С тех пор как производство по нормам ниже 28 нм стало доступным и коммерчески оправданным для таких крупных микросхем, которыми являются дискретные графические процессоры, как AMD, так и NVIDIA заменили свою прошлую продукцию чипами нового поколения, предлагающими совершенно иное соотношение быстродействия и мощности. Однако если NVIDIA не потребовалось много времени, чтобы заполнить все эшелоны производительности ускорителями на базе архитектуры Pascal и превзойти рекорды производительности, установленные в эпоху Maxwell, то AMD сосредоточила усилия на продуктах средней и начальной ценовой категории, фактически устранившись от конкуренции в сегменте высокопроизводительной графики.
Видеокарты на основе GPU семейства Polaris хорошо проявили себя как доступный массовый продукт и помогли графическому подразделению AMD вернуть рыночные позиции, упущенные картами Radeon 300-й серии. Тем не менее, AMD изначально дала понять, что Polaris, в отличие от предшествующих архитектур, не будет развиваться в сторону больших чипов, какими были ядра Hawaii и затем Fiji в эпоху 28 нм.
Действительно, хотя Polaris выиграла в энергоэффективности от перехода на норму 14 нм FinFET, она все еще имеет много общих черт со старыми продуктами AMD (Tonga и Fiji), которые помешали столь же эффективно распорядиться преимуществами прогрессивного техпроцесса. И хотя AMD исправила положение путем оптимизации производства и схемотехники GPU во втором поколении Polaris, карты Radeon RX 500-й серии по-прежнему ограничены в потенциале тактовых частот и лишены архитектурных преимуществ, которые могли бы нарастить быстродействие в инструкциях за такт. Как микроархитектура GCN, лежащая в основе чипов AMD, так и организация блоков внутри графического процессора требовали пересмотра, и эта задача легла на грядущее семейство Vega.
Чтобы не было сомнений в том, что AMD еще вернется на рынок GPU для энтузиастов, компания заранее рассказала довольно много о том, что представляет собой Vega, а в июле выпустила ускоритель Radeon RX Vega Frontier Edition. Сегодня же мы, наконец, можем изучить массовый геймерский продукт AMD на основе кремния нового поколения — Radeon RX Vega 64.

Архитектура AMD Vega
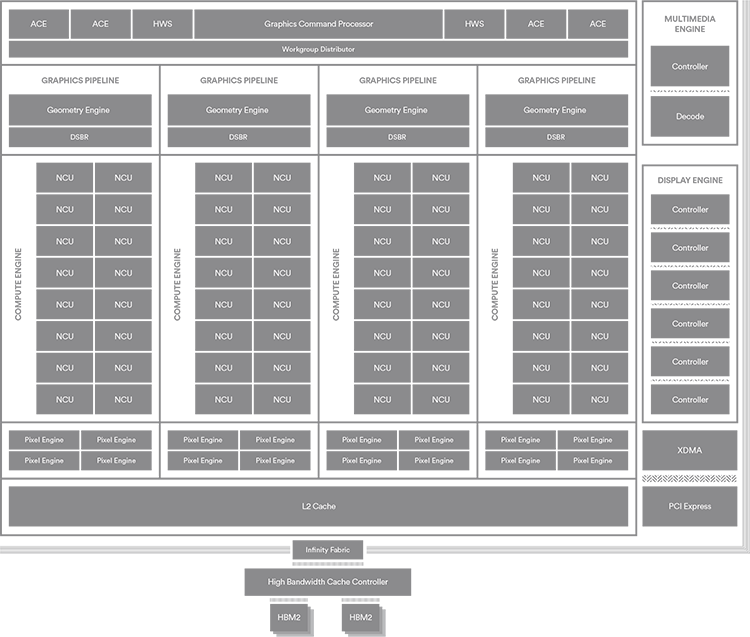
NCU — Next-generation Compute Unit
Основным строительным блоком в архитектуре Graphics Core Next является Compute Unit, который в данном случае обозначается аббревиатурой NCU (Next-generation Compute Unit). Со времен первой реализации GCN более пяти лет тому назад AMD не вносила кардинальных изменений в структуру CU. Как и в предыдущих итерациях, NCU в составе Vega по-прежнему содержит 64 шейдерных ALU, которые способны выполнить 128 операций одинарной точности (FP32) за такт. Объем кэша первого уровня и разделяемой памяти внутри NCU также остался неизменным со времен GCN 1.0. Тем не менее, если в GCN версии 1.3, к которой относятся чипы Polaris, CU лишь претерпел оптимизации, способствующие увеличению удельной производительности по сравнению с CU в GCN 1.2 (Tonga и Fiji), и две версии архитектуры даже остались совместимы на уровне ISA, разработчики Vega внедрили массу новых инструкций и форматов данных, за счет которых GCN пятого поколения можно расценивать как наиболее глубокое преобразование шейдерной микроархитектуры Graphics Core Next на сегодняшний день.
