
Окружающий нас мир состоит из множества разнообразных стимулов, которые мы воспринимаем с помощью совестной работы наших органов чувств и мозга. Совокупность этой сенсорной информации позволяет нам формировать картину окружающей среды. Физиологические системы, задействованные в этом процессе, весьма сложны, и порой нам понятно что они делают, но не всегда понятно как. Ученые из Астонского университета (Великобритания) провели любопытное исследование, в котором попытались объяснить, как зрительная система человека воспринимает масштаб. Ученые провели ряд практических испытаний, в ходе которых испытуемые должны были верно определить, изображен ли на фото реальный поезд или его модель в масштабе 1:76. Как испытуемые справились с задачей, и какие выводы можно сделать из результатов? Ответы на эти вопросы мы найдем в докладе ученых.
Основа исследования
Визуальное восприятие человека начинается с плоского (двумерного) изображения, из которого необходимо извлечь встроенное третье измерение. Мы легко можем судить о масштабе (физическом размере зерна) новых сред и отношений глубины внутри них, даже если они не содержат знакомых объектов. Но есть вопрос — как получить необходимые оценки относительной и абсолютной глубины?
Для выполнения этой задачи доступно множество визуальных подсказок. Как известно, градиенты различных мер изображения обеспечивают ценный источник количественной информации о трехмерном мире. Один важный класс признаков глубины (далее «класс 1») включает в себя те изобразительные признаки, для которых соответствующие меры изображения уменьшаются по направлению к точке схода на горизонте, независимо от того, какая часть сцены фиксируется (например, линейная перспектива, градиенты размера и текстуры, высота в поле зрения). Этот класс признаков часто используется художниками, чтобы передать глубину на двумерном изображении.
При соответствующих условиях просмотра хорошо построенные изображения могут производить убедительное впечатление глубины (например, картины Виктора Вазарели), сравнимое с тем, которое достигается с помощью бинокулярного стереопсиса и параллакса движения.

Картина Виктора Вазарели «Vega-Lep», 1970 год.
Эти признаки перспективы могут предоставить ценную информацию об относительной глубине (например, один объект находится в два раза дальше, чем другой), но не дают информации об абсолютной глубине (расстоянии) или масштабе. Например, текстура и признаки линейной перспективы в реальной сцене идентичны таковым в мелкомасштабной модели этой сцены. Чтобы проблема масштаба была решена, должна быть оценка абсолютной глубины хотя бы для одной точки сцены. Этот принцип очень давно используется в кинематографе, когда якобы огромные объекты на самом деле являются моделями гораздо меньшего масштаба.
К примеру, в фильме “Матрица: Революция” для эпической сцены защиты Зиона от машин использовались модели (миниатюрами их сложно назвать, но они все же были намного меньше того, что мы видим в самом фильме).
Второй класс признаков глубины (класс 2) — это те, для которых соответствующие измерения изображения уменьшаются по направлению к точке статической фиксации (горизонтальное бинокулярное несоответствие, параллакс движения) и/или к фокусу (расфокусированное размытие). Взятые по отдельности, эти сигналы еще беднее, чем сигналы класса 1, и предоставляют только порядковую информацию. Например, один объект находится дальше, чем другой — мы также знаем относительное расстояние двух объектов до гороптера*. Но, поскольку мы не знаем, где это все, это не очень полезная информация. Но в сочетании с информацией о расстоянии до точки фиксации, по которой можно судить о глубине всего остального, они становятся гораздо более ценными и могут использоваться для восстановления абсолютной глубины сцены.
Гороптер* — область пространства перед наблюдателем, все точки которой не видятся двоящимися, так как данные точки дают изображения в парных идентичных местах сетчатки, то есть в корреспондирующих точках.
Однако проблема здесь в том, что вся стратегия критически зависит от предполагаемого расстояния до точки фиксации. Эта задача традиционно приписывается зрительно-моторным сигналам аккомодации и угла вергенции*, но это очень плохие показатели дальше 2-3 метров.
Вергенция* — одновременное движение обоих глаз в противоположных направлениях, чтобы получить или сохранить целостное бинокулярное зрение.
