
Четыре примера работы программы, код которой опубликован в открытом доступе. Слева показаны исходные изображения, справа — результат автоматической обработки
Многие задачи в обработке изображений, компьютерной графике и компьютерном зрении можно свести к задаче «трансляции» одного изображения (на входе) в другое (на выходе). Так же как один и тот же текст можно представить на английском или русском языке, так и изображение можно представить в RGB-цветах, в градиентах, в виде карты границ объектов, карты семантических меток и т.д. По образцу систем автоматического перевода текстов, разработчики из лаборатории Berkeley AI Research (BAIR) Калифорнийского университета в Беркли создали приложение для автоматической трансляции изображений из одного представления в другое. Например, из чёрно-белого наброска в полноцветную картинку.
Неосведомлённому человеку работа такой программы покажется магией, но в основе её лежит программная модель условных генеративных состязательных сетей (conditional generative adversarial networks, cGAN) — разновидности известного типа генеративных состязательных сетей (generative adversarial networks, GAN).
Авторы научной работы пишут, что большинство проблем, которые возникают при трансляции изображений, связаны с трансляцией или «многие к одному» (компьютерное зрение — трансляция фотографий в семантические карты, сегменты, границы объектов и т.д.), или «один ко многим» (компьютерная графика — трансляция меток или входных данных от пользователя в реалистичных изображения). Традиционно каждая из этих задач выполняется отдельным специализированным приложением. В своей работе авторы попытались создать единый универсальный фреймворк для всех таких проблем. И у них получилось.
Для трансляции изображений великолепно подходят свёрточные нейросети, обученные минимизировать функцию потерь, то есть меру расхождения между истинным значением оцениваемого параметра и оценкой параметра. Хотя само обучение происходит автоматически, всё-таки для эффективной минимизации функции потерь требуется значительная ручная работа. Другими словами, нам по-прежнему нужно объяснить и показать нейросети, что конкретно нужно минимизировать. И здесь кроется много подводных камней, которые отрицательно сказываются на результате, если мы работаем с функцией потерь на низком уровне типа «минимизировать евклидово расстояние между предсказанными и настоящими пикселями» — это приведёт к генерации смазанных изображений.

Влияние различных функций потери на результат
Намного проще было бы ставить нейросети высокоуровневые задачи типа «сгенерировать изображение, неотличимое от реальности», а затем автоматически обучить нейросеть для минимизации функции потерь, которая наилучшим образом выполняет поставленную задачу. Именно так работают генеративные состязательные сети (GAN) — одно из самых перспективных направлений в разработке нейросетей на сегодняшний день. Сеть GAN обучает функцию потерь, задачей которой является классифицировать изображение как «настоящее» или «поддельное», одновременно тренируя генеративную модель, чтобы минимизировать эту функцию. Здесь никак не могут получиться размытые изображения на выходе, потому что они не пройдут проверку классификации как «настоящие».
Разработчики использовали для поставленной задачи условные генеративные состязательные сети (cGAN), то есть GAN с условным параметром. Так же как GAN усваивает генеративную модель данных, cGAN усваивает генеративную модель по определённому условию, что делает её пригодной для трансляции изображений «один в один».

Трансляция разметки Cityscapes в реалистичные фотографии. Слева разметка, в центре оригинал, а справа сгенерированное изображение
В последние два года описано множество применений GAN и хорошо изучена теоретическая основа их работы. Но во всех этих работах GAN используется только для специализированных задач (например, генерация пугающих изображений или генерация порнокартинок). Не совсем понятно было, каким образом использовать GAN подходит для эффективной трансляции изображений «один в один». Основная цель данной работы — продемонстрировать, что такая нейросеть способна выполнять большой перечень разнообразных задач, показывая вполне приемлемый результат.
Например, очень неплохо смотрится раскраска чёрно-белых карандашных набросков (левая колонка), на основе которых нейросеть генерирует фотореалистичные изображения (правая колонка). В некоторых случаях результат работы нейросети кажется даже реалистичнее, чем настоящая фотография (центральная колонка, для сравнения).

Трансляция карандашных набросков в реалистичные фотографии. Слева карандашный рисунок, в центре оригинал, а справа сгенерированное изображение


Трансляция карандашных набросков в реалистичные фотографии
Как и в других генеративных сетях, в этой GAN нейросети воюют между собой. Одна из них (генератор) пытается создать фальшивое изображение, чтобы обмануть другую (дискриминатор). Со временем генератор обучается всё лучше обманывать дискриминатор, то есть генерирвоать более реалистичные изображения. В отличие от обычных GAN, в Pix2Pix одновременно и дискриминатор, и генератор имеют доступ к исходному изображению.
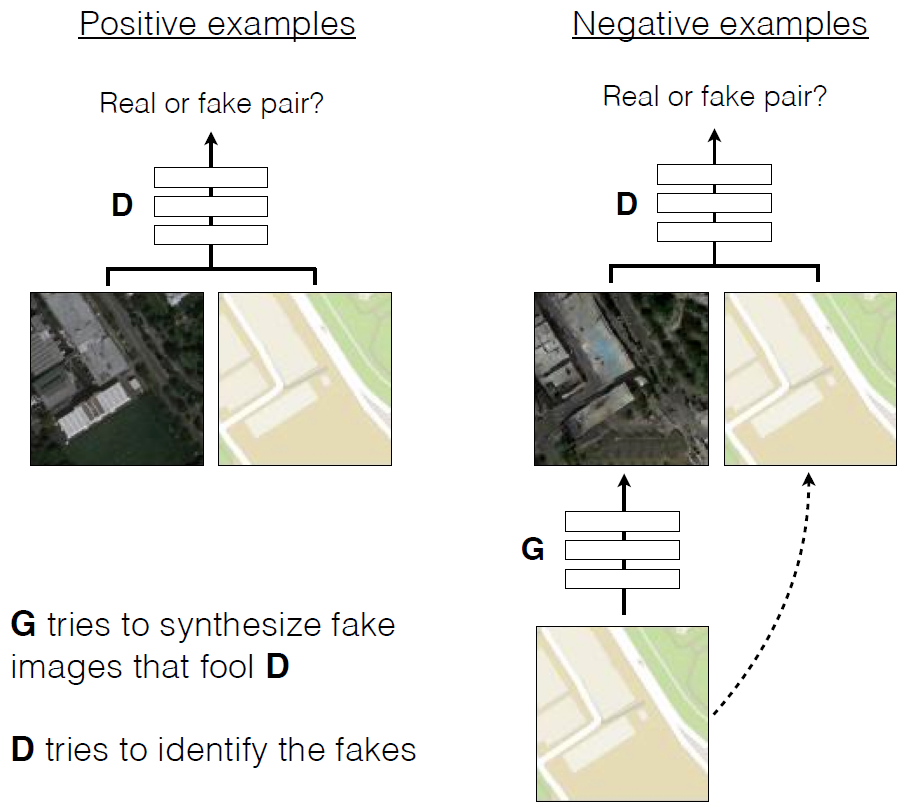
Обучение cGAN предсказывать фотографии аэрофотосъёмки по картам местности

Примеры работы cGAN по трансляции фотографий аэрофотосъёмки в карты местности и наоборот
Научная статья опубликована в открытом доступе, исходный код Pix2pix — на GitHub. Авторы предлагают всем желающим испытать программу.
Источник


