
С каких пор программы научились выдавать себя за людей? Каким образом понять, искусная ли перед нами обманка или по-настоящему сильный ИИ? Когда программа справится с машинным переводом или напишет свой первый роман? Сергей oulenspiegel Марков, автор материала «Играть на уровне бога: как ИИ научился побеждать человека», возвращается к теме умных машин в нашей новой нейронной статье.
Умеют ли программы притворяться людьми
В конце 30-х годов прошлого века, когда еще не были созданы первые электронные вычислительные машины, вопросами «разумности» машин стали задаваться специалисты по computer science. Если нечто выглядит как кошка, мяукает как кошка, ведет себя как кошка, в любом эксперименте проявляет себя как кошка, то, наверное, это кошка. Эту идею сформулировал Альфред Айер — английский философ-неопозитивист, представитель аналитической философии.
Всеми нами любимый Алан Тьюринг был более социализирован, чем Айер. Тьюринг любил ходить на вечеринки, а в то время среди интеллектуальной публики была распространена интересная забава — «Игра в имитацию». Заключалась игра в том, что девушку и парня запирали в две разные комнаты, оставляя под дверью широкую щель, в которую участники игры могли просовывать записки с вопросами. Человек, который находился в комнате, писал на вопросы какие-то ответы. Задачей игры было угадать, в какой комнате находится парень, а в какой — девушка. Тьюринг предположил следующее: «А давайте мы будем похожую процедуру использовать для того, чтобы понять, создали ли мы тот самый универсальный ИИ».

Первая программа, которая могла общаться с человеком путем определенной переписки — это ELIZA, созданная в 1966 году. Программа пыталась выдать себя в эксперименте не просто за человека, а за психиатра. Ее стиль общения носит пародийный характер. То есть она говорит на специфическом психиатрическом жаргоне, задает соответствующие типовые вопросы. В принципе, эта программа представляет собой большой набор правил, по которому она находила определенные паттерны в речи человека. В ответ на наличие соответствующего паттерна входной информации, ELIZA определенным образом трансформировала его и выдавала информацию на выход.
Программа могла в некоторых ситуациях людей одурачить. Был проведен эксперимент «AOLiza», когда программа общалась через сеть America Online со случайно выбранными пользователями, и многие из них не догадывались, что в данном случае с ними общалась машина. Понятно, что этот эксперимент нельзя считать хоть каким-то серьезным приближением к прохождению теста Тьюринга.
Cамо название программы ELIZA произошло от имени героини Бернарда Шоу из пьесы «Пигмалион», повествующей о том, как лондонский профессор фонетики Генри Хиггинс пытается из девушки, представительницы общественных низов, сделать настоящую леди, обучая ее правилам поведения и языку высшего общества.
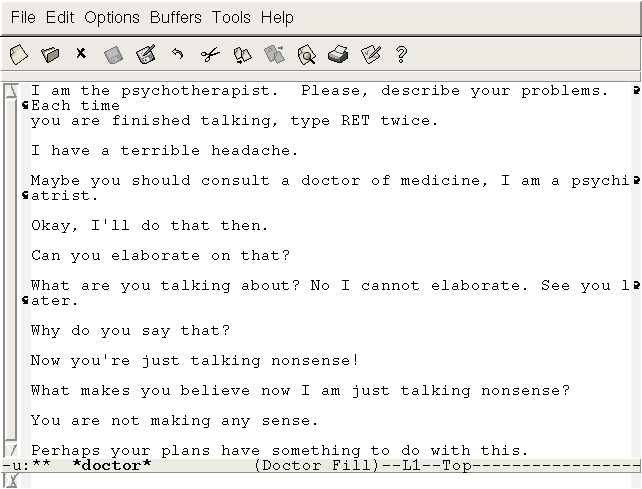
Интересно, что вторая программа такого рода (чат-бот), созданная в 1972 году Кеннетом Колбаем из Стэнфордского университета, была в своем роде шуточной дискуссией с авторами программы ELIZA. Она называлась PARRY. Если ELIZA пыталась выдать себя за врача, то программа PARRY пыталась выдать себя за пациента. PARRY считала себя параноидальным шизофреником.