Другой возможностью является использование вертикальной диспаратности, но для этого необходимо большое поле зрения поверхности. Осведомленность (например, мы знаем примерные габариты среднестатистического человека) может быть использована для решения проблемы, но во фрактальных сценах (например, берег моря) знакомые объекты не всегда можно найти.
Ранее ученые показали, что пересечение ограничений (IOC от intersection of constraints) между сигналами класса 1 и класса 2, описанными выше, может использоваться для вычисления информации об абсолютной глубине. Эта математическая работа была направлена на признак класса 2 размытия расфокусировки, но, поскольку основная математика идентична той, что используется для горизонтального бинокулярного несоответствия и параллакса движения, ее последствия могут быть распространены на все три признака 2 класса. Возникает естественный вопрос: способно ли человеческое зрение использовать этот тип анализа изображения для оценки масштаба?
Демонстрация так называемой миниатюризации со сдвигом наклона, когда добавление искусственных градиентов размытия к (тщательно отобранным) естественным сценам уменьшает их воспринимаемый масштаб, предполагает, что зрительная система может что-то делать в этом направлении. Причина того, что расфокусированное размытие служит признаком глубины, заключается в том, что устройства обработки изображений (включая глаза) имеют ограниченную глубину резкости: объекты в плоскости фокуса отображаются резко, а объекты и поверхности, находящиеся ближе или дальше, размыты. Выраженность размытия расфокусировки увеличивается линейно с расстоянием от плоскости фокусировки, создавая градиенты размытия по всему изображению. И поскольку размытие изображения зависит от глубины, его, в принципе, можно использовать для его же восстановления. Фактически, эксперименты показали, что человеческое зрение может использовать градиент размытия при оценке порядковой глубины или наклона поверхности. Кроме того, глубина резкости уменьшается по мере того, как фокальная плоскость перемещается вперед в сцене. Это означает, что при этом расфокусированное размытие увеличивается быстрее по мере удаления от фокальной плоскости.
Ученые отмечают, что подобного рода исследования уже проводились ранее, однако их результаты были весьма неточными. Потому они решили повторить их, но применив новый подход. Было решено, что центральным вопросом является восприятие масштаба, а потому нужно ценить именно его напрямую. Одним из преимуществ этого подхода является то, что оценки масштаба включают суждения обо всем изображении. Поэтому можно ожидать, что этот метод будет более надежным, чем оценки глубины небольших частей изображения, которые могут быть размыты или не размыты.
В результате было разработано двухальтернативное задание с принудительным выбором (2AFC), в котором испытуемые делали суждения о том, какое из двух изображений является фотографией сцены в натуральную величину (с учетом различных обработок размытия, включая полное размытие) или модели в масштабе 1 к 76.
Подготовка к опытам
В качестве визуальных стимулов были использованы фото в оттенках серого (8 бит глубины), которые были обрезаны до 418 пикселей в ширину и 298 пикселей в высоту. Сцена на снимках была достаточно проста — железная дорога с тепловозом. Шесть из них были реальными, а другие шесть — фотографиями миниатюр (масштаб 1:76).
Фотографии настоящего поезда были взяты из интернета, при этом были определенные критерии отбора:
- четкая плоскость земли с оптическим наклоном, который уменьшался по мере удаления от фотографа и был (довольно) плоским слева направо;
- минимум деталей, которые было бы трудно воспроизвести в виде модели (тем самым идентифицируя изображение как полномасштабное, например, дым или пар, а также крупные планы людей);
- высокое качество изображения.
Фотографии миниатюр были сделаны с помощью цифровой зеркальной фотокамеры при сильном комнатном освещении и длительной выдержке (несколько секунд), позволяющей использовать наименьшую апертуру, возможную с имеющимся оборудованием. Это помогло уменьшить размытие расфокусировки, что было бы важным признаком их истинного масштаба. Изображения моделей были тщательно обрезаны, чтобы на них не было признаков полноразмерной обстановки, в которой они были сфотографированы.
Все фото затем обработали с помощью Matlab, чтобы преобразовать их в ахроматические 8-битные изображения и отрегулировать их уровни серого так, чтобы каждое изображение имело средний уровень серого 127. Затем были применены различные методы размытия.
