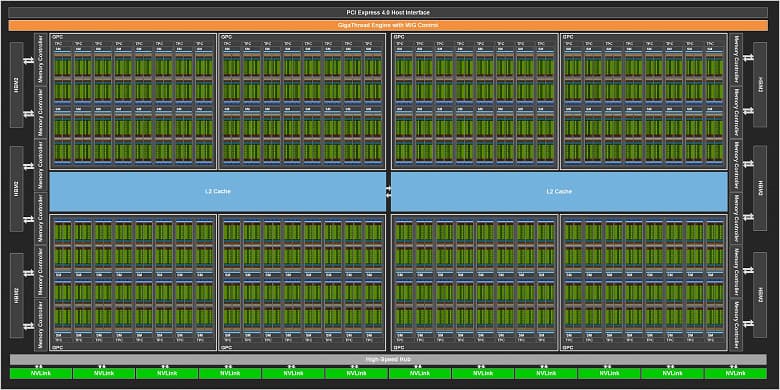
При этом ускоритель A100 или Tesla A100 располагает урезанным GPU GA100 с 6912 активными ядрами CUDA и 432 активными тензорными ядрами, а также пятью модулями HBM2 (40 ГБ) с шиной памяти разрядностью в 5120 бит.
То есть в случае A100 у графического процессора отключено 15% всех имеющихся у него ядер, и это странно. Возможно, Nvidia готовит что-то ещё более производительное, но обычно топовое решение компания показывает сразу. Можно предположить, что GPU попросту оказался настолько сложным, что выход полностью годных кристаллов сейчас мизерный, и Nvidia пришлось пойти на урезание GPU для топового продукта.
Также стоит отметить, что производительность ускорителя A100 составляет 19,5 TFLOPS (FP32) либо 9,7 TFLOPS (FP64), что далеко не вдвое больше, чем у Tesla V100 (15,7 и 7,8 TFLOPS соответственно). Однако именно в задачах, связанных с искусственным интеллектом, новый ускоритель превосходит старый порой в шесть-семь раз, что обусловлено новыми тензорными ядрами, превосходящими ядра прошлого поколения в 20 раз.

Также Nvidia подтвердила необычную функцию Multi-instance GPU у ускорителя A100. Она позволяет «разделить» графический процессор карты на семь «отдельных» GPU, каждый из которых будет заниматься отдельной задачей. Также есть возможность создания промежуточных конфигураций, но подробностей в пресс-релизе нет.
Отдельно стоит сказать пару слов и про станцию DGX A100 стоимостью 200 000 долларов, которая включает восемь ускорителей A100. Как оказалось, Nvidia для своих новых станций выбрала процессоры AMD, а не Intel, как ранее. Если точнее, DGX A100 содержит два 64-ядерных CPU Epyc 7742, а также 1 ТБ ОЗУ. Производительность станции достигает 5 PTFLOPS в задачах ИИ и 10 POPS в формате INT8.
 В «Яндекс Картах» появились более 400 готовых маршрутов для прогулок по России
В «Яндекс Картах» появились более 400 готовых маршрутов для прогулок по России Что AMD показала на Advancing AI 2026: главное о процессорах EPYC Venice Zen 6
Что AMD показала на Advancing AI 2026: главное о процессорах EPYC Venice Zen 6 Китай захватил лидерство в мировой гонке патентов на генеративный ИИ
Китай захватил лидерство в мировой гонке патентов на генеративный ИИ В Южной Австралии установят гигантский накопитель энергии Tesla Megablock емкостью 1,814 ГВт•ч
В Южной Австралии установят гигантский накопитель энергии Tesla Megablock емкостью 1,814 ГВт•ч TSMC опережает график строительства завода по производству 1,4-нм чипов на фоне задержек у Samsung
TSMC опережает график строительства завода по производству 1,4-нм чипов на фоне задержек у Samsung Роботы Xiaomi на производстве сравнялись по возможностям с людьми
Роботы Xiaomi на производстве сравнялись по возможностям с людьми Kawasaki запустит в серийное производство необычного робота-трансформера
Kawasaki запустит в серийное производство необычного робота-трансформера Oppo A7 Pro Max с батареей на 10 000 мАч и камерами по 50 Мп дебютирует 4 августа
Oppo A7 Pro Max с батареей на 10 000 мАч и камерами по 50 Мп дебютирует 4 августа