Интересно, что программа хорошо обманывала профессиональных психиатров. В экспериментах оказалось, что 48% психиатров не в состоянии понять, имеют ли они дело с человеком или с программой. Но здесь, опять же, никакой чистоты эксперимента не было. Если у человека существуют определенные дисфункции, то его поведение может в некоторых ситуациях быть достаточно автоматическим.

Интересная разработка тех времен, которая произвела очень большое впечатление – это программа SHRDLU. Название SHRDLU образовано от ETAOIN SHRDLU — так расположены алфавитные клавиши на линотипах (в соответствии с убыванием частоты появления букв в английском языке). Как, к примеру, сейчас ЙЦУКЕН и ФЫВАПРОЛДЖ.
У SHRDLU был небольшой мир, в котором было представлено ограниченное количество объектов. Это были пирамидки, различные кубики, коробка. И SHRDLU умела общаться на естественном языке с человеком, обсуждая то, что происходит в этом мире, и умела выполнять команды, которые отдавал на естественном языке человек. При этом лексика никак не была ограничена, то есть человек говорить что угодно, а программа могла достаточно свободно отвечать. Вот пример работы SHRDLU:
Человек: Что лежит в коробке?
Компьютер: Синяя пирамидка и синий блок.
Человек: На чем лежит пирамидка?
Компьютер: На коробке.
Человек: Как много блоков находится не в коробке?
Компьютер: Четыре.
Человек: Хотя бы один из них более тонкий, чем тот, про который я тебе говорил? На чем-то он стоит?
Компьютер: Да, стоит на столе.
Человек: Может ли стол собирать блоки?
Компьютер: Нет.
Человек: Может ли пирамидка стоять на блоке?
Компьютер: Да.
Человек: Может ли пирамидка стоять на пирамидке?
Компьютер: Не знаю.
Человек: Хорошо. Поставь пирамидку одну на другую.
Компьютер: Не получается.
Человек: Поставь, пожалуйста, два красных блока друг на друга. Либо зеленый куб, либо пирамидку. Сможешь?» И SHRDLU берет эти блоки, начинает ими оперировать.
Даже сейчас такого рода демонстрация выглядит впечатляющей. Интересно, что исходники SHRDLU можно скачать, программа написана на LISP, есть даже какой-то современный визуализатор под Windows. Если вы откроете ее исходники, то вы увидите, что программа состоит из огромного количества хитроумных правил.
Когда читаешь эти правила, то понимаешь, насколько изощренная логика заложена в программу. Терри Виноград, по всей видимости, проводил много экспериментов, давая возможность разным людям общаться с этой системой. Мирок SHRDLU очень маленький: он может быть описан примерно 50 разными словами. И в рамках такого маленького пространства можно создать впечатление интеллектуального поведения у системы.
Что программы умеют сейчас
Однажды Тьюринга приперли к стене и прямо спросили: «Когда программы пройдут тесты?». Тьюринг предположил, что в 2000 году появятся машины, использующие 109 бит памяти, способные обманывать человека в 30% случаев.

Интересно проверить, сбылся ли прогноз Тьюринга в 2016 году. Программа «Eugene Goostman» изображает из себя мальчика из Одессы. В первом тесте, состоявшемся в 2012 году, программа смогла обмануть судей в 20,2% случаев. В 2014 году в тесте эта же программа, уже модернизированная, в тестах, организованных Университетом Рединга, смогла обмануть судей в 33% случаев. Грубо говоря, с ошибкой плюс-минус 10 лет Тьюринг примерно попал в прогноз.
Потом появилась программа «Соня Гусева», и она в 2015 году смогла обмануть судей в 47% случаев. Стоит отметить, что процедура тестирования предполагает ограничение времени общения экспертов с программой (обычно около 5 минут), и в свете данного ограничения результаты уже не выглядят столь однозначными. Однако для решения многих практических задач, скажем, в области автоматизации SMM, этого более чем достаточно. Отличить продвинутого рекламного бота от человека на практике, скорее всего, не сможет большинство пользователей социальных сетей.
