![[Перевод] Какой предел у предсказателя ветвлений? Проверили на x86 и M1](https://habrastorage.org/webt/ub/bm/-t/ubbm-tkeiuk9bqg8cihmnpx5xs8.png "[Перевод] Какой предел у предсказателя ветвлений? Проверили на x86 и M1")
Некоторое время назад я смотрел на высоконагруженную часть кода и обратил внимание на это:
if (debug) {
log("...");
}
И тут я задумался. Это — часть цикла, от которого требуется высокая производительность, но этот фрагмент выглядит как пустая трата времени, ведь мы никогда не устанавливаем флаг отладки. Нормально ли иметь в коде условные операторы, которые никогда не выполняются? Уверен, это влияет на производительность программы…
Насколько плохо использовать избыточное количество условных операторов?
В те времена основное правило звучало так: полностью предсказанное ветвление практически не имеет дополнительных затрат процессорного времени.
Но насколько это правда? Для одного условного оператора — точно, а как насчет десяти? А сотни? Или даже тысячи? Где граница, когда добавление еще одного условного оператора становится плохой идеей?
В какой-то момент пренебрежительно малая стоимость простых инструкций условного перехода начинает быть заметной. В качестве примера коллега нашел вот такой фрагмент кода, который используется в продакшне:
const char *getCountry(int cc) {
if(cc == 1) return "A1";
if(cc == 2) return "A2";
if(cc == 3) return "O1";
if(cc == 4) return "AD";
if(cc == 5) return "AE";
if(cc == 6) return "AF";
if(cc == 7) return "AG";
if(cc == 1) return "AI";
...
if(cc == 252) return "YT";
if(cc == 253) return "ZA";
if(cc == 254) return "ZM";
if(cc == 255) return "ZW";
if(cc == 256) return "XK";
if(cc == 257) return "T1";
return "UNKNOWN";
}Конечно, этот код может быть оптимизирован. Но потом я задумался: нужно ли его оптимизировать? Будет ли снижение производительности от большого количества простых переходов?
Стоимость перехода
Начнем с теории. Сперва нам необходимо разобраться, как изменяется время выполнения условного перехода в зависимости от количества этих переходов. Как оказалось, оценить время выполнения одного ветвления не так просто. На современных процессорах ветвление занимает от одного до двадцати тактов.
Существует по крайней мере четыре вида инструкций, которые влияют на поток выполнения программы:
- безусловный переход (jmp на x86),
- call/return,
- переход при выполнении условия (je на x86),
- переход при невыполнении.
Переход при выполнении условия особенно проблематичен, так как он может занять много процессорного времени. Для снижения временных затрат современные процессоры пытаются «предсказать будущее» и выбрать правильную ветвь кода до того, как условие будет вычислено. Этим занимается специальная часть процессора, которая называется предсказатель ветвлений (Branch Predictor Unit, BPU).
Предсказатель ветвлений пытается спрогнозировать результат условия для перехода в условиях малого количества информации. Эта «магия» происходит до этапа декодирования инструкции, поэтому у предсказателя есть только адрес инструкции и небольшая история предыдущих вычислений. Если подумать, то это очень круто. Имея только адрес инструкции предсказатель с высокой вероятностью угадывает результат условного перехода.

Источник
Предсказатель имеет несколько структур данных, но сегодня мы рассмотрим Branch Target Buffer (BTB). В этой структуре предсказатель хранит адреса условных операторов, которые уже были выполнены. В целом механизм намного сложнее, более подробно можно ознакомится в магистерской диссертации Владимира Юзелаца (Vladimir Uzelac) на примере процессоров 2008 года.