Как и Polaris, Vega может выполнять операции над вещественными и целыми числами с половинной точностью (FP16), но в Vega дополнительно появилась поддержка целочисленных операций с точностью 8, 16 и 32 бит. Что касается целочисленных форматов данных со сниженной разрядностью, то у них уже сейчас есть масса применений. К примеру, формат INT8 используется для обработки данных с помощью предварительно натренированных сетей машинного обучения (inference), а INT32 — для расчета хэшей в криптографических алгоритмах (включая майнинг криптовалют). С другой стороны, востребованность операций над вещественными числами с половинной точностью не столь очевидна. Формат FP16 широко используется для обработки шейдеров в мобильной графике, но уницифированная шейдерная модель десктопных API изначально сделала выбор в пользу FP32. Тем не менее, FP16 может со временем найти применение и в десктопной графике для тех задач, которые не требуют полной точности для сохранения качества изображения — таких как векторы нормали, значения освещенности и HDR.

Но самое главное — это то, что NCU в составе Vega способен комбинировать операции сниженной разрядности, таким образом кратно увеличивая пропускную способность. К примеру, вместо 128 операций за такт над числами FP32, которые выполняет отдельно взятый NCU, может быть выполнено 256 операций FP16 или 512 операций FP8. Единственным из прочих GPU, который наделен такой функций, на сегодняшний день является GP100 от NVIDIA. Таким образом, Vega, помимо высокопроизводительной игровой архитектуры, представляет собой универсальное решение для расчетов широкого назначения — во всем, кроме двойной точности, т.к. пропускная способность FP64 ограничена значением 1/16 от FP32.
Тайловый рендеринг и поддержка Direct3D feature level 12_1
Следующая область, в которой Vega сделала большой шаг вперед, — это пропускная способность в пикселах. Вслед за NVIDIA, AMD использует в Vega тайловый рендеринг — технологию, которая широко используется в мобильной графике и позволяет сократить количество обращений к данным, находящимся за пределами кеш-памяти GPU. Аналогично работает и механизм Draw-Stream Binning Rasterizer (DSBR) в составе Vega.
Классический тайловый рендеринг, широко распространенный в мобильных GPU, подразумевает обработку кадра в два прохода. Сначала драйвер разделяет экранное пространство на тайлы (участки с типичным размером 16 × 16 или 32 × 32 пиксела) и составляет индекс полигонов, находящихся в проекции каждого тайла. Затем последовательно в пределах каждого тайла целиком выполняется процедура рендеринга — от трансформации и пересечения полигонов до заполнения текстур и исполнения шейдеров — и конечный результат всех тайлов сшивается в единую картинку. Преимущество такого метода состоит в том, что любые промежуточные операции в пределах тайла оперируют единым массивом данных, который целиком помещается в кеш GPU, а следовательно, сокращается частота обращений к оперативной памяти.
Тем не менее, необходимость в двух проходах обработки геометрии сцены сама по себе расходует пропускную способность RAM, поскольку GPU необходимо сначала записать во внешнюю память информацию о полигонах, попадающих в тот или иной тайл, а затем, выполняя рендеринг от тайла к тайлу, извлекать ее обратно. Как следствие, эффективность тайлового рендеринга в конечном счете зависит от того, перевешивает ли экономия ПСП на скорости заполнения пикселов ее потери на двухпроходную проекцию геометрии. В мобильных приложениях, отличающихся простой геометрией, тайловый рендеринг оправдывает себя, но для современных десктопных игр лучше подходит стандартный метод мгновенного (immediate) рендеринга, при котором в едином экранном пространстве происходит последовательная растеризация одного полигона за другим.
