
Алгоритмы сжатия — это очень коварная тема, привлекающая многих новичков. Это правда! Часто человеку кажется, что его осенила божественная идея, как сильно сжать данные. Любые, кстати! Без потерь! Рекурсивно! А поскольку данные — это хранение информации и передача, то если хотя бы на единицы процентов результат улучшить — это миллиарды долларов (смотрим экономию всех провайдеров на передаче и хранении, всех дата-центров компаний, всех домашних пользователей, перемножаем… аж дух захватывает)! И люди пишут письма:
«Обращаюсь к вам, как «создателю и демиургу проекта 😉 compression». Мной придуман алгоритм, основанный на простом рассуждении – если файл условно несжимаемый, есть вероятность что, часть файла имеет избыточность и файл можно сжать частично. …»
«Обращаюсь к Вам, как к одному из главных специалистов в области сжатия информации. Предлагаю Вам ознакомиться с изобретением в области сжатия информации. […] По мнению автора, основным достоинством данного «Способа кодирования информации» является способность одинаково хорошо сжимать без потери качества информацию любого типа (видео, аудио, текст, архив и т.д.). Помимо этого «Способ» позволяет проводить процесс кодирования (сжатия) повторно….»
Бывает даже так:
«Мне, для начала, нужно 30–60 минут общения с Вами по Скайпу.
Вопрос: каково Ваше вознаграждение и куда его отправить?»
И если вы думаете, что обращения типа последнего — мои любимые, то реакция ровно обратная («Боже, дай мне терпения!»). Ибо по опыту в последнем случае люди наиболее настойчивые… Кстати, это могут быть не только авторы, но и инвесторы, о которых ниже тоже будет.

Кому интересно, в чем же таки коварство алгоритмов, есть ли у нас таланты, и где же, наконец, деньги — добро пожаловать под кат! (Талантливые авторы алгоритмов могут сразу переходить в раздел «Про деньги»).
Disclaimer 1: Любые совпадения в тексте с реальными лицами и фактами являются абсолютно случайными!
Disclaimer 2: Автор съел на этой теме несколько корейских невкусных собак, но так и не стал считать себя в ней истиной в последней инстанции!
Когда-то давно я имел неосторожность организовать команду из 4-х человек, и мы вместе написали книжку по алгоритмам сжатия, где много подходов разобрали. С тех пор идет довольно стабильный поток подобных писем. Настоящая жемчужина была этой весной. Пока люди страдали от ковида, человек написал очень прикольный текст про свой будущий архиватор. Зацените концовку (орфография во всех цитатах авторская):
«И когда компрессор ******- будет создан… Тогда… Тогда…
Да развергнутся Небеса.
И сойдёт на создателя сего творения Благодать, которая наполнит его Чашу богоугодным напитком,
Который опьянит его рассудок. И разольётся тепло по всей периферии, по всем жилам, согревая утомлённое от трудов, его бренное тело
И тогда сожмётся несжимаемый файл.
И тогда все скажут: — О, чудо!… И сильно удивятся, и начнут кричать: — Ура! И начнут кидать вверх запонки, туфли, галстуки, лифчики
А потом выползет на пронизывающий свет брюзглявый скептик
Откроет один зашореный глаз, и пробубнит: — Этого не может быть, так не бывает, у меня в книжке написано.
А скромный создатель ******, снисходительно улыбнётся. Зачем ему доказывать что-то, когда его Чаша наполнена, а Душа преисполнена
удовлетворённостью от выполненного дела…»
Боже, как поэтично! Особенно про несжимаемый файл, подброшенные лифчики и «брюзглявого» скептика, написавшего книжку! Волшебно! Я давно так не смеялся. Причем автор жег и дальше:
«А для военных, — это вообще находка. И сложно представить, сколько фильмов можно будет записать на одну флэшку. ТВ, интернет, телефон — всё по двум проводам в дом. А оптоволокно будут использовать для новогодних гирлянд и магазинных вывесок. Мы живём в удивительное время, когда всё меняется. А России нужен технологический скачок.»