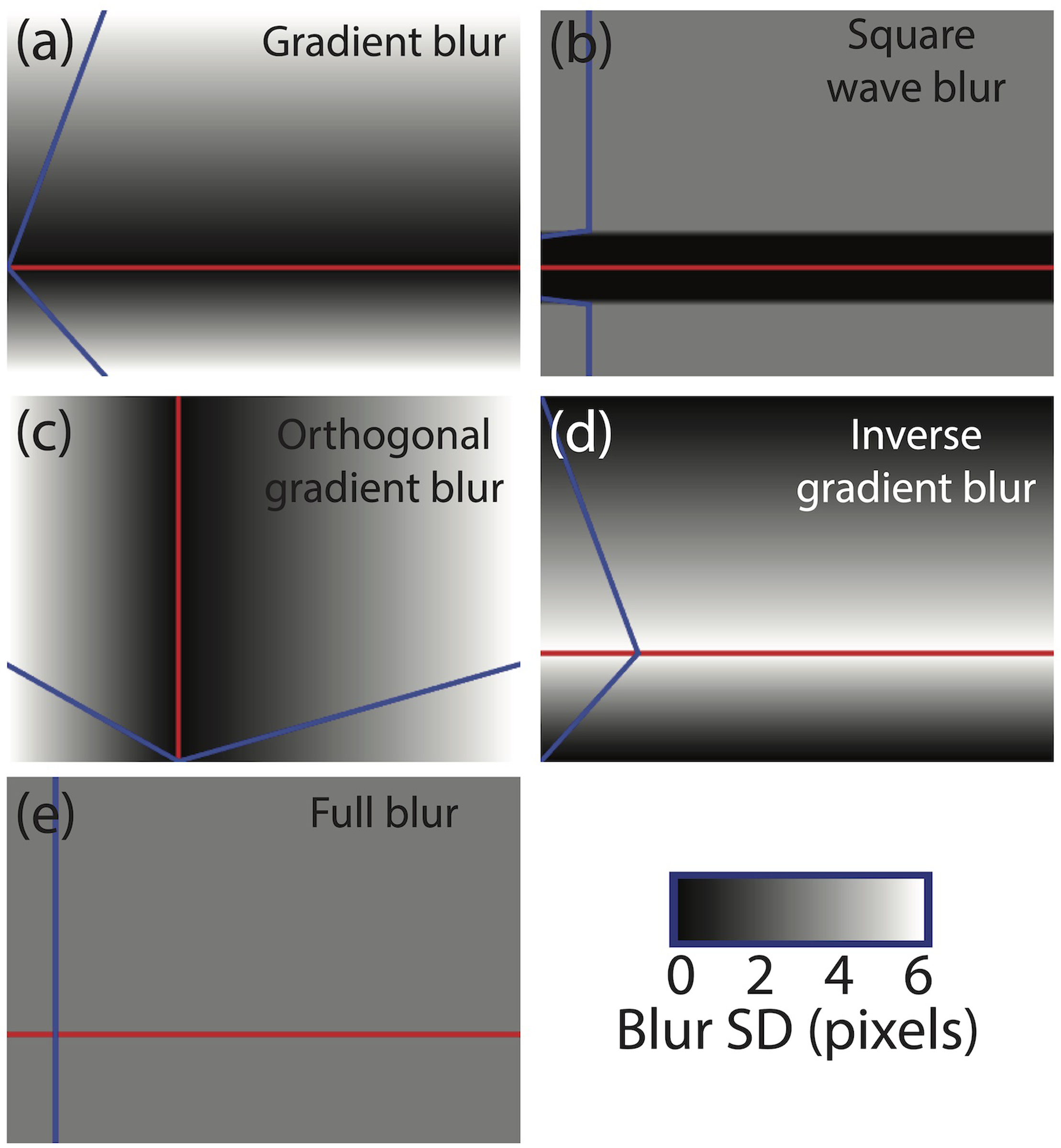
Изображение №1: типы примененного в опытах размытия.
Каждое из шести фото реального поезда подвергалось каждой из шести обработок размытия. При обработке «без размытия» дальнейшая обработка изображения не выполнялась. В других обработках вручную выбирался контур фокуса, проходящий через переднюю часть кабины локомотива, и строилось круговое ядро размытия по Гауссу, максимальное размытие которого имело стандартное отклонение 6 пикселей.