Наверное, самым известным и серьезным возражением на эти успехи является ответ философа Джона Сёрля, который предложил умственный эксперимент, названный «Китайская комната». Представим себе, что есть закрытая комната, в ней сидит человек. Мы знаем, что человек не понимает китайского языка, не сможет прочитать то, что написано китайскими иероглифами на бумаге. Но у нашего подопытного есть книга с правилами, в которой записано следующее: «Если у тебя на входе такие-то иероглифы, то ты должен взять вот такие иероглифы, и составить их в таком порядке». Он открывает эту книгу, она написана на английском, смотрит, что ему подали на вход, а дальше в соответствии с этими правилами формирует ответ, и скидывает его на выход. В определенной ситуации может показаться, что внутри комнаты находится человек, на самом деле понимающай китайский язык. Но ведь индивид внутри комнаты не знает китайского языка по постановке задачи. Получается, что когда эксперимент поставлен по канонам Тьюринга, он, на самом деле, не свидетельствует о том, что внутри сидит некто, понимающий китайский язык. Вокруг этого аргумента развернулась большая полемика. На него есть типовые возражения. Например, аргумент, что если сам Джон не понимает китайский язык, то вся система в целом, составленная из Джона и набора правил, уже обладает этим самым пониманием. До сих пор пишутся статьи в научной прессе на эту тему. Однако бо́льшая часть специалистов по computer science считают, что эксперимент Тьюринга достаточен для того, чтобы сделать определенные выводы.
Машинный перевод

От машин, которые лишь притворяются ИИ, перейдем к программам, реально превосходящим возможности человека. Одна из задач, напрямую связанная с созданием ИИ — это задача автоматизированного перевода. В принципе, автоматизированный перевод появился задолго до появления первых электронных машин. Уже в 1920-е годы были построены первые механические машины, основанные на фототехнике и причудливой электромеханике, которые были предназначены для ускорения поиска слов в словарях.
Мысль использовать ЭВМ для перевода была высказана в 1946 году, сразу после появления первых подобных машин. Первая публичная демонстрация машинного перевода (так называемый Джорджтаунский эксперимент) состоялась в 1954 году. Первый серьезный заход с серьезными деньгами под решение этой задачи был осуществлен в начале 1960-х годов, когда в США были созданы системы, предназначенные для перевода с русского языка на английский. Это были программы MARK и GAT. И в 1966 году был опубликован интересный документ, посвященный оценке существующих технологий машинного перевода и перспектив. Содержание этого документа можно свести к следующему: всё очень-очень-очень плохо. Но, тем не менее, бросать не надо, надо продолжать гранит грызть.
В Советском Союзе тоже были такие исследования, например группа «Статистика речи», возглавляемая Раймундом Пиотровским. Сотрудниками его лаборатории была основана известная фирма ПРОМТ, разработавшая первую отечественную коммерческую программу машинного перевода, базирующуюся в том числе на идеях Пиотровского. Еще где-то к 1989 году была выведена оценка, что система автоматизированного перевода позволяет примерно в 8 раз ускорить работу переводчика. Сейчас эти показатели, наверное, еще немножко улучшились. Конечно, сравниться с переводчиком ни одна система не может, но многократно ускорить его работу в состоянии. И с каждым годом показатель влияния на работу переводчиков растет.
Самой важной вехой, случившейся за последние десятилетия, стал приход на сцену систем, делающих упор на чисто статистические методы. Еще в 1960—1970 годы было понятно, что подходы, основанные на составлении ручных семантических карт языка и синтаксических структур, по всей видимости, ведут в тупик, поскольку масштаб работы невероятно велик. Как считалось, невозможно в принципе поспеть за изменяющимся живым языком.