В общем, Россия обречена на процветание. Причем в письме есть интересные рассуждения об алгоритмах, из которых понятно, что этот текст — тонкий стеб с отличным юмором. Но, если бы такой человек был один…
О неправоте старика Шеннона
Писем таких много. Вот, например, человек теорему Шеннона поминает, но, похоже, не разбирался с ее доказательством:
«Просмотрите pls не так бегло 😉 Сравнение с Zip только «для широкого круга читателей». Прямое сравнение с Арифметическим кодированием встречается в неск. местах. И да: я понимаю, что значит «противоречит теореме Шеннона», именно это я и показываю НА ПРАКТИКЕ! Возможный по p*log(p) предел кодирования — **** его превосходит! (в отдельных случаях)
Это не шутка.»
Или вот:
«И все бы хорошо, но **** действительно обеспечивает лучшее сжатие, т.е. поправить надо бы в консерватории Шеннона…»
А эти ребята даже стартап создали:
«Мы создаём алгоритм сжатия данных, очень интересно было бы с вами пообщаться. […] Мы начали разрабатывать алгоритм сжатия данных в конце 2017 года. ************ (второй сооснователь) придумал как сжимать любые данные в несколько раз. С технической точки зрения он лучше меня сможет объяснить, я занимаюсь продвижением.»
Вежливо замечу, что если человек действительно напишет программу, которая ЛЮБЫЕ данные сожмет В НЕСКОЛЬКО РАЗ, то ему не нужен продвиженец, он может прямо сейчас начать хорошо зарабатывать. И я обязательно расскажу как.
Характерно, что многие присланные изобретенные способы «позволяют проводить процесс кодирования (сжатия) повторно», давая возможность в итоге в несколько итераций успешно сжать даже несжимаемые файлы, что специально подчеркивается авторами. Аллилуйя!!!
В принципе тема классная! Помнится, в средневековье, на заре становления химии, многие ученые бились над поиском философского камня, который позволил бы трансмутировать металлы в золото. К сожалению, в повести-сказке для программистов «Понедельник начинается в субботу» эта тема обрывается на самом интересном месте: «Я дошел до стенда «Развитие идеи философского камня», когда в зале вновь появились сержант Ковалев и Модест Матвеевич».
Впрочем, для любого программиста совершенно очевидно, что в наш информационный век современный философский камень — это сжатие несжимаемых данных. И неважно, что для чего-то там что-то доказано.
— Г-голубчики, — сказал Федор Симеонович озадаченно, разобравшись в почерках. — Это же п-проблема Бен Б-бецалеля. К-калиостро же доказал, что она н-не имеет р-решения.
— Мы сами знаем, что она не имеет решения, — сказал Хунта, немедленно ощетиниваясь. — Мы хотим знать, как ее решать.
— К-как-то ты странно рассуждаешь, К-кристо… К-как же искать решение, к-когда его нет? Б-бессмыслица какая-то…
— Извини, Теодор, но это ты очень странно рассуждаешь. Бессмыслица — искать решение, если оно и так есть. Речь идет о том, как поступать с задачей, которая решения не имеет. Это глубоко принципиальный вопрос, который, как я вижу, тебе, прикладнику, к сожалению, не доступен. По-моему, я напрасно начал с тобой беседовать на эту тему.
Все-таки Стругацкие гениальны. Особенно остро это ощущаешь, когда регулярно приходится выступать в роли недалекого тупого прикладника, общение с которым, между прочим, до глубины души оскорбляет настоящий яркий и одаренный талант. Прям беда! Напомню, у Стругацких разговор закончился дуэлью.
Явление, которое проиллюстрировано выше цитатами из писем, — это обычный эффект Даннинга-Крюгера, описанный в статье 1999 года, но хорошо известный со времен античности. Когда человек только начинает изучать любую область, ему кажется, что она очень проста и понятна, уверенность в своих знаниях растет очень быстро. Однако, чем выше самоуверенность в начале, тем глубже яма страданий потом из-за того, что реальность кардинально расходится с представлениями о ней. Причем попытки уберечь людей от глубоких страданий являются крайне неблагодарным занятием. Проверял несколько раз (мать-мать-мать, ладно, страдайте!!!).