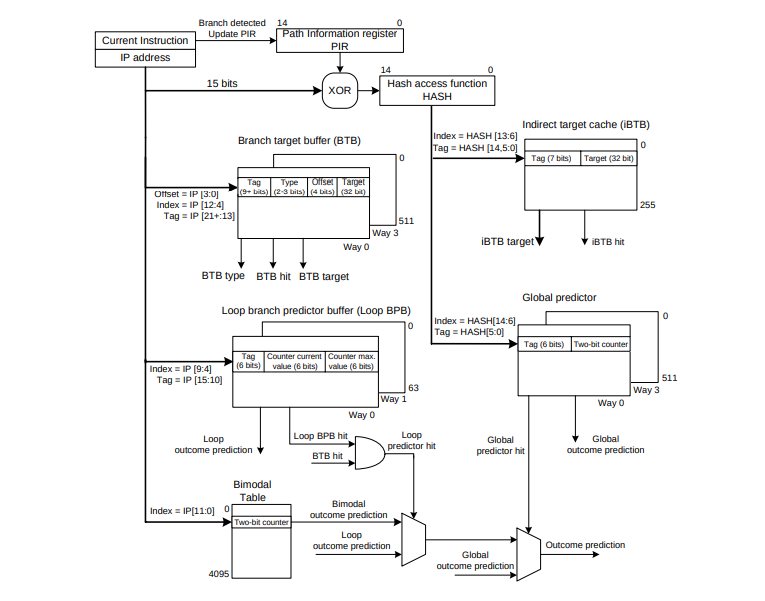
В данной статье мы рассмотрим как BTB ведет себя в разных условиях.
Зачем нужно прогнозировать переходы?
Давайте определимся, зачем нужно предсказание переходов. Для достижения максимальной производительности конвейер центрального процессора постоянно должен быть заполнен. Рассмотрим, что происходит с многоступенчатым конвейером в случае условного перехода на примере следующей ARM-программы.
BR label_a;
X1
...
label_a:
Y1В упрощенной модели процессора операции будут проходить через конвейер следующим образом:

В первую очередь происходит выборка инструкции BR. Это — безусловный переход, изменяющий поток выполнения. В это время инструкция перехода еще не декодирована, поэтому процессор производит выборку следующей инструкции. Без предсказателя ветвления на втором такте блок выборки команды либо должен ожидать декодирования, либо переходить к следующей, в надежде, что она окажется правильной.
В нашем случае инструкция X1 пройдет выборку, даже несмотря на то, что это не та инструкция, которая должна быть выполнена следующей. На четвертом такте, когда операция перехода будет выполнена, процессор осознает ошибку и отбросит все предполагаемые инструкции, которые начали выполняться. В этот момент начнется выборка правильной инструкции, то есть Y1 в нашем случае.
Ситуация с потерей пары тактов из-за выборки не тех инструкций называется «пузырем». У нашего теоретический процессора появился «пузырь» на два такта из-за ошибки в предсказании.
В этом примере мы видим, что процессор в итоге выполняет правильные инструкции, но без хорошего прогнозирования ветвлений он тратит время на обработку неправильных инструкций. В прошлом использовались различные техники, такие как статическое предсказание и задержки. В современных процессорах используются динамические предсказания. Этот метод позволяет избегать «пузырей», предсказывая правильный адрес следующей инструкции даже для инструкций, которые еще не декодированы.
Играем с BTB
Как мы говорили ранее, сегодня мы рассмотрим Branch Target Buffer — структуру данных, которая отвечает за определение следующего адреса после ветвления. Важно отметить, что BTB независим от системы, которая оценивает результат ветвления. Помните, мы хотим узнать, увеличивается ли время выполнения переходов при увеличении их количества.
Подготовить эксперимент, который создает нагрузку только на BTB относительно просто. В основе этого теста лежит работа Мэтта Годболта (Matt GodBolt). Оказывается, достаточно последовательности безусловных переходов. Рассмотрим следующий x86 код:

Это код состоит из последовательности инструкций jmp +2 (то есть буквально безусловный переход на следующую инструкцию), что создает значительную нагрузку на BTB. Для того, чтобы избежать «пузырей», каждый переход требует правильного ответа от BTB. Такое предсказание ветвления должно происходить в самом начале конвейера до завершения декодирования команды. Этот механизм также необходим для любого ветвления, вне зависимости от его типа.
Приведенный выше код запущен в тестовой системе, которая измеряет, сколько тактов было затрачено на каждую инструкцию. Например, в данном тесте мы запускаем одну за другой 1024 двухбайтовые инструкции jmp.

Мы провели подобный эксперимент для нескольких разных процессоров. В примере выше использовался процессор AMD EPYC 7642. В первый «холодный» запуск выполнение инструкции jmp занимало в среднем 10.5 тактов, а во все последующие запуски — примерно 3.5 такта. Код теста составлен так, чтобы быть уверенным, что именно BTB тормозит первый запуск. Если взглянуть на исходный код, то можно увидеть некоторую магию с прогревом кэшей L1 и i-TLB без использования BTB.