Сорок лет назад лингвисты имели дело с достаточно маленькими языковыми корпусами. Лингвисты могли либо вручную обрабатывать данные — взять и посчитать количество таких-то слов в «Войне и мире», составить частотные таблицы, проделать первичный статистический анализ, но трудозатраты на выполнение таких операций были колоссальны. И здесь ситуация кардинально изменилась ровно тогда, когда появился Интернет, потому что вместе с Интернетом появилось огромное количество корпусов на естественных языках. Возник вопрос, как бы так сделать систему, которая в идеале не будет знать про язык ничего или почти ничего, но при этом будет на вход получать гигантские корпуса? Анализируя эти корпуса, система автоматически будет достаточно хорошо переводить тексты с одного языка на другой. Этот подход реализован, например, в Google Translate, то есть это система, за работой которой стоит очень мало работы лингвистов. Пока что качество перевода у систем предыдущего поколения — LEC, Babylon, PROMT — выше, чем у Google Translate.
Здесь проблема упирается в то, какой нам нужен препроцессинг для естественного языка, чтобы результаты можно было бы загнать в хорошие предиктивные модели типа сверточных нейронных сетей, и на выходе получить то, что нам нужно. Как препроцессинг должен быть построен, какие специфические знания о естественном языке должны в нем быть, чтобы решить дальнейшую задачу обучения системы?

Вспомним историю «сосиски в тесте» (sausage in the father-in-law). То есть существует сосиска в тесте, но «в тесте» означает не тесто, а тестя. ИИ должен понимать целый ряд человеческих культурных особенностей. Он должен понимать, что, скорее всего, в этом контексте предполагается практика обволакивания тестом при приготовлении сосисок, а не практика помещения сосисок в тестя. Это не значит, что вторая практика не существует. Может быть, в каком-то контексте адекватным переводом будет как раз вставить сосиску в тестя. И здесь только пониманием этих самых cultural references, которые присутствуют в естественном языке на каждом шаге, можно добиться успешного перевода. Либо, может быть, это какая-то статистика, связанная с тем, что на основе статистического анализа корпусов мы просто видим, что в текстах такой тематики чаще всего используется перевод про «сосиску, помещенную в тесто».
Другой пример связан с котом, который родил трех котят: двух белых, одного афроамериканца. Опять же, какой огромный культурный пласт выплывает здесь под переводом. На самом деле, то, что сюда попал афроамериканец — это некий заход в сторону понимания культурных особенностей современного общества. Пока эти проблемы решаются разными костылями типа задания тематики текста. То есть мы можем сказать, что переводим текст по алгебре. И тогда программа должна понимать, что «Lie algebra» — это «Алгебра Ли», а не «алгебра Лжи». Так или иначе, это может работать, но в универсальном плане нам пока очень далеко до системы, которая будет действительно сравнима по качеству с человеком-переводчиком.
В последние годы в сферу машинного перевода активно приходят нейросетевые технологии. Специфическая топология рекуррентных нейронных сетей — так называемая долгосрочно-краковременная архитектура (LSTM — Long short-term memory), применяемая для анализа высказываний, оказалась хорошо применимой для решения задач перевода. Современные тесты показывают, что применение LSTM-сетей позволяет с небольшими трудозатратами достичь качества перевода сопоставимого с уровнем качества конвенциональных технологий.
Еще одна забавная задачка — это сочинение стихов. Если посмотреть на чисто техническую сторону вопроса, как зарифмовать слова и положить их в определенный стихотворный размер, то эта задача была очень простой еще в 1970-е годы, когда Пиотровский начинал ею заниматься. У нас есть словарь слов с ударениями, есть ритмические карты стихотворных размеров — взяли и положили слова в этот размер. Но тут хотелось бы писать что-то осмысленное. В качестве первой мушки-дрозофилы была взята поэзия скальдов, поскольку в ней существует очень простой и четко формулируемый канон.
Гудрун из мести
Гор деве вместе
Хар был умелый
Хамдир был смелый
Сынов убила.
С Ньердом не мило.
Конесмиритель.
Копьегубитель.