При обработке «градиентное размытие» размытие линейно уменьшалось от максимального значения в нижней части фотографии до нуля на контуре фокуса, а затем линейно возвращалось к максимальному значению в верхней части фотографии (1A).
В условиях «прямоугольного размытия» горизонтальная полоса изображения (шириной 50 пикселей) располагалась по центру контура фокуса и оставалась необработанной. Выше и ниже этого были узкие рампы (шириной 5 пикселей), в которых градиент размытия увеличивался от нуля до половины своего максимума. Остальная часть изображения была обработана с полумаксимальным размытием (1B). Цель узких рамп заключалась в том, чтобы удалить резкую границу от размытия до отсутствия размытия, что заставляло изображения выглядеть так, как будто они просматриваются через «матовое стекло» с зазором посередине.
Обработка «ортогональное градиентное размытие» была такой же, как и обработка градиентного размытия, за исключением того, что она применялась горизонтально, а не вертикально (1C).
При обработке «обратное градиентное размытие» градиент размытия применялся в противоположном направлении от обработки «градиентным размытием» (1D), а при «равномерном размытии» все изображение подвергалось фиксированному уровню размытия, составлявшему половину его максимум (т. е. стандартное отклонение в 3 пикселя).

Изображение №2: результаты всех типов обработки размытием снимков реального поезда.

Изображение №3: снимки миниатюр.

Изображение №4: снимки реального поезда, обработанные «градиентным размытием».
Применение обработки размытия, описанной выше, дало 36 различных полномасштабных изображений. Каждое из них было соединено с каждым из шести изображений миниатюры, в результате чего было получено 216 различных пар изображений.
Каждому из участников опыта предоставлялась пара изображений — снимок реального поезда, обработанный одним из методов размытия, и снимок миниатюры без размытия. Задача участников заключалась в определении, на каком из снимков изображен реальный поезд. Всего в опытах приняли участие 108 человек (41 мужчина, 67 женщин, средний возраст = 20.7 лет), в результате чего каждую пару снимков видело по 3 человека.
Результаты опытов
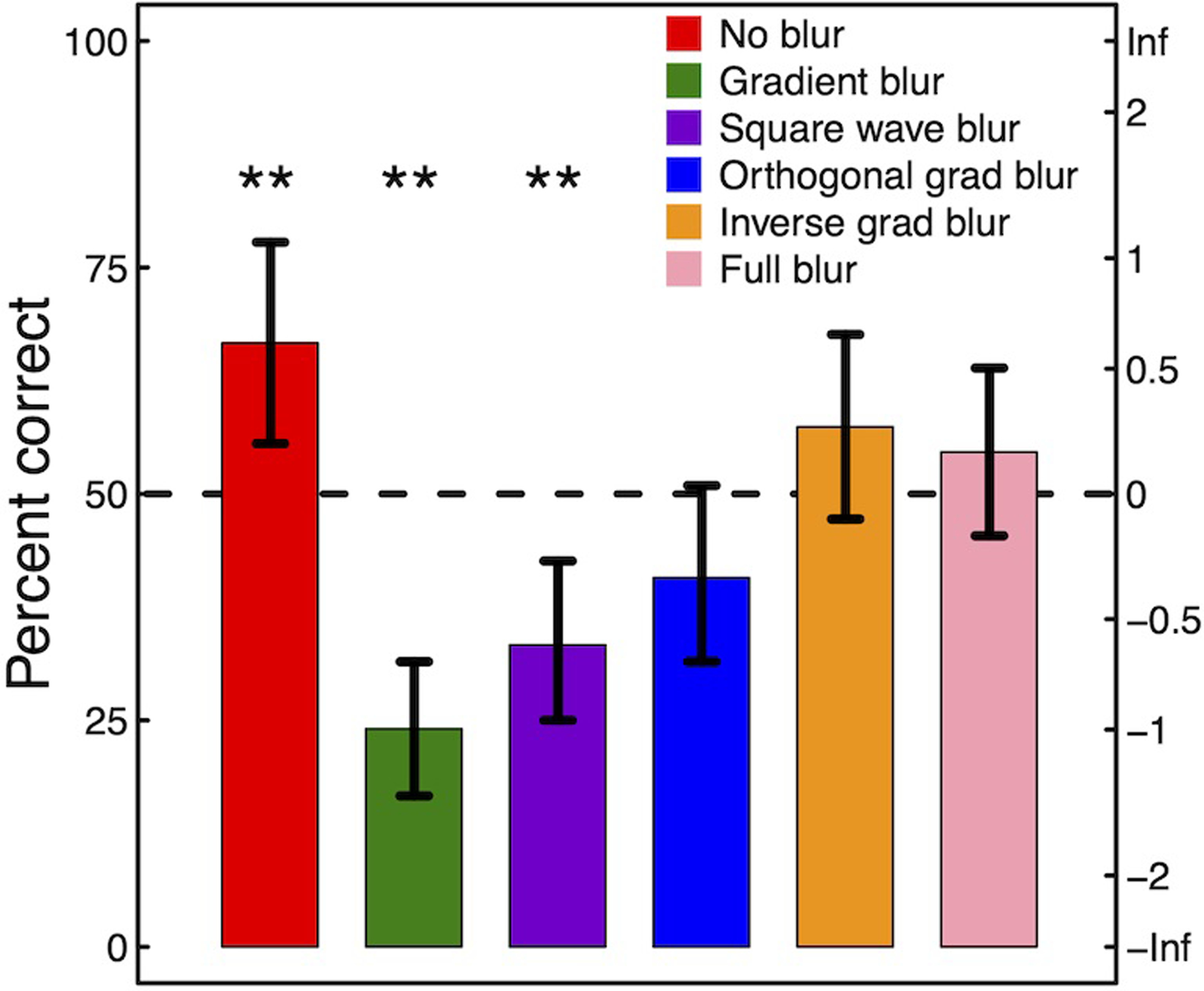
Изображение №5
Результаты опытов показаны на графике выше, которые отображает процент правильных испытаний (левая ордината), объединенных для 108 участников для каждой из шести обработок размытием. Стоит отметить, что для 2AFC 50% правильных ответов это показатель случайности. Следовательно, ученых интересовали значительные отклонения от этого значения, как вверх, так и вниз. Процент правильных ответов также был преобразован в эквивалентные оценки d-prime (правая ордината).
Для статистического анализа процент правильных ответов для каждой пары изображений был получен от трех участников, которые видели эту пару, что дало n = 36 триплетных оценок для каждого условия. Чтобы сравнить все условия, ученые провели ANOVA тест Фридмана, который был очень значимым (Fr(5) = 46.21, p < 0.001). Это указывает на то, что обработки изображений действительно влияли на восприятие масштаба. Также было выполнено пять апостериорных ранговых тестов Уилкоксона для сравнения условия градиентного размытия с каждым из пяти других условий. Были