Замечание 1. На данном процессоре инструкция перехода без предсказания занимает примерно на 7 тактов больше, чем инструкция перехода с предсказанием. Даже в случае безусловного перехода.
Плотность имеет значение
Чтобы получить полную картину, следует задуматься о плотности jmp-инструкций в коде. Например, в коде выше на блок в 16 байт приходится 8 переходов. Это очень много. Следующий код содержит одну инструкцию на каждые 16 байт. Обращаем внимание, что инструкции nop «перепрыгиваются». Размер блока не влияет на количество выполненных инструкций, только на плотность кода.

Изменение размера блока может быть очень важным. Это позволяет нам контролировать размещение инструкций jmp. Напомним, что BTB индексируется по адресу инструкции. Значение указателя и выравнивание могут повлиять на размещение в BTB и помочь нам разобраться в его строении. Выравнивание может привести к необходимости добавить дополнительные nop. Последовательность из измеряемой инструкции jmp и последующих nop я буду называть блоком. Важно, что при увеличении размера блока увеличивается размер исполняемой программы. При больших значениях размера блока можно заметить просадку по производительности, которая связана с исчерпанием места в L1-кэше.
Эксперимент
Наш эксперимент призван продемонстрировать снижение производительности в зависимости от количества ветвления при разном размере исполняемой программы. Надеюсь, мы сможем доказать, что производительность в основном зависит от количества блоков и, следовательно, от размера BTB, а не от размера рабочего кода.
Взгляните на код в нашем GitHub. Если вы захотите увидеть сгенерированный машинный код, то вам придется выполнить специальную команду. Вот пример заклинания для gdb:

Двигаемся далее: что если мы возьмем лучшее время каждого прогона с заполненным BTB для разных значений размера блока и количества блоков? Получается так:
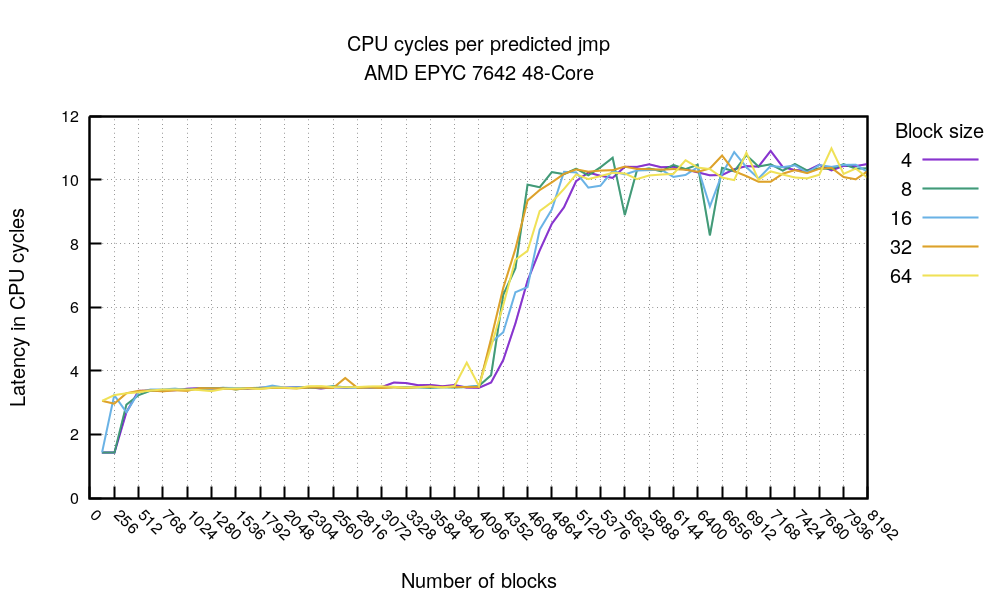
Это потрясающий график. Во-первых, очевидно, что что-то происходит на отметке 4096 блоков вне зависимости от размера блока. Проговорим еще раз.
- В самой левой части мы видим, что код достаточно мал — меньше 2048 байт. Это позволяет уместиться в каком-то кэше и получить примерно 1.5 тактов на инструкцию при полностью спрогнозированном ветвлении. Великолепно.