— Торд сын Сьярека, перевод С.В. Петрова
Стихотворение скальдов состоит из так называемых кеннингов, и каждый кеннинг — это просто сочетание нескольких слов, имеющее абсолютно четкую эмоционально-смысловую окраску. Все стихотворение составляется из последовательности кеннингов. Задача для программы, сочиняющей стихи, может быть сформулирована таким образом: напиши ругательное стихотворение о вороне. Соответственно, программа по этим критериям из своей библиотеки кеннингов выбирает подходящие, а затем складывает из них стихотворение. Этот эксперимент похож на эксперимент Терри Винограда с SHRDLU, потому что здесь тоже очень простое модельное пространство, и в нем примитивные подходы могут работать, помогая получать неплохие результаты.
Машинный перевод для научных статей

Это машинный корчеватель. Сейчас мы объясним, зачем он тут нужен. Программа SCIgen генерирует наукоподобный бред. Вообще, она это делает на английском языке, но тут можно сделать комбо — взять программу-переводчик и наукоподобный бред с правильными словарями перевести на русский язык. Получится уже бред второго порядка.
К чему мы ведем? Есть такая проблема: обязательное требование для человека, собирающегося защищать диссертацию, иметь несколько публикаций по тематике своей диссертации в журналах из списка Высшей аттестационной комиссии (ВАК). Соответственно, вокруг этого требования развернулся определенный поточный бизнес, а именно появились журналы, принимающие что угодно к публикации. Формально в ВАКовском журнале должен быть рецензент, который должен прочитать ваш текст, и сказать «да, мы принимаем к публикации эту статью» или «нет, не принимаем». Если рецензент говорит «мы принимаем», то вам условно говорят «вы платите суму денег X, и мы вашу статью публикуем». Давно уже у ученых закралось подозрение, что не всегда присутствует человек в процессе оценки.
Известный биоинформатик Михаил Гельфанд при помощи SCIgen сгенерировал наукоподобный бред, перевел его с помощью программы на русский язык, и разослал в целый ряд ваковских изданий статью, которая называлась «Корчеватель: алгоритм типичной унификации точек доступа и избыточности». Людям, которые занимаются алгоритмами или корчевателями, более-менее понятно, что это нечто очень странное, но оказалось, что в России нашелся как минимум один ВАКовский журнал, который принял эту статью к публикации.
Может ли машина написать роман

В 2013 году Дариус Казими запустил проект «Национальный месяц создания романов», в рамках которого программа генерировала текст. Было использовано некоторое количество чат-ботов, которые были помещены в некое условное модельное пространство, где они взаимодействовали. В 2016 году разработчики из японского университета Хакодате написали программу, которая написала роман «День, когда компьютер пишет роман». Работа вышла в финал японского литературного конкурса и обогнала 1450 других произведений, написанных людьми. Совсем недавно стартовал проект, в рамках которого программа прочтет 2865 романов на английском языке и затем попробует написать свой собственный роман. По идее, к концу 2016 года у нас будет какая-то обратная связь про этот проект. Или не будет, если всё закончится ничем.
Есть и другие задачи. Например, достаточно рутинная задача, связанная с написанием информационных текстов для коммерческого сектора. Грубо говоря, для какого-нибудь сайта компании вы пишете рассказ о том, какая это компания, чем занимается. Или вы пишете новости путем рерайта. И есть инструменты, помогающие человеку провести анализ того, что он написал (например сайт Главред.ру, осуществляющий поиск недостатков в текстах, написанных в информационном стиле).
