
Кадры четырёх передач, по которым обучалась программа, а также слово «afternoon», произнесённое двумя разными дикторами
Две недели назад рассказывалось о нейросети LipNet, которая показала рекордное качество 93,4% распознавания человеческой речи по губам. Уже тогда предполагалось множество применений для такого рода компьютерных систем: медицинские слуховые аппараты нового поколения с распознаванием речи, системы для беззвучных лекций в публичных местах, биометрическая идентификация, системы скрытой передачи информации для шпионажа, распознавание речи по видеоряду с камер наблюдения и т.д. И вот сейчас специалисты из Оксфордского университета совместно с сотрудником Google DeepMind поведали о собственных разработках в этой области.
Новую нейросеть тренировали на произвольных текстах людей, выступающих в эфире телеканала BBC. Что интересно, тренировка была произведена автоматически, без предварительного аннотирования речи вручную. Система сама распознавала речь, аннотировала видео, находила лица в кадре, а потом училась определять взаимосвязи между словами (звуками) и движением губ.
В результате, эта система эффективно распознаёт именно произвольные тексты, а не экземпляры из особого корпуса предложений GRID, как это делала LipNet. У корпуса GRID строго ограничено структура и словарь, поэтому возможно составление только 33 000 предложений. Таким образом, на порядки уменьшено количество вариантов и упрощено распознавание.
Особый корпус GRID составлен по следующему шаблону:
command(4) + color(4) + preposition(4) + letter(25) + digit(10) + adverb(4),
где цифра соответствует количеству вариантов слов для каждой из шести словесных категорий.
В отличие от LipNet, разработка компании DeepMind и специалистов из Оксфордского университета работает на произвольных речевых потоках на телевизионном качестве картинки. Она гораздо более похожа на реальную систему, готовую к практическому использованию.
ИИ обучали на 5000 часах видео, записанного с шести телепередач британского телеканала BBC с января 2010 года по декабрь 2015 года: это обычные выпуски новостей (1584 часа), утренние новости (1997 часов), передачи Newsnight (590 часов), World News (194 часа), Question Time (323 часа) и World Today (272 часа). В общей сложности видеозаписи содержат 118 116 предложений слитной человеческой речи.
После этого программу проверяли на передачах, которые вышли в эфир между мартом и сентябрём 2016 года.
Программа показала довольно высокое качество чтения. Она корректно распознала даже очень сложные предложения с необычными грамматическими конструкциями и использованием имён собственных. Примеры совершенно точно распознанных предложений:
- MANY MORE PEOPLE WHO WERE INVOLVED IN THE ATTACKS
- CLOSE TO THE EUROPEAN COMMISSION’S MAIN BUILDING
- WEST WALES AND THE SOUTH WEST AS WELL AS WESTERN SCOTLAND
- WE KNOW THERE WILL BE HUNDREDS OF JOURNALISTS HERE AS WELL
- ACCORDING TO PROVISIONAL FIGURES FROM THE ELECTORAL COMMISSION
- THAT’S THE LOWEST FIGURE FOR EIGHT YEARS
- MANCHESTER FOOTBALL CORRESPONDENT FOR THE DAILY MIRROR
- LAYING THE GROUNDS FOR A POSSIBLE SECOND REFERENDUM
- ACCORDING TO THE LATEST FIGURES FROM THE OFFICE FOR NATIONAL STATISTICS
- IT COMES AFTER A DAMNING REPORT BY THE HEALTH WATCHDOG
ИИ значительно превзошёл по эффективности работу человека, эксперта по чтению по губам, который попытался распознать 200 случайных видеофрагментов из записанного проверочного видеоархива.
Профессионал смог аннотировать без единой ошибки всего 12,4% слов, в то время как ИИ корректно записал 46,8%. Исследователи отмечают, что многие ошибки можно назвать незначительными. Например, пропущенное «s» в конце слов. Если подойти к анализу результатов менее строго, то реально система распознала намного больше половины слов в телеэфире.
С таким результатом DeepMind значительно превосходит все остальные программы чтения по губам, в том числе вышеупомянутую LipNet, которая тоже разработана в Оксфордском университете. Впрочем, об окончательном превосходстве говорить пока рано, ведь LipNet не обучали на таком большом наборе данных.
По мнению специалистов, DeepMind — большой шаг к разработке полностью автоматической системы чтения по губам.