- С другой стороны, если ваш высоконагруженный цикл будет состоять не более, чем из 4096 переходов, то вне зависимости от плотности кода вы получите примерно 3.4 такта на каждый успешно предсказанный переход.
- Если переходов больше 4096, то предсказатель ветвления выходит из игры и каждый переход станет занимать до 10.5 тактов. Это совпадает с тем, что мы видели раньше: переход без предсказания занимает около 10.5 тактов.
И что же это значит? Это значит, что вам следует избегать инструкций ветвления, если вы хотите уменьшить промахи в предсказании, так как BTB имеет только 4096 быстрых ячеек. Впрочем, это не самый полезный совет, ведь мы не специально помещаем столько безусловных переходов в код.
Есть пара выводов по обсуждаемому процессору. Я повторил эксперимент с последовательностью условных переходов, которые всегда выполняются. Получившаяся диаграмма выглядит почти идентичной. Единственная разница заключается в том, что условный переход je на два такта медленнее, чем безусловный jmp.
Каждый переход записывается в BTB, как только он совершается. Неважно, это всегда выполняющийся условный переход или безусловный, он всегда будет занимать ровно одну ячейку в BTB. Для достижения высокой производительности нужно убедиться, что в вашем высокопроизводительном цикле количество переходов не превышает 4096. Хорошая новость заключается в том, что условный переход, который никогда не выполняется, не занимает места в BTB. Мы можем это доказать следующим экспериментом:
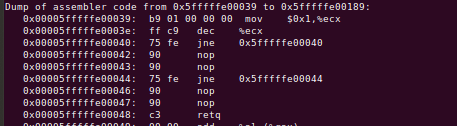
Этот скучный код перебирает jne, за которым следуют два nop (размер блока — 4). С помощью этого теста (jne никогда не выполняется), предыдущего (jmp всегда выполняется) и всегда выполняющегося перехода je мы можем нарисовать следующую диаграмму:

Во-первых, мы видим, что всегда выполняющийся условный переход je занимает больше времени, чем безусловный jmp, но это заметно только при количестве переходов больше 4096. Это ожидаемо, так как условие решается позже в конвейере, что создает «пузырь». Далее, взгляните на синюю линию, которая чуть выше нуля. Это условный переход jne, который никогда не выполняется и занимает 0.3 такта на блок вне зависимости от количества блоков. Вывод очевиден: у вас может быть сколько угодно ветвлений, которые никогда не используются и это вам практически ничего не будет стоить. На отметке 4096 скачка нет, а значит, что BTB в данном случае не используется. Кажется, что для условных переходов, о которых нет информации, всегда делается предсказание о невыполнении условия.
Замечание 2. Условные переходы, которые никогда не выполняются, практически бесплатны. По крайней мере на этом процессоре.
Пока мы установили, что всегда исполняемые инструкции ветвления занимают BTB, а никогда не исполняемые — нет. А как насчет других инструкций, например, call?
Мне не удалось найти этого в литературе, но кажется, что call и ret также занимают место в BTB для повышения производительности. Я смог продемонстрировать это на нашем AMD EPYC. Давайте посмотрим на следующий тест:

На этот раз вызовем несколько инструкций callq, каждая из которых должна быть полностью предсказанной. Эксперимент построен так, что каждый callq вызывает уникальную функцию, которая содержит retq. Один возврат соответствует одному вызову.