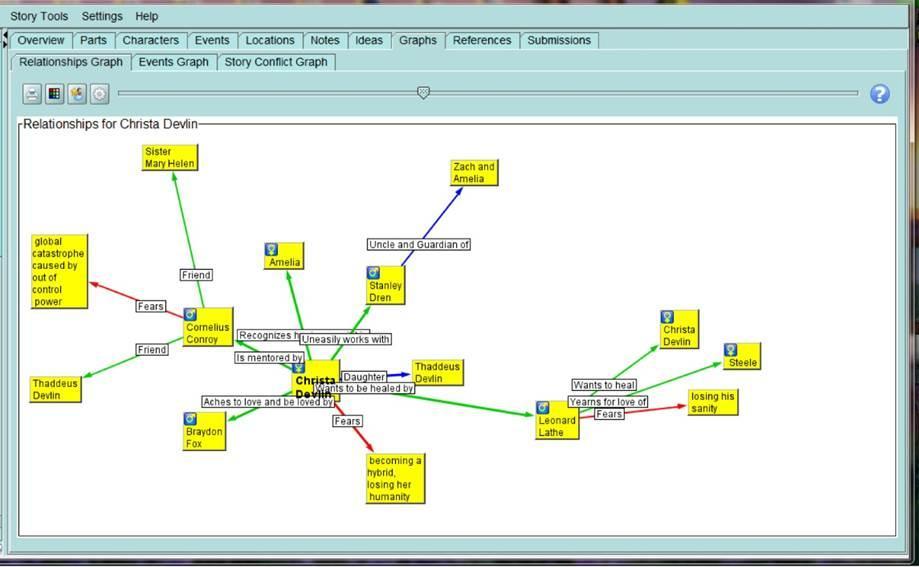
Есть инструменты, которые сейчас активно используются писателями. Помимо анализа орфографии, синтаксиса, стилистики текста, они помогают работать над сюжетом. Писатель может расписывать, что и где происходит в сюжете, иметь карту событий в романе, хранить отношения между героями, трансформирующиеся определенным образом во времени.
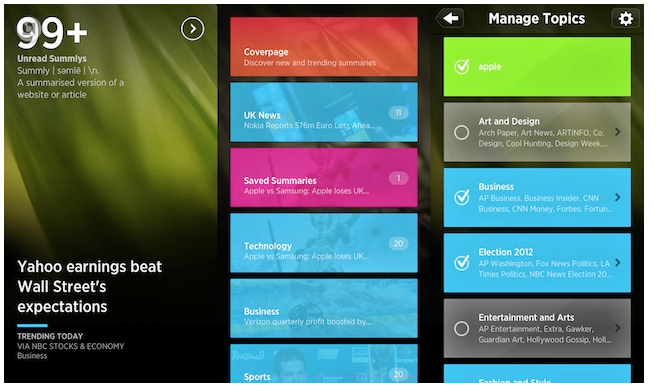
А вот приложение Summly, которое позволяет любую длинную статью ужать до нескольких предложений. Summly читает за вас новости, отжимает из них воду, делает из них такое summary, содержащее максимум 400 слов, и вы читаете уже «выжимку». Это нужно тем, кто хочет читать много новостей, но не хочет читать «воду». Интересно, что эту систему разработал простой английский школьник, который затем продал её за 30 млн долларов Yahoo.
Нейробиологические исследования
Большой сегмент научной деятельности называется Civil Science, то есть это гражданская наука, когда не ученых, а обычных людей привлекают к решению различных научных задач. В этом сегменте большой проект сделал Массачусетский технологический институт.
Жил-был мышонок Гарольд. Его, как водится у ученых, убили, мозг заморозили, нарезали тонкими микронными слоями, засунули эти срезы в сканирующий электронный микроскоп, и получили кучу сканов этих срезов. Сканов этих было так много, что всему научному коллективу, который работает над этим проектом, чтобы расшифровать структуру одной только зрительной коры мышонка, нужно было бы потратить примерно 200 лет. Поэтому ученые из Массачусетского технологического придумали следующий коварный план. Они сделали онлайн-игру, в которой раздают пользователям случайным образом эти самые срезы, и дают задание пользователям срезы по определенным правилам раскрашивать. У вас есть цветные маркеры, и вы с их помощью раскрашиваете свой срез. Если вы сделали это правильно, то вам дают много очков, а если вы сделали неправильно, то очков мало. Вы можете мериться количеством очков с другими участниками этой игры. Почти также увлекательно, как ловить покемонов, но гораздо полезнее.