проведены еще шесть знаковых ранговых тестов Уилкоксона, чтобы сравнить случайно выбранные два условия. При отсутствии размытия (красная столбец) фото реального поезда определялись правильно с частотой, значительно выше случайности. Это указывает на то, что участники могли достоверно определить масштаб сцены на фото, когда они не подвергались обработке (Z = 2.42, p = 0.046). Однако, когда фото были обработаны вертикальным градиентом размытия (зеленый столбец), правильность определения упала значительно ниже, чем для необработанных изображений (Z = -4.71, p < 0ю001) и значительно ниже случайного ответа (Z = — 4.36, p < 0.001). Это означает, что участники систематически приходили к выводу, что фото миниатюр куда больше похожи на фото реального поезда, чем фото реального поезда. Когда градиент размытия был заменен обработкой прямоугольной волны (фиолетовый столбец), результаты существенно не отличались друг от друга (Z = -1.80, p = 0.368), хотя они оставались значительно ниже случайного ответа (Z = -2.89, p = 0.01). Когда градиент размытия был повернут на 90 градусов (синий столбец), результаты были незначительно ниже случайного ответа (Z = 1.61, p = 0.320), а эффект был значительно меньше, чем для исходного условия градиентного размытия (Z = -2.76, p = 0.029). Опрос испытуемых после проведения опытов показал, что они сочли задачу куда сложнее, чем изначально думали. Интересно то, что ни один из 108 участников не выполнил все шесть своих испытаний правильно. Вышеописанные результаты полностью согласуются с утверждением, что применение правильно выровненных градиентов размытия приводит к отрицательному d-prime для определения реального масштаба. Предположительно, это происходит потому, что когда размытие помещается вверху и внизу изображения, это соответствует (в широком смысле) ближней и дальней частям сцены. Это те части сцены, которые подвержены наибольшему уровню оптического размытия в любой системе обработки изображений. Но для того, чтобы размытие было большим, устройство формирования изображения должно быть достаточно близко к объекту сцены, а для того, чтобы ширина поля была такой же большой, подразумевается, что сцена должна быть миниатюрой. Основной вывод заключается в том, что проведенные манипуляции с изображениями привели к эффекту миниатюризации с наклоном и сдвигом. Однако необходимо также учесть и другие стратегии реагирования, которые могли быть приняты участниками опытов, и сравнить их с результатами. Одна из возможностей заключалась в том, что участники могли относить все размытые фото исключительно в одну из двух категорий (только реальный поезд или только миниатюра). Однако если бы это было так, то результаты для условий ортогонального размытия, обратного размытия и полного размытия должны были быть такими же, как для условия градиентного размытия, но это не так. Другая возможность состоит в том, что решающим фактором было включение линейного градиента размытия. Однако это кажется маловероятным, поскольку результаты для условий ортогонального и обратного размытия отличались от условий градиентного размытия. Результаты условия размытия с прямоугольной волной показывают, что включение расширенных линейных градиентов не является строго необходимым для получения эффектов миниатюризации. Решающим