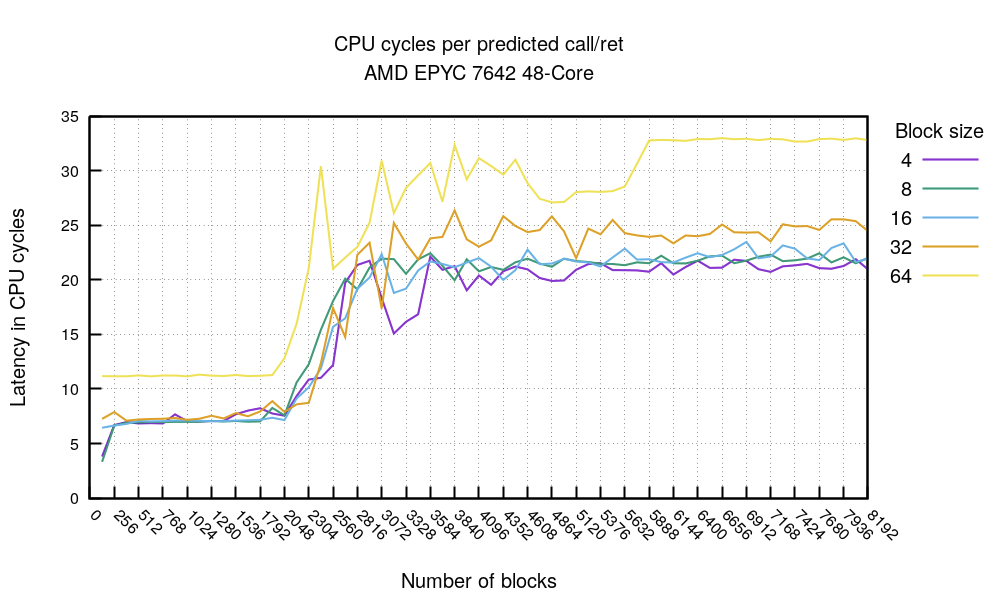
Этот график подтверждает теорию: вне зависимости от плотности кода (исключение: блок 64 байта значительно медленнее) стоимость операций начинает увеличиваться после отметки 2048. На этой отметке BTB заполняется предсказаниями call и ret и не может хранить больше данных. Из этого следует важное заключение:
Замечание 3. В вашем высоконагруженном коде должно быть меньше двух тысяч вызовов функций, по крайней мере на этом процессоре.
На нашем тестовом процессоре последовательность полностью предсказанных вызовов и возвратов занимает около 7 циклов, что примерно равно двум безусловным переходам jmp. Это согласуется с результатами выше.
Мы тщательно протестировали AMD EPYC 7642. Мы начали с этого процессора, так как предсказатель ветвления оказался прост, а диаграммы — понятны. Оказалось, что на новых процессорах все не так просто.
AMD EPYC 7713
Новое поколение AMD EPYC более сложное, чем предыдущие. Давайте проведем два самых важных эксперимента. Во-первых, jmp:

Для случая всегда истинных условий мы можем видеть хорошие тайминги, менее одного такта, когда количестве переходов не превышает 1024.
Замечание 4. На данном процессоре можно получить переходы за менее, чем 1 такт, когда высоконагруженный цикл занимает меньше 32 КиБ.
Затем, после отметки 4096 начинается некоторый шум. А после отметки в 6000 переходов падение скорости замедляется. Мы можем предположить, что за этим пределом срабатывает иной механизм прогнозирования, который поддерживает производительность на одном уровне.

Вызовы call/ret показывают примерно тоже самое. Предсказания после отметки в 2048 блоков начинают ухудшаться, а за пределами 3000 блоков вообще не срабатывают.
Xeon Gold 6262
Процессор Intel показывает совершенно другие результаты:
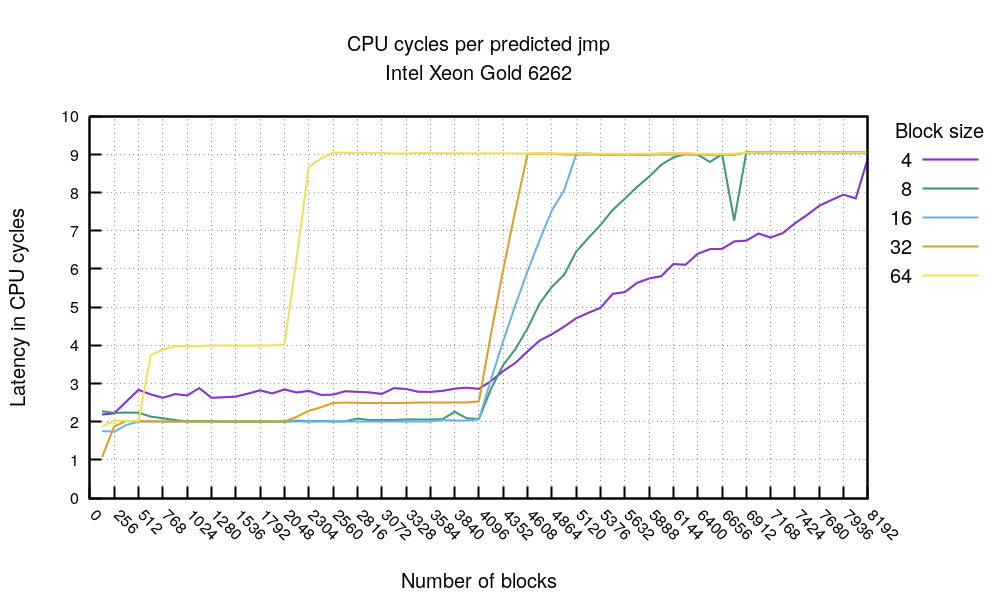
Наш тест показывает, что предсказанный выполняющийся переход занимает два такта. Intel задокументировала снижение тактовой частоты при высокой плотности ветвления. Это объясняет, что линия для 4-байтового блока колеблется около отметки в 3 такта. Рост количества циклов на инструкцию начинается на 4096 блоках, что подтверждает теорию о том, что Intel BTB содержит 4096 ячеек.