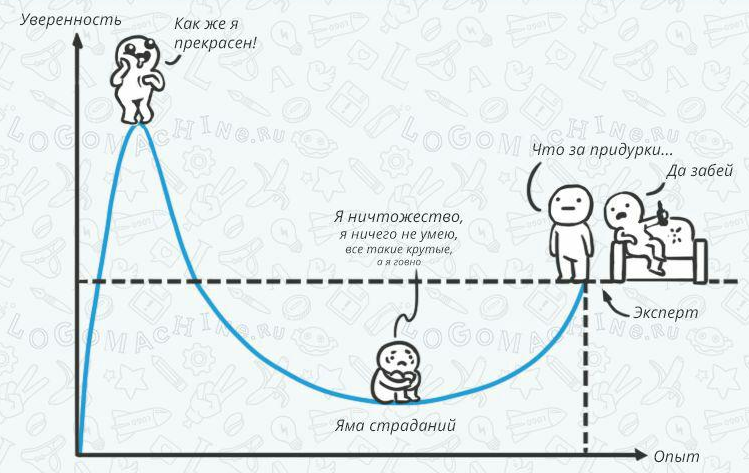
Что можно сказать об опыте авторов таких писем? Когда смотришь присланный людьми PDF на тему «сжатия несжимаемого», Яндекс дает просто неприличную рекламу (реальный скриншот аттача письма):

Справедливости ради люди часто прямо пишут:
«Программирую на Delphi. Язык C, я плохо понимать.»
Или так:
«Так как мои познания в программировании ограничены, ищу соавтора — программиста разбирающегося в алгоритмах сжатия информации»
Или вот очень культурно:
«Дмитрий, если у вас есть возможность помочь в данном вопросе, или заинтересуется кто-то из ваших знакомых – прошу со мной связаться. Если окажется, что алгоритм неработоспособен, готов компенсировать затраты и потраченное время»
Плохая новость заключается в том, что нужно будет разобраться не только как формально записывать алгоритм, но и для каких условий сформулирована та самая пресловутая теорема Шеннона, которую столь дружно «превосходят» начинающие авторы кодеров. «Теория, мой друг, суха, но зеленеет жизни древо» (Гете). И пока практика подтверждала теорию…

Впрочем… Ладно, расскажу! На самом деле сжимать уже сжатые данные, конечно, можно. («Что-о-о-о… он несет???» — возмущенно раздалось с мест!) Спокойно, господа! Рассказываю, как это делается на практике.
Когда-то я руководил разработкой проекта компании SoundGenetics с внутренним названием MP3Zip, позднее названным Sound Slimmer (сайт проекта, увы, более не поддерживается). Тогда удалось достичь сжатия MP3 в среднем в 1.2 раза на большой выборке MP3. Причем сжимался файл полностью без потерь, бит в бит. Идея была в том, что файл распаковывался до потока коэффициентов MDCT, которые далее паковались более эффективно (кому интересны детали, там было несколько патентов).
Причем если кто-то думает, что сильно сжать — основная проблема, то он серьезно ошибается. Как показало вскрытие, огромный процент MP3 файлов, которые тогда ходили по людям, были битые. Особенно конец файла (наследие ранних p2p). И учесть корректно побитые файлы было не так просто. Т.е., если бы можно было «починить» файл, было бы достигнуто большее сжатие, но тогда каждый чайник проверил бы, увидел, что не бит в бит, и что есть силы закричал бы: «Они обма-а-а-анывают!» И был бы прав. Поэтому мы всячески извращались, стараясь минимально потерять сжатие, и максимально парсили битые куски (алгоритмически там не так все просто).
Также интересно, что если бы можно было зафиксировать распакованный файл (условно WAV), а не MP3, то для того же распакованного файла (бит в бит в WAV) можно было бы еще чуть увеличить сжатие. Но, увы, бизнес сказал: работаем только на уровне MP3. Так что эта часть осталась во внутренних разработках. Также по заказу известной японской компании была сильно переделана архитектура алгоритма («а теперь, ребята, делаем те же трюки, только стоя на канате!») и появилась возможность сжимать MP3 поток, т.е. работать по буферу, видя только небольшую часть файла. Это позволяло сжимать вещание. Аналогично, удалось примерно на 11% сжать AAC со всеми наворотами типа обработки битых и было показано, как аналогично дожимать JPEG и GIF (т.е. всю графику тогдашнего веба). В проекте работало 6 человек, и это было очень прикольно!
Так что сжимать сжатое можно! За это даже платят. Лично проверял!
Про деньги
А теперь про самое интересное («Да-да! Было явно обещано про деньги», — раздалось с мест). Умные люди заранее спрашивают в письмах:
«Существующие технологии сжатия графики будут развиваться. В частности, появятся новые преобразования […] Вопрос: как с минимальными усилиями извлечь некоторую финансовую выгоду в случае разработки более перспективных преобразований (которые на 20-30% лучше по быстродействию или по качеству сжатия)?»
