
Теоретически, в одном грамме ДНК можно разместить один миллиард терабайт данных. В определенных условиях запись может храниться тысячи лет. Но пока не решен вопрос эффективной записи и считывания информации из ДНК. Сейчас над этой проблемой работают корпорация Microsoft и Вашингтонский университет. В апреле этого года партнерам удалось сохранить в ДНК 150 КБ информации — три картинки. Теперь процесс усовершенствовали, и записать удалось уже 202 МБ. В молекулы дезоксирибонуклениовой кислоты записали музыкальное видео OK Go в высоком разрешении, к которому добавили Всеобщую декларацию прав человека, переведенную на 100 языков, топ-100 книг «Проекта Гутенберг» и базу данных по нитям ДНК от Crop Trust’s.

Проект по записи информации в ДНК получил название Project Palix.
Работа велась с синтетической ДНК, закупленной у компании Twist Bioscience в количестве 10 миллионов нитей. Синтетическая ДНК определенной конфигурации разрабатывается по заказу. Стоимость пары оснований такого материала составляет 10 центов. Цена постепенно снижается, и производитель рассчитывает достичь отметки в 2 цента за пару оснований.
Корпорация Microsoft и Вашингтонский университет — не первые, кто решил использовать идею записи данных в ДНК. В 2010 году биологи из Гонконга предложили метод внедрения в геном бактерии E.coli синтетическую ДНК. Китайцы для кодирования информации использовали четверичную систему счисления, по количеству нуклеотидов (0 = A, 1 = T, 2 = C, 3 = G). Ученые переводили тестовые данные в цифры по таблице ASCII (i = 105; G = 71; E = 69; M = 77), потом — в четверичную систему (105 → 1221; 71 → 0113; 69 → 0111; 77 → 0131), и после этого — в цепочку нуклеотидов.
Два года спустя гарвардские ученые, используя другой метод, записали в ДНК 643 килобайта данных. В Гарварде решили отказаться от работы с живыми организмами. Вместо этого синтетическая ДНК внедрялась в молекулу, сгенерированную на специальном ДНК-чипе. Достоинством этого метода является отсутствие опасности потери информации из-за мутаций организма-носителя.
Этим ученым удалось закодировать книгу Черча, причем с сохранением форматирования и иллюстраций.
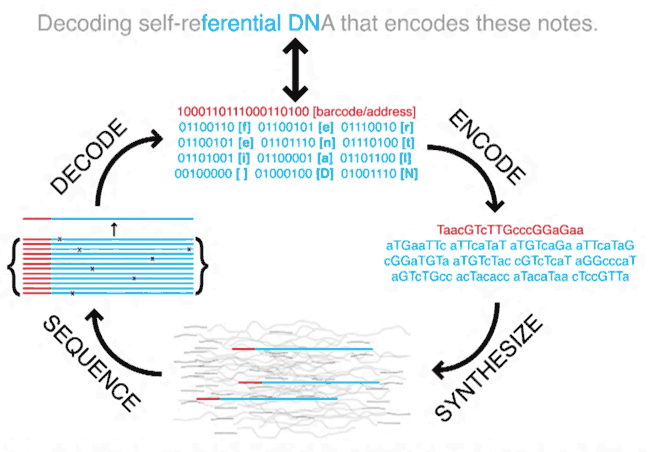
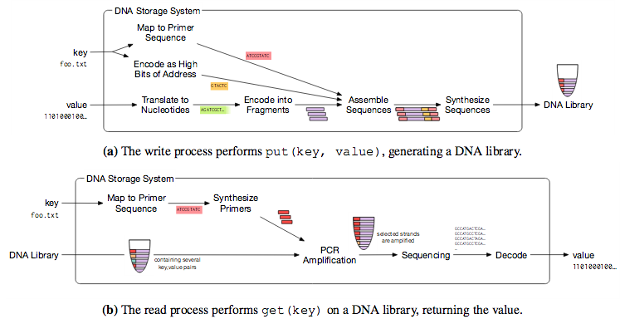
Microsoft и Вашингтонский университет используют метод, предложенный специалистами из Гарварда. Сначала единицы и нули двоичного кода переводятся в комбинации нуклеотидов — аденин, гуанин, цитозин и тимин. После этого синтезируется искусственная ДНК, которая содержит эти данные. Само кодирование информации проводит компания Twist Bioscience, предоставляющая нити синтетической ДНК. Заказчики сообщают последовательность, компания производит цепочку с нуля. Что за информация закодирована в таких молекулах, Twist Bioscience не знает. Для определения конца и начала записываемых файлов в молекулу ДНК вводятся специальные маркеры.

По словам Луис Энрики Сез (Luis Henrique Ceze), одной из участников проекта, за последние несколько лет генетики достигли больших успехов как в кодировании, так и в декодировании ДНК-информации. Точность кодирования информации достигает 100%. Технология расшифровки данных позволяет восстанавливать закодированную информацию без потерь. Но пока что широко применять её нельзя — это возможно делать только в лабораторных условиях. Предстоит работать еще несколько лет до момента вывода технологии записи данных в ДНК на доступный для массового использования уровень.