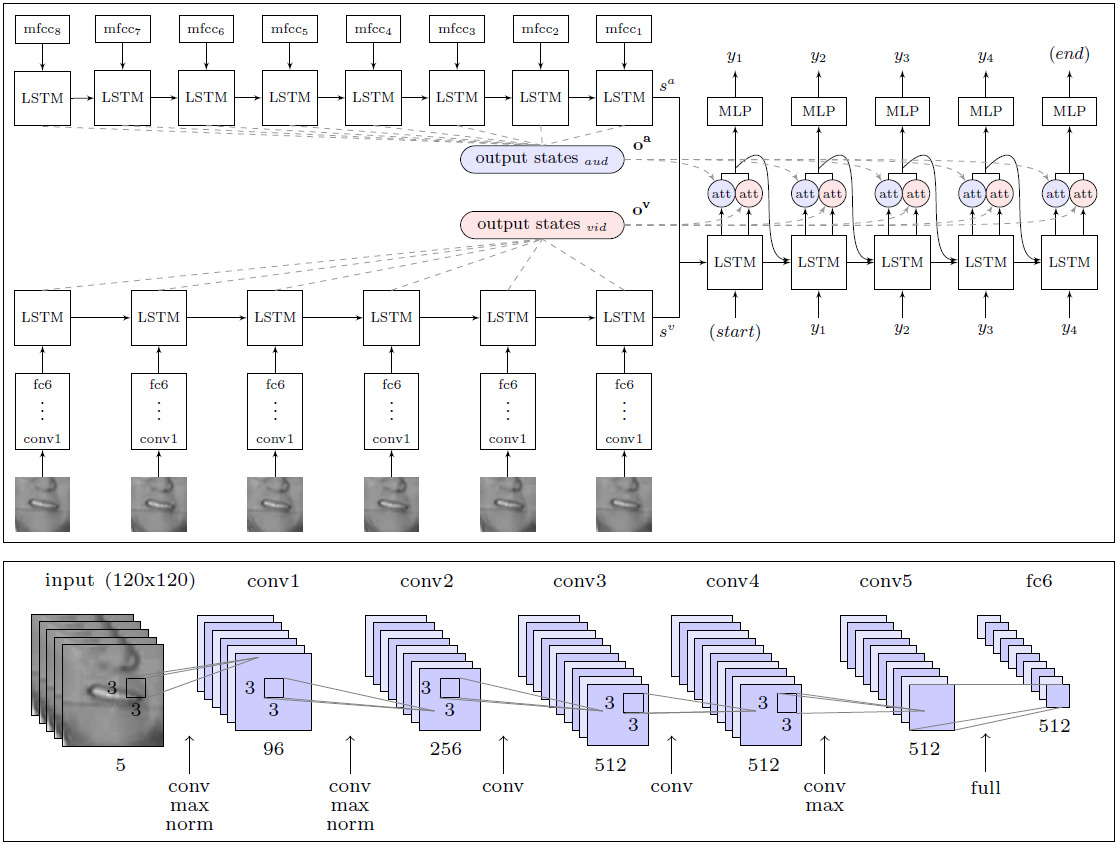
Архитектура модуля WLAS (Watch, Listen, Attend and Spell) и свёрточной нейросети для чтения по губам
Большая заслуга исследователей заключается в том, что они составили гигантский набор данных для обучения и проверки системы с 17 500 уникальных слов. Ведь это не просто пять лет непрерывной записи телевизионных передач на грамотном английском языке, но ещё и чёткая синхронизация видео и звука (по ТВ часто наблюдается рассинхрон до 1 секунды, даже на профессиональном английском телевидении), а также разработка модуля для распознавания речи, которая накладывается на видео и используется в обучении системы чтения по губам (модуль WLAS, см. схему вверху).
В случае малейшего рассинхрона обучение системы становится практически бесполезным, поскольку программа не может определить правильное соответствие звуков и движений губ. После тщательной подготовительной работы обучение программы было полностью автоматическим — она самостоятельно обработала все 5000 видеозаписей.
Раньше такого набора просто не существовало, поэтому и те же авторы LipNet были вынужденны ограничиться базой GRID. К чести разработчиков DeepMind, они пообещали опубликовать набор данных в открытом доступе для обучения других ИИ. Коллеги из коллектива разработчиков LipNet уже сказали, что ждут этого с нетерпением.
Научная работа опубликована в открытом доступе на сайте arXiv (arXiv:1611.05358v1).
Если коммерческие системы чтения по губам появятся на рынке, то жизнь обывателей станет гораздо проще. Можно предполагать, что такие системы сразу встроят в телевизоры и другие бытовые приборы для улучшения голосового управления и практически безошибочного распознавания речи.
Источник