Мне нравятся такие письма. Перед тем как попусту растрачивать свой талант копать тему, человек грамотно интересуется, как с минимальными усилиями извлечь максимальную выгоду, когда (фигня вопрос!) удастся всех на 20–30% обогнать.
Постараюсь ответить детально и по пунктам. Поехали!
Способ 0: Популярные неработающие подходы
Начну с нулевого во всех смыслах способа.
В письмах довольно регулярно всплывает тема заработка на патентах. Уж не буду цитатами сыпать, но предложения «вместе сделать и запатентовать» идут регулярно. Сожалею, но вынужден разочаровать, поскольку успешных кейсов, чтобы человек подал патент на алгоритм сжатия и разбогател, я не встречал. Можно реально заработать патентной экспертизой, это да, это реально. А вот продажей патента… Обычно люди сильно недооценивают себестоимость жизненного цикла патента. А вопрос «Почему ваш патент будет работать?» вызывает реальный ступор. («А оно разве не само работает?» — Нет…) Поинтересуйтесь хотя бы, в каких юрисдикциях и как обеспечивают работу патента патентные тролли. Впрочем, это совершенно другая история.
Также частое желание — сделать стартап и, конечно, продать его Google. Джим Коунси, директор подразделения Autodesk Developers Network (на потоке покупавший стартапы), несколько лет вел блог Dances with Elephants: How small companies can partner with large companies to accelerate their business growth. Его метафора танца со слонами довольно точно передает суть процесса. Безусловно, в блоге отражена точка зрения слона, поэтому скольких во время этих танцев раздавили даже не со зла, а просто не заметив, история умалчивает. Но, если вы мечтаете о продаже крупняку за много миллионов — почитайте и трезво содрогнитесь.
Способ 1: Сжимаем несжимаемое за славу и деньги (на новом месте работы)
Проще всего тем, кто реально может «сжимать несжимаемое». Марк Нельсон, автор толстенного кирпича The Data Compression Book — библии сжатия 90-х, еще в 2002 году объявил конкурс, позднее названный The Million Random Digit Challenge и продлевавшийся с уточнением правил не один раз. Смысл конкурса в том, что была взята хорошо подготовленная последовательность случайных чисел (большой файл):

Задача была создать архиватор для этого файла, который вместе с архивом был бы меньше по размеру, чем сжимаемый файл. Ибо, если ограничение на размер архиватора не ставить, задача, как вы понимаете, решается тривиально («Джентльмены верят на слово [что мы часть архива в архиватор не кладем]… Тут-то мне карта и поперла!»). Т.е. надо на другом чистом компе из двух файлов искомый несжимаемый распаковать, ибо история знала случаи, когда «сжимающий ЛЮБОЙ файл» архиватор просто клал часть файла в tmp директорию компа. И люди проверяли, и у них, вы не поверите, работало! Несжимаемые файлы успешно сжимались!!! На самом деле!!! И они коллегам срочно пересылали попробовать, и у них тоже о чудо! работало!!! Офигеть просто… Если архиватор не находил в tmp нужный кусок архива, он просто вызывал деление на ноль и технично падал. А что вы хотели, его технология тогда была несовершенна и сохранять часть архива в облако еще не умела… Но поклонение у пипла уже вызывала! Так сильна человеческая вера в чудо…
В общем, уже много лет Марк Нельсон покупает торт и задувает все больше и больше свечей на день рождения The Million Random Digit Challenge (ведь его детищу уже стукнуло 18!), но воз и ныне там. Интересно, что к созданию исходного файла конкурса приложил руку тот самый физик Джон фон Нейман, который недвусмысленно высказывался, что:
«Любой, кто рассматривает арифметические методы получения случайных чисел, безусловно грешник»
Это, впрочем, не мешает и по сей день особо упорным товарищам со словами «ваши теоремы не работают» «случайностей не бывает» продолжать искать алгоритмические закономерности в несжимаемых данных. В 2012 на десятилетие конкурса Марк Нельсон расширил правила, позволив делать компрессор и декомпрессор любого размера, но работать оно должно для любого файла. И он герой, конечно. Ибо «особо умных» товарищей много, и там уже было сохранение данных в имени файла, переменных среды, буферах ядра и т.д. Т.е. обнаружить читера не так просто, как кажется. Несмотря на малый размер призового фонда конкурса — всего 100 $, — желающих поучаствовать достаточно, и, если вы победите, всемирная известность и выгодные контракты вам точно обеспечены!