Реализация тайлового рендеринга в чипах Maxwell/Pascal и Vega отличается. У NVIDIA отсутствует этап сортировки полигонов, т.к. трансформация геометрии происходит единым проходом. AMD, напротив, производит сортировку, но расход тактов на эту операцию снижается путем динамического выбора размера тайла и партии (batch) примитивов в зависимости от сложности конкретной сцены.
Кроме того, сортировка и группировка примитивов в партии позволяет наиболее эффективно предотвращать наложение пиксельных шейдеров на невидимые пикселы, перекрытые полигонами, ближайшими к плоскости экрана. Отдельные выборки пикселов Vega помещает в очередь, которая показывает, на какой глубине от экрана они находятся, а т.к. эта очередь имеет конечный размер, целесообразно использовать тайловый рендеринг, чтобы в пределах отдельно взятого тайла уложиться в ее пределы.

Тайловый рендеринг в чипах Vega не требует специальной поддержки со стороны приложений и активируется на уровне драйвера видеокарты. По данным внутреннего тестирования AMD, DSBR увеличивает среднюю частоту кадров в современных играх вплоть до 10%, снижает расход пропускной способности шины памяти вплоть до 33% и при этом никак не отражается на энергопотреблении GPU. В профессиональных CAD-приложениях прирост частоты смены кадров за счет DSBR может быть и двукратным.
Vega может похвастаться поддержкой возможностей, предусмотренных Direct3D уровня 12_1. Фактически, среди современных GPU Vega имеет наиболее полный набор функций, включая ряд опциональных.

Оптимизированный front-end
Чипы Polaris не испытывают острой нехватки быстродействия на ранних этапах рендеринга, однако по сравнению с конкурирующей архитектурой AMD было над чем поработать и в этой области. Vega по-прежнему содержит по одному блоку обработки геометрии на каждый Shader Engine (наиболее крупную структуру в схеме GPU, которая объединяет все стадии конвейера рендеринга), но разработчики нашли возможность увеличить предельную пропускную способность front-end’а с четырех до 17 примитивов за такт.
Для этого AMD представила альтернативный режим работы геометрического движка, в котором некоторые из стадий фиксированной функциональности были замещены программируемыми «шейдерами примитивов» — точно так же, как в чипах NVIDIA Pascal конвейер геометрии является частично программируемым. Помимо того, что шейдеры примитивов сами по себе исполняются более экономно по сравнению с аналогичными стадиями фиксированного конвейера, они позволяют отсекать невидимые примитивы на более ранних стадиях. Шейдеры примитивов в будущем можно будет задействовать для тесселяции и многих других функций, включая одновременную проекцию сцены с различных точек обзора и в различном разрешении. Пока, однако, непонятно, нужно ли для того, чтобы активировать программируемый конвейер геометрии Vega какое-либо участие со стороны движка приложений или эту функцию берет на себя драйвер.

В дополнение к непосредственной оптимизации геометрического конвейера AMD приняла меры для того, чтобы гарантировать полную загрузку движков в пределах GPU. Допонительный блок под названием Intelligent Workload Distributor (IWD) обеспечивает балансировку нагрузки между несколькими геометрическими движками, планировку операций с целью минимизировать смену контекста и группировку нескольких инстанций мелкого примитива в единой SIMD-инструкции.
High-Bandwidth Cache Controller
В составе Vega AMD представила инновационную организацию памяти, в рамках которой GPU оперирует примерно таким образом, как центральный процессор ПК. В стандартной архитектуре GPU рассматривает содержимое локальной оперативной памяти как совокупность структур, отвечающих данным различного типа, будь то текстуры, массивы вершин и т.д. Как следствие, поскольку эти структуры могут иметь большой размер, их перемещение из системой памяти в локальную память существенно снижает скорость рендеринга. Как правило, разработчики приложений стремятся зарезервировать как можно больший объем локальной памяти и держать все необходимые данные поближе к GPU, хотя есть и такие методы, как Tiled Resources, с помощью которых данные можно подгружать из системной памяти небольшими порциями (наподобие того, как работает технология Mega Texture в движках id Software).