График с размером блока 64 байта выглядит непонятным, но легко объясняется. Стоимость операции ветвления остается неизменной до 512 операций, а затем начинает расти. Это объясняется внутренним устройством BTB, которое называется 8-way associative. Похоже, что с размером блока 64 байта мы можем использовать максимум половину из 4096 ячеек BTB.
Замечание 5. На процессорах Intel избегайте расположения jmp/call/ret на интервалах по 64 байта.
Наконец график call/ret:
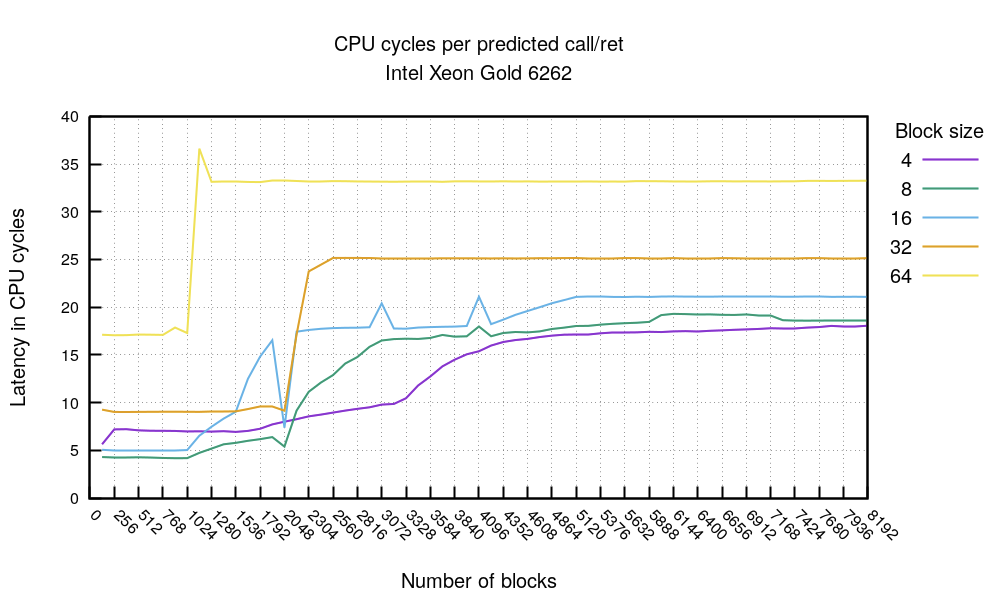
Точно так же можно видеть, что предсказания ветвления перестают работать после отметке в 2048 инструкций. В этом эксперименте один блок использует две инструкции — call и ret. Это еще раз подтверждается, что размер BTB составляет 4k. Блок размером 64 байта обычно медленнее, из-за наполнения nop, но в нем предсказатель начинает ломаться раньше из-за проблем с выравниванием инструкций. Обратите внимание, что такого эффекта не наблюдалось на процессорах AMD.
Apple Silicon M1
До сих пор мы рассматривали процессоры серверного сегмента. А как Apple Silicon M1 вписывается в эту картину?