Способ 2: Получаем под сжатие деньги инвестора
Вообще стартапы по теме сжатия возникают регулярно. Даже в сериале «Кремниевая долина» у главного героя, если помните, был стартап по сжатию (в т.ч. 3D видео, что характерно). Поверьте, это не случайность, а тонкий троллинг. Деньги под сжатие просят (и даже получают!) довольно часто.
Но русские стартапы и инвесторы — это прям очень своеобразная тема. Нет, классные компании бывают, особенно бутстрэппинг или спин-офф, но в обычных венчурах по сжатию обычно такая жесть под капотом… Причем причина, на мой скромный взгляд, в непрофессионализме инвесторов. Я не знаю, на каком лесе, газе, нефти, металле они заработали свои сотни миллионов миллиардов, но деньги им явно жгут карман.

Причем у меня с такими товарищами была масса характерных разговоров. Выходят на меня, как правило, через МГУ, и у них представление такое, что ученый должен млеть от самого факта общения с новым русским инвестором… А я сам был и СЕО, и СТО и живу, хм… не на зарплату. И очень любопытно посмотреть, как эти горе-инвесторы себя ведут. А ведут они себя своеобразно. Что-то веско пообещать и пропасть — норма. И при этом забавное желание получить консультацию на халяву. Причем желательно разобраться вот прямо «за один сеанс».
Господа! За получасовой сеанс вам все про ваш pet project расскажут экстрасенсы (с гарантией 100%, кстати). А если вам заливают в уши грамотно, то реально вникать надо. В общем, смотришь на этот мастер-класс по переговорам и так и хочется сказать: «Господи! Жги!» «Люди! Берите инвестиции!». Ибо на чужом опыте эти инвесторы не учатся.
Справедливости ради — я прекрасно понимаю, что мне приходится общаться с «попавшими» инвесторами, и это, конечно, вариации на тему «ошибки выжившего». Опять же я хорошо знаю, насколько изменился в лучшую сторону российский венчур за последние 20 лет. Но тем не менее…
Короче, господа! Непуганых людей с деньгами в наших, да и чужих палестинах все еще явно хватает. Поэтому ищите и обрящете, стучите и откроется. Как минимум, сможете проверить свою идею. Чужим опытом получения инвестиций в русских реалиях, впрочем, тоже интересоваться рекомендую. Так, знаете, на всякий случай!
Способ 3: Конкурс на сжатие википедии
В 2006 профессор австралийского университета (ныне — исследователь в Google DeepMind) и автор нескольких книжек (в том числе книги 2005 года по раннему ИИ и алгоритмической вероятности) Маркус Хаттер объявил приз в 50000 € за лучшее сжатие 1 Gb текстов википедии. На самом деле это реклама, поскольку формула приза построена так, что более чем 10000 € Маркус не рисковал. Но тем не менее за 11 лет конкурса 8747 € призовых были выплачены! Вот, к примеру, призы за 2007 и 2018 коллеге и соавтору нашей книжки Александру Ратушняку (и это не все, о чем будет ниже):


Интересно, что в 2020 году конкурс получил новое название 500’000€ Prize for Compressing Human Knowledge, а размер корпуса на сжатие увеличен до 10 Gb.
В общем, если вы реально классно сжимаете — дерзайте! Сжатие википедии — дело благородное. Причем, если вы выиграете, очень многие компании будут рады видеть вас у себя и вы будете мучительно выбирать, где и как хотели бы жить и работать.