AMD предлагает универсальный механизм работы с адресным пространством, который издавна применяется в центральных процессорах. В нем содержимое локальной и удаленной памяти вне зависимости от типа ресурса делится на «страницы» небольшого размера, которые могут быть по отдельности затребованы конвейером рендринга, перемещены или скопированы поближе или подальше от GPU. В таком случае локальная оперативная память работает как новый уровень кеша в дополнение к кешу L2.
Помимо экономии RAM, технология HBCC позволит более эффективно распоряжаться объемом Flash-памяти в ускорителях Radeon Pro и адресовать вплоть до 512 Тбайт виртуального пространства. Для потребительских устройств эта функциональность избыточна, но будет востребована в виртуализированной среде. Как бы то ни было, HBCC пока находится в активной разработке и еще недоступна в ПО для Vega. Остается открытым и такой вопрос, может ли страничный доступ к памяти работать на уровне драйвера или, напротив, приложение должно самостоятельно управлять движением ресурсов.
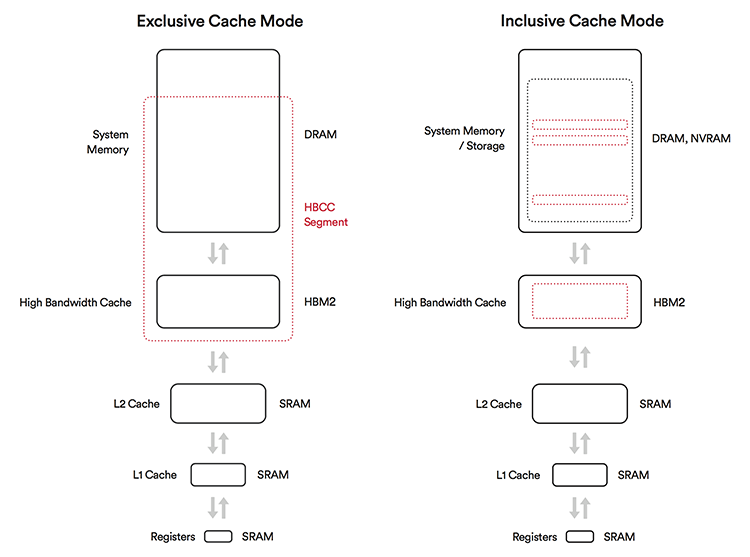
Кстати, AMD ввела дополнительные функции виртуализации, обеспечив доступ гостевых ОС (вплоть до 16 сессий) к аппаратным блокам кодирования и декодирования видеопотока. Планировкой нагрузки между тремя движками (графика/вычисления, кодирование и декодирование видео) занимается отдельный аппаратный блок.
⇡#GPU Vega 10
Единственный GPU семейства Vega, который на данный момент выпустила AMD, по конфигурации вычислительных блоков соответствует процессору Fiji: 4096 шейдерных ALU, 256 блоков наложения текстур и 64 ROP. Тем не менее, число транзисторов в чипе увеличилось с 8,9 до 12,5 млрд. В тоже время благодаря техпроцессу 14 нм FinFET площадь кристалла удалось сократить с 596 до 486 мм2. Таким образом, Vega 10 — на 72% более плотный чип, нежели Fiji, и даже по сравнению с Polaris площадь используется на 5% более эффективно.
Часть транзисторного бюджета, которым Vega 10 отличается от Fiji, израсходована удвоенный объем кеш-памяти второго уровня (4 Мбайт против 2 Мбайт в Fiji) на новые функции рендеринга, описанные выше, но львиная доля элементов, распределенных в схеме GPU, служит основой для дополнительных стадий конвейера, которые AMD пришлось внедрить с целью обеспечить стабильную работу на повышенных тактовых частотах. Однако разработчики заверили, что дополнительные стадии появились только на тех участках, где польза от высокой частоты перевешивает возросшую латентность. В противном случае использовались более изощренные методы, включая уменьшение длины внутренних соединений или полную переработу тех или иных функциональных блоков.
Регистры внутренней памяти Vega построены с применением статической памяти, изначально созданной для процессоров Ryzen, которая, согласно данным AMD, обеспечивает экономию площади в объеме 18%, снижение мощности на 43% и латентности на 8% по сравнению со стандартными решениями.