Мы ожидаем, что результаты будут совсем другими, ведь он разработан для мобильных устройств и использует архитуктуру ARM64. Давайте посмотрим на наши два эксперимента:

Тест с предсказанными jmp показывает интересные вещи. Во-первых, когда код помещается в 4096 байт (1024 * 4, 512 * 8 и так далее), то вы можете ожидать, что jmp будет выполняться за 1 такт. Это замечательно.
Помимо этого, вы можете ожидать, что jmp выполнится за три такта. Это тоже очень хорошо. Ухудшения начинаются, когда размер кода превышает 200 КиБ. Это видно на графике с размером блока 64 на отметке 3072 (3072 * 64 = 196 КиБ) и на отметке 6144 при размере блока 32 (6144 * 32 = 196 КиБ). В документации указано, что L1-кэш инструкций процессора имеет размер 192 КиБ. Наш эксперимент это подтверждает.
Давайте сравним предсказанные переходы с непредсказанными. Но относитесь к этому графику скептически, так как полностью отказаться от предсказателя ветвления сложно.
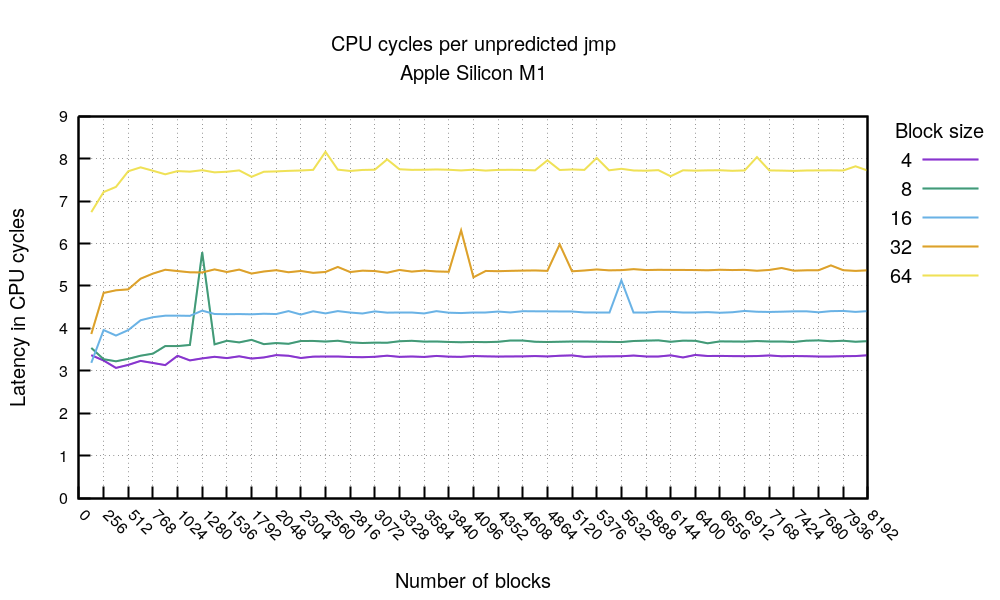
Однако, если мы не доверяем коду flush-bpu (адаптированному коду Мэтта Годболта), эта диаграмма показывает две вещи. Во-первых, стоимость перехода без предсказания коррелирует с расстоянием перехода. Чем длиннее прыжок, тем он дороже. Мы не наблюдали такого поведения на процессорах x86.
Мы видели, сколько стоят последовательности предсказанных и не предсказанных переходов. На первом графике мы видим, что при превышении размера в 192 КиБ предсказатель ветвлений становится неэффективным. В эксперименте с якобы отключенным предсказателем мы видим те же значения. Например, для блока в 64 байта безусловный переход jmp занимает 3 такта. В случае, если предсказатель не сработал, то 8 тактов. Для большого объема кода безусловный переход занимает 8 тактов. Получается, что BTB соединен с L1 кэшем. Пол Клэйтон (Paul A. Clayton) предположил возможность такой архитектуры еще в 2016.
Замечание 6. На M1 предсказанные переходы занимают обычно 3 такта, а не предсказанные зависят от расстояния, на которое происходит переход. Вероятно, что BTB связан с L1-кэшем.