Способ 4: Специализированные конкурсы
Также существуют специализированные конкурсы. Например, в 2011 году был конкурс Sequence Squeeze Compression Competition на сжатие последовательности ДНК с призовым фондом 15000 $. Причем в результатах видно, что по сравнению с baseline удалось либо практически на порядок увеличить скорость сжатия при существенном уменьшении файла, либо при той же скорости практически в 3 раза увеличить сжатие. Это является основной мотивацией компаний для проведения таких конкурсов (например, в 3 раза уменьшить затраты на хранение данных):
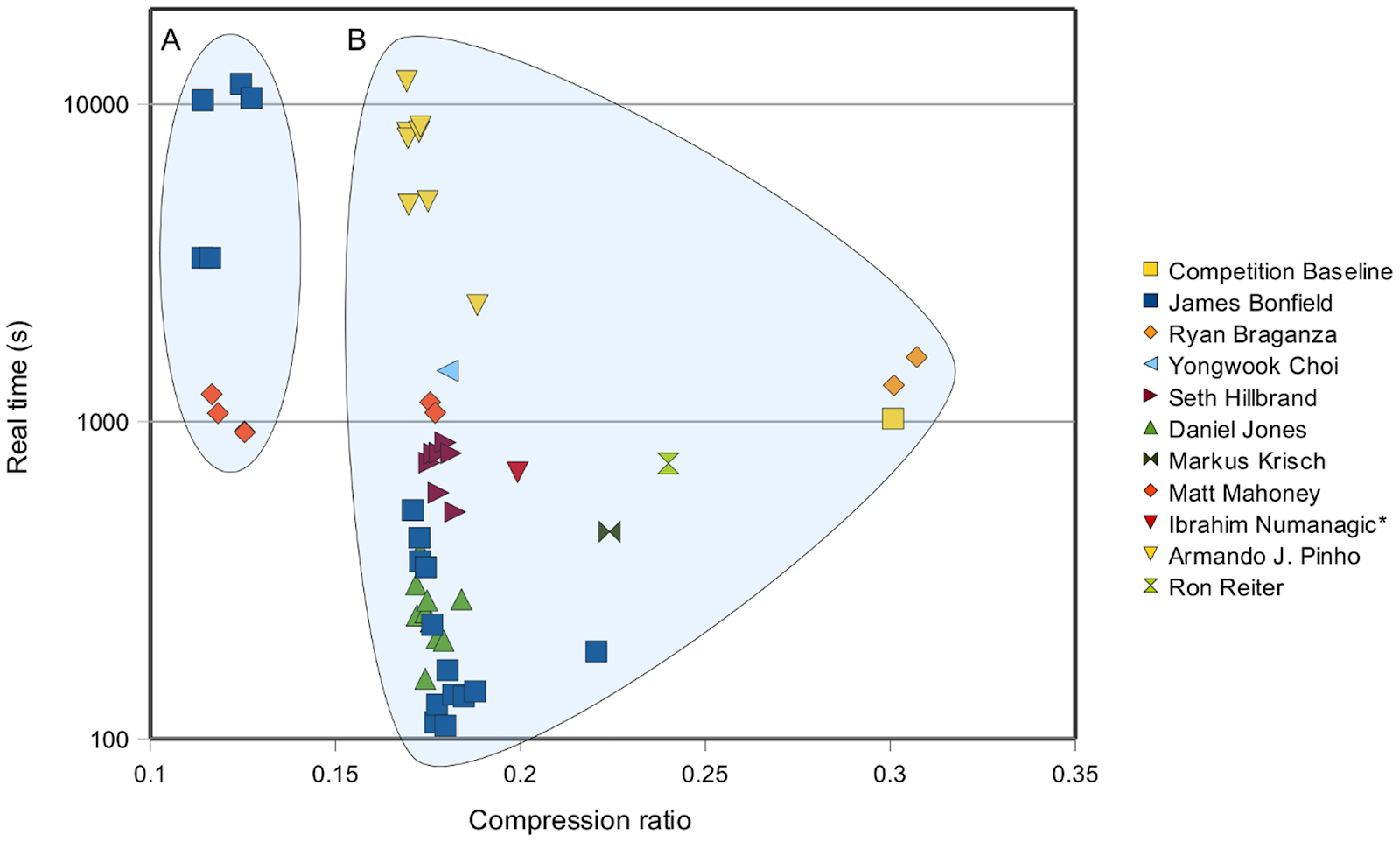
В этом конкурсе победители публиковались в открытых исходных текстах, что улучшает карму призеров отсекает часть авторов.
Способ 5: Конкурс на 50000 евро + слава в подарок

И, наконец, прямо сейчас идет конкурс Global Data Compression Competition с прямым призовым фондом 50000 € (т.е. вся сумма планируется к выплате после оглашения результатов). Как я понимаю, это самый крупный в истории конкурс по сжатию без потерь, если считать размер выплаты ко времени конкурса. В его организации принимают участие трое из четырех авторов той самой книжки.
В конкурсе 4 вида данных:
- Тексты (дань традиции). Размер 1 Gb. Практический смысл сжатия текстов сегодня ограничен, но с новыми ML/DL NLP подходами там есть с чем развернуться и силушку показать.