фактором, по-видимому, является соответствующая ориентация контура фокуса. Несмотря на описанные выше методологические различия, это накладывает ограничения на теоретические предложения, касающиеся градиентов размытия, но не обязательно перечеркивает всю теорию. Как отмечают ученые, можно было бы разработать эвристический подход, который хорошо подходил бы для условий грубого размытия, эффективность которых они продемонстрировали. Кроме того, этот грубый уровень анализа, возможно, не удивителен в свете данных из других трудов о том, что эффективность распознавания размытия является «посредственной» и что в сцене можно закодировать только четыре различных уровня размытия. Таким образом, хоть размытие и вносит важный вклад в воспринимаемый масштаб сцены, его роль в человеческом зрении может быть более грубой, чем его математический потенциал. Одной из причин этого может быть то, что использование размытия в условиях пересечения ограничений требует, чтобы зрительная система знала о диаметре зрачка. Однако нет доказательств того, что зрительная система имеет доступ к подобной информации о собственной анатомии. Из вышесказанного следует, что зрительная система человека действительно использует размытие для определения масштаба, однако это очень грубая оценка. Если перевести ее в математический эквивалент, то результаты моделирования будут куда лучше, чем в реальности. Следовательно, размытие является далеко не единственным фактором, который учитывается мозгом человека во время оценки масштаба. Для более детального ознакомления с нюансами исследования рекомендую заглянуть в доклад ученых.
Эпилог
В рассмотренном нами сегодня труде ученые провели интересный опыт, в ходе которого испытуемые должны были определить, на каком фото изображен реальный поезд, а на каком — миниатюра. При этом снимки реального поезда обрабатывались путем добавления определенного типа размытия.
Результаты опытов показали, что большинство испытуемых ошибочно принимали миниатюру за реальный поезд. Это свидетельствует о том, что размытие хоть и используется нашей зрительной системой для оценки масштаба, но является не единственным фактором.
Любопытно то, что если математически моделировать подобный эксперимент, то размытие позволяет определять масштаб с невероятной точностью, что совершенно не соответствует реальности. Из этого следует вывод, что наша зрительная система крайне грубо и неточно использует фактор размытия, а восприятие масштаба как таковое является далеким от идеала.
Подобного рода исследования могут помочь ученым лучше понять вычислительные принципы, которые лежат в основе нашего восприятия окружающего мира.
Немного рекламы
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас, оформив заказ или порекомендовав знакомым, облачные VPS для разработчиков от $4.99, уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5-2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps от $19 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле в дата-центре Maincubes Tier IV в Амстердаме? Только у нас 2 х Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 ТВ от $199 в Нидерландах! Dell R420 — 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB — от $99! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки?