График call/ret получился забавным:
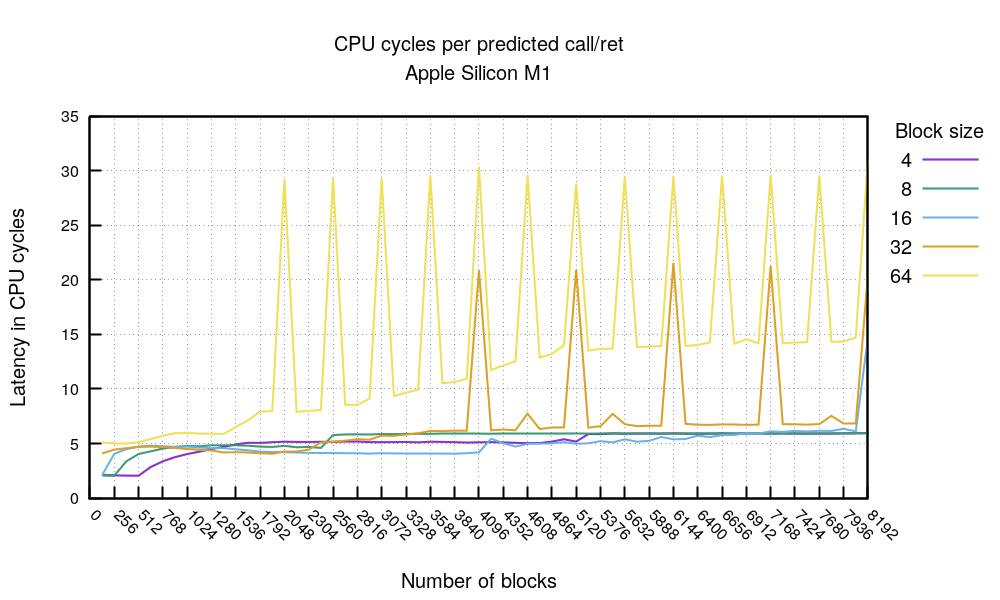
Как и в предыдущем графике, мы можем видеть значительный прирост производительности, если укладываемся в 4096 байт. В противном случае мы можем рассчитывать на 4-6 тактов на последовательность call/ret. На графике можно видеть забавные проблемы, связанные с выравниванием в памяти. Причина этих проблем не установлена. Сравнение этого графика с аналогичными для x86 может быть некорректным, так как инструкция call значительно отличается от варианта для x86.
M1 выглядит достаточно быстрым, особенно с предсказанными переходами, которые выполняются за 3 такта. В нашем тесте переходы перед предсказаниями не выполнялись дольше 8 тактов. А последовательность call + ret для кода с высокой плотностью должна соответствовать пяти тактам.
Заключение
Мы начали эту статью с кусочка обычного кода и задали простой вопрос: как влияет на производительность добавление условных операторов, который никогда не выполняются?
Затем мы быстро разобрались в некоторых низкоуровневых особенностях процессоров. Надеюсь, к концу этой статьи проницательный читатель сможет лучше понять устройство современных предсказателей ветвлений.
На x86 код должен распределить бюджет BTB между вызовами функций и условными переходами. BTB имеет размер всего в 4096 записей. Код, критичный к производительности должен быть меньше 16 КиБ, чтобы получить серьезное преимущество благодаря использованию BTB.
С другой стороны, на M1 выглядит так, как будто BTB ограничен размером кэша L1. Но если вы пишите максимально производительный код, то он в идеале должен быть меньше 4 КиБ.
Наконец, можете ли вы добавить еще один условный оператор: Если он никогда не будет исполняться, то да, может. Я не нашел доказательств того, что такое ветвление требует дополнительных затрат. Но всегда избегайте вызовов функций и условных переходов, которые всегда выполняются.
Источники
Я не первый человек, который изучал, как работает BTB. Мои эксперименты основаны на следующих материалах:
- Магистерская диссертация Владимира Юзелаца (Vladimit Uzelac).
- Работа Мэтта Годболта (Matt Godbolt). Серия из пяти статей.
- Вопросы Трэвиса Даунса (Travis Downs) на Real World Tech.
- Различные обсуждения на stackoverflow. В особенности это и это.
- В руководстве по микроархитектуре Агнера Фога (Agner Fog) есть хороший раздел, посвященный предсказателю ветвлений.