- Картинки. Размер 1 Gb. Тут понятно.
- Количественно-качественные данные: исполняемые файлы с большим процентом числовых таблиц. Размер 1 Gb. Это, условно, кейс дистрибутивов, бэкапов и разнообразные случаи сжатия разнородных данных.
- Блочное сжатие — 1 Gb блоков по 32 Kb — это кейс баз данных, block storage, сжатия файловых систем. Данные в этом кейсе неоднородные, чтобы также приблизиться к реальным условиям.
Для каждого вида данных есть 3 варианта ограничений по скорости для быстрых, средних и медленных («Иду на рекорд!») алгоритмов. Впрочем, многие алгоритмы можно адаптировать без переделки, и вы наверняка обращали внимание, что в тех же RAR или ZIP можно задавать силу сжатия, и чем сильнее, тем дольше жмет. Вот ровно про это речь.
Итого получается 12 номинаций, в каждой из которых призы за лучшие места. Можно и нужно точиться по времени и занимать первые места в нескольких номинациях (если у вас адски мощный DL препроцессинг текстовых данных, например).
Соревнование международное, и в нем уже участвуют авторы алгоритмов сжатия от профессоров университетов США до индийских программистов.
Важный момент — никто не требует исходников. Это, безусловно, расширяет список участников, но… Правильно, тут же появляются «самые умные». Например, один из участников из… гм… Юго-Восточной Азии явственно парсит GitHub на предмет годных исходников, точит их под задание и засылает. Просто и со вкусом. При том, что вычислить такое поведение, пусть сложно, но реально.
Чтобы сразу понятно было. Финансирует конкурс Huawei. В этот момент должен раздаться хор непонятно чем недовольных. Поскольку когда такого спонсора нет, то призовой фонд, вспоминаем старика Нельсона, равен 100 $. Причем в его случае он мог и миллион долларов пообещать, но представляете, с какими изощренными способами спрятать куда-то кусок архива ему бы пришлось столкнуться! Он же не мазохист. И вообще у нас на compression.ru и ранее рейтинги кодеров проводились. И в других местах тоже. Но это, похоже, первое широкомасштабное соревнование на тему сжатия без потерь, проспонсированное компанией! Т.е. ни Google, ни Apple, ни Intel, ни Microsoft как-то не сподобились. При том что они от этого вполне выигрывают, в том числе реальные большие деньги на экономии трафика и хранении. А, чем выше призовой фонд, тем больше геморрой для нас, авторов книг организаторов соревнований. Ибо больше не только волн, но и пены. Хотя и больше шанс реально интересные результаты собрать, конечно.
Сейчас большие надежды возлагаются на Deep Learning, который, конечно, сметет все старые алгоритмы и в сжатии без потерь тоже. И тогда покажется смешным сжатие бит в бит MP3 и JPEG на 20%, и снизойдет на автора алгоритма благодать, и он улыбнется.
Короче, господа! Результаты, надеемся, будут очень интересные. И, если вы где-то будете в лидерах — вас точно заметят и закидают предложениями о работе. Так что дерзайте! Планируем обязательно рассказать о том, что получилось в итоге.
Резюмируя тему, замечу, что наиболее частый путь успеха в общем-то похож на путь современного ML/DL поколения: прокачка → Kaggle/хакатоны/конкурсы → победы → зарплата $100–200K в год. Маркус Хаттер в DeepMind, как видим, получает столько, что конкурсы на полмиллиона евро лично спонсирует. В этом большой плюс соревнований и побед. Главное — адекватно оценивать усилия, необходимые на качественную прокачку и быстро переходить от слов к делу (это самое сложное по опыту).
Про талант
И, наконец, последняя обещанная тема. Может показаться, что я как-то неровно дышу к нашим ярким талантам. Это не так. Просто мне ближе такое определение:

И к счастью, я знаю много замечательных талантливых (в рамках этого определения) соотечественников. Например, мы 17 лет проводим сравнения кодеков, в которых участвуют компании из разных стран. Так, до недавнего времени едва ли не половина общения шла на русском. Т.е. компания была западная, а видеокодеками в ней занимались люди родом из России, Украины, Белоруссии, из Прибалтики, наконец. Недавно, правда, стало очень много китайцев (как компаний, так и разработчиков), но это отдельная тема.