Кстати, ROP внутри Vega теперь являются клиентами кеша второго уровня, нежели контроллера памяти. Это увеличит производительность движков отложенного рендеринга, поскольку результат отдельного прохода будет записан непосредственно в L2 вместо оперативной памяти и будет немедленно доступен текстурным модулям для следующих операций.
Для коммуникаций внутри чипа между собственно GPU и uncore-компонентами (контроллером RAM, шины PCI Express, мультимедийным блоком и т.д.) Vega использует интерфейс Infinity Fabric, который также является частью процессоров архитектуры Zen. Благодаря ей AMD в будущем сможет с легкостью интегрировать ядро Vega в APU нового поколения.
Блок декодирования видеопотока в составе Vega не приобрел новых функций по сравнению с Polaris. Он по-прежнему выполняет расшифровку форматов H.264 и H.265 при разрешении вплоть до 3840 × 2160 с кадровой частотой 120 Гц, однако AMD внесла ясность в вопрос аппаратной поддержки кодека VP9, которая впервые была заявлена для Polaris, но не реализована в драйвере вплоть до сегодняшнего дня. Оказывается, Vega использует гибридный метод, комбинируя ресурсы выделенного блока, шейдерных ALU и центрального процессора.
А вот блок кодирования в Vega приобрел возможность записывать видео в формате H.264 в 4К-разрешении с частотой 60 Гц, в то время как Polaris был ограничен частотой 30 Гц.
В Vega вновь используется память типа HBM, но поскольку вторая версия технологии позволяет выпускать сборки объемом вплоть до 8 Гбайт, AMD одновременно получила возможность увеличить объем локальной памяти GPU и упростить конструкцию за счет меньшего числа микросхем и упрощенной разводки соединений. Кремниевая подложка Vega 10 объединяет кристалл GPU с двумя сборками HBM2 по 4 Гбайт 2048-битной шиной, но за счет практически удвоенной частоты HBM2 процессор сохранил «сырую» пропускную способность памяти, сопоставимую с характеристиками Fiji.

⇡#Технические характеристики, комплект поставки, цена
AMD представила три ускорителя на основе Vega 10, не считая Radeon RX Vega Frontier Edition. Топовой моделью в семействе является Radeon RX Vega 64, доступная в вариантах с воздушным кулером и системой жидкостного охлаждения. Число в названии указывает на 64 активных NCU в составе полностью разблокированного чипа. Поскольку Radeon R9 Fury X обладает такой же конфигурацией, дополнительную производительность RX Vega, помимо оптимизации конвейера, извлекает из более высоких тактовых частот.
Базовая частота GPU в Radeon RX Vega 64 с воздушным охлаждением составляет 1247 МГц, и это не очень воодушевляет, если сравнивать с базовой частотой GeForce GTX 1080 Ti (который основан на GPU сопоставимого размера и даже на 500 млн транзисторов меньше). Тем не менее, boost-частоты у двух видеокарт вполне сопоставимы — 1546 и 1582 МГц соответственно. К тому же, в случае Vega AMD вкладывает иной смысл в понятие boost clock. Вместо максимальной частоты, которая разрешена для GPU число означает максимальную частоту, которой ядро может гарантированно достигнуть в играх, но истинный предел лежит еще выше. Таким образом, AMD и NVIDIA теперь оперируют похожими показателями, что облегчает сравнение видеокарт по их спецификациям, хотя NVIDIA все-таки подразумевает под boost clock некое среднее, а не пиковое значение, которое наблюдается в играх.
Radeon RX Vega 64 Liquid Cooled Edition по заявленным частотам уже вполне соответствует GeForce GTX 1080 Ti, но давайте посмотрим на энергопотребление новинок: если даже «воздушная» версия Radeon RX Vega 64 превышает по мощности типичные для топовых потребительских видеокарт 250 Вт, то мощности Liquid Cooled Edition достигает совершенно безумных с позиции одночипового ускорителя 345 Вт.