С обычным сжатием ситуация также очень показательна:
- Если кто не знает, то автор RAR (WinRAR) — фактически самого популярного коммерческого архиватора в мире — талантливый челябинец Евгений Рошал.
- Автор 7-zip — крайне популярной бесплатной open-source программы сжатия и LZMA SDK — Игорь Павлов.
- Автор алгоритма PPMd (использованного и в RAR, и в 7-zip) и почти призер Hutter Prize — Дмитрий Шкарин. Кстати, его же метод BMF сейчас в топе Global Data Compression Competition на сжатии изображений. При том что он придуман 15–20 лет назад!
- Автор PPMY, PPMd_sh, shar2 и многих алгоритмов рекомпрессии JPEG, MP3, AAC, Deflate (участник упоминавшегося проекта SoundSlimmer) — харьковчанин Евгений Шелвин. Евгений — контрибьютор большого количества компрессоров с открытым кодом и поддерживает, пожалуй, самый известный в мире форум по сжатию.
- Александр Ратушняк, один из авторов той самой книги и соорганизатор конкурса Global Data Compression Competition, автор высокоэффективных компрессоров изображений, контрибьютор стандарта JPEG-XL, четыре раза получал Hutter Prize! Вообще таблица призеров Hutter Prize выглядит так, будто, несмотря на длительность конкурса, Саша не оставил другим авторам никаких шансов:
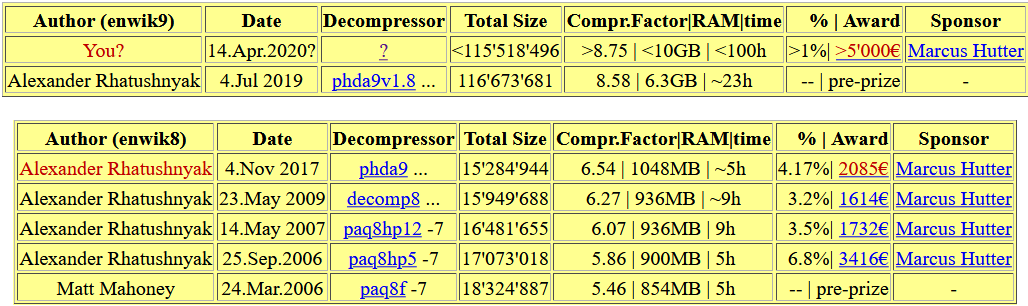
И список выше далеко не полный. Причем когда общаешься с этими замечательными людьми, понимаешь, что талант — не главное. А главное — терпеливо и настойчиво заниматься темой, которая тебе действительно нравится.
Закончить хотелось бы словами любимых Стругацких:
Сюда пришли люди, которым было приятнее быть друг с другом, чем порознь, которые терпеть не могли всякого рода воскресений, потому что в воскресенье им было скучно. Маги, Люди с большой буквы, и девизом их было — «Понедельник начинается в субботу»… они приняли рабочую гипотезу, что счастье в непрерывном познании неизвестного и смысл жизни в том же. Каждый человек — маг в душе, но он становится магом только тогда, когда начинает меньше думать о себе и больше о других, когда работать ему становится интереснее, чем развлекаться в старинном смысле этого слова.
Дерзайте! Доводите ваши идеи до результата! И пусть ваша работа будет интереснее ваших развлечений!
Читайте также: Уличная магия сравнения кодеков. Раскрываем секреты — текст о том, как мы много лет кодеки сравнивали и с какими эпичными случаями сталкивались.
Благодарности
Хотелось бы сердечно поблагодарить:
- Лабораторию Компьютерной Графики и Мультимедиа ВМК МГУ им. М.В. Ломоносова за вклад в развитие сжатия медиа в России и не только,
- моих соавторов по книге «Методы сжатия данных», благодаря которым этот проект вообще стал возможным и нанес непоправимую пользу многим людям,
- персонально Константина Кожемякова и Кирилла Малышева, которые сделали очень много для того, чтобы эта статья стала лучше,
- и, наконец, огромное спасибо Дмитрию Коновальчуку, Максиму Смирнову, Анастасии Кирилловой, Андрею Москаленко, Егору Склярову, Никите Молотилову, Ивану Молодецких, Вячеславу Мещанинову, Михаилу Дремину, Александру Гущину и Николаю Сафонову за большое количество дельных замечаний и правок, сделавших этот текст намного лучше!