Принимая во внимание масштаб оптимизаций, которые содержит Vega 10, размеры чипа и его мощность, было бы логично ожидать от Radeon RX Vega 64 производительности на уровне GeForce GTX 1080 Ti или выше. По крайней мере, по теоретической пропускной способности операций FP32 Radeon RX Vega 64 опережает топовый ускоритель конкурента. Но судя по ценам, AMD не столь уверена в потенциале своего флагмана. Действительно, версия с воздушным охлаждением поступит в продажу по рекомендованной цене $499 — аналогично GeForce GTX 1080. Рекомендованная цена Radeon RX Vega 64 Liquid Cooled Edition — $699, что соответствует текущей цене GeForce GTX 1080 Ti.
| Производитель | AMD | |||||
| Модель | Radeon R9 Fury X | Radeon RX 580 | Radeon RX Vega 64 Frontier Edition | Radeon RX Vega 56 | Radeon RX Vega 64 | Radeon RX Vega 64 Liquid Cooled Edition |
| Графический процессор | ||||||
| Название | Fiji XT | Polaris 20 XTX | Vega 10 XT | Vega 10 XL | Vega 10 XT | Vega 10 XT |
| Микроархитектура | GCN 1.2 | GCN 1.3 | GCN 1.4 | GCN 1.4 | GCN 1.4 | GCN 1.4 |
| Техпроцесс, нм | 28 нм | 14 нм FinFET | 14 нм FinFET | 14 нм FinFET | 14 нм FinFET | 14 нм FinFET |
| Число транзисторов, млн | 8900 | 5700 | 12 500 | 12 500 | 12 500 | 12 500 |
| Тактовая частота, МГц: Base Clock / Boost Clock | —/1050 | 1257/1340 | 1382/1600 | 1156/1471 | 1247/1546 | 1406/1677 |
| Число шейдерных ALU | 4096 | 2304 | 4096 | 3584 | 4096 | 4096 |
| Число блоков наложения текстур | 256 | 144 | 256 | 256 | 256 | 256 |
| Число ROP | 64 | 32 | 64 | 64 | 64 | 64 |
| Оперативная память | ||||||
| Разрядность шины, бит | 4096 | 256 | 2048 | 2048 | 2048 | 2048 |
| Тип микросхем | HBM | GDDR5 SDRAM | HBM2 | HBM2 | HBM2 | HBM2 |
| Тактовая частота, МГц (пропускная способность на контакт, Мбит/с) | 500 (1000) | 2000 (8000) | 945 (1890) | 800 (1600) | 945 (1890) | 945 (1890) |
| Объем, Мбайт | 4096 | 4096/8192 | 8096 | 8096 | 8096 | 8096 |
| Шина ввода/вывода | PCI Express 3.0 x16 | PCI Express 3.0 x16 | PCI Express 3.0 x16 | PCI Express 3.0 x8 | PCI Express 3.0 x8 | |
| Производительность | ||||||
| Пиковая производительность FP32, GFLOPS (из расчета максимальной указанной частоты) | 8602 | 6175 | 13107 | 10544 | 12665 | 13738 |
| Производительность FP32/FP64 | 1/16 | 1/16 | 1/16 | 1/16 | 1/16 | 1/16 |
| Пропускная способность оперативной памяти, Гбайт/с | 512 | 256 | 484 | 410 | 484 | 484 |
| Вывод изображения | ||||||
| Интерфейсы вывода изображения | HDMI 1.4a, DisplayPort 1.2 | HDMI 2.0, DisplayPort 1.3/1.4 | HDMI 2.0, DisplayPort 1.4 | HDMI 2.0, DisplayPort 1.4 | HDMI 2.0, DisplayPort 1.4 | HDMI 2.0, DisplayPort 1.4 |
| TDP, Вт | 275 | 185 | <300 | 210 | 295 | 345 |
| Розничная цена (США, без налога), $ | 649 (рекомендованная на момент выхода) | 199/229 (рекомендованная на момент выхода) | 999/1499 (рекомендованная на момент выхода) | 399 (рекомендованная на момент выхода) | 499 (рекомендованная на момент выхода) | 699 (рекомендованная на момент выхода) |
| Розничная цена (Россия), руб. | НД | 13 449 / 15 299 (рекомендованная на момент выхода) | НД | НД | НД | НД |
⇡#AMD Radeon RX Vega 64: конструкция


Источник: 3DNews