Ученые из Массачусетского технологического — не простые ребята. На самом деле, у них есть нейронная сеть, в которую дальше пихают все обработанные игроками картинки, там делается свертка, нейронная сеть обучается, и дальше получается нейронная сеть, которая сама, используя срезы, восстанавливает трехмерную структуру синоптических связей.
Эти нейробиологические исследования имеют большое прикладное значение. Те самые сверточные нейронные сети, которые сейчас активно используются в обработке изображений, например в Prisma, были построены на результатах изучения зрительной коры.
Ближайшее будущее: передовой край ИИ

Знаменитый футуролог Рэй Курцвейл раньше говорил, что универсальный искусственный интеллект будет создан в 2045 году, а сейчас он сбросил оценку до 2029 года.
В начале этого года случилась маленькая сенсация. Нейробиологи нашли вторичный контур связи между нейронами через астроциты глиальной ткани. Даже команда проекта компьютерного моделирования неокортекса человека Blue Brain заявила, что в новой модели, которую они собираются презентовать, уже включен этот контур. У них по таймлайну к 2022 году нужно показать модель мозга человека. Они считают, что мозг человека — это примерный эквивалент 1000 мозгов крыс. Возможно, в этом году нас ожидает ещё одно важное открытие в этой области — группа исследователей из Университета Калгари и Университета Алберты (Канада) предположили, что в мозге могут существовать и фотонные связи. Оптические сигналы могут распространяться через миелиновые оболочки. Соответствующее исследование опубликовано на биологическом сервере препринтов BioRXiv.
Везде, где мы используем нейронные сети, мы сталкиваемся с ограниченным числом вычислительных ядер в машине. Если бы число вычислительных ядер было примерно равно числу синапсов, мы бы достигли максимальной производительности за счет распараллеливания. Но ядер маловато. Поэтому сейчас в разных задачах, связанных с нейропроцессингом, где мы пытаемся скопировать то решение, которое предложила природа, идет поиск в направлении создания либо специализированного железа (нейроморфические процессоры), либо использования каких-то устройств, которые лучше подходят для эмуляции нейронных сетей. Например, Microsoft в прошлом году опубликовала статью, посвящённую использованию FPGA как раз для моделирования нейронной сети. Существующие нейросетевые фреймворки, например CNTK, TensorFlow, Caffe, способы использовать для нейросетевых вычислений процессоры видеокарт.
Другой известный проект TrueNorth, создаваемый IBM в рамках государственной программы DARPA SyNapse, остается пока единичным процессором для военных и стоит несколько миллионов долларов. При этом IBM создала целый институт, который разработал специальный язык программирования для этой железки. В открытом доступе результаты этой работы мы, скорее всего, увидим только через N лет. Именно поэтому про TrueNorth в научных новостях говорят, а какого-то движения в community вокруг него нет.
Альтернативным образом развивается направление прямого улучшения мозга. Например, была создана радиоуправляемая крыса. Есть истории, когда берут тележку, к ней подключают мозг крысы, и эта тележка катается по лабиринту. Более того, подобные проекты есть и с мозгом приматов. А это очень интересно, ведь обезьяны типа бонобо или шимпанзе демонстрируют уровень развития интеллекта, сопоставимый с уровнем трехлетнего ребенка.
В связи с успехами в области искусственного интеллекта, возникает вопрос: что же будет дальше, куда мы идем как вид и как технологическая цивилизация? С этим связана одна интересная история, уходящая в истоки человеческой эволюции: наш интеллект это не более чем продукт эволюционного компромисса. Неограниченное увеличение объёма мозга и его сложности невозможно. Во-первых, мозг потребляет очень много энергии, около 20% от общего потребления, хотя его собственная масса около 2% от массы тела. Кроме того, чем больше голова, тем сложнее роды у обезьян. Смертность, травмы при родах сильно возрастают с увеличением головы. Сейчас же, если мы создаем искусственную копию мозга, то мы в известной мере свободны от этих ограничений. Мы можем заведомо обеспечить такой мозг бо́льшим количеством энергии, можем построить бо́льшую нейронную сеть. Такая система по уровню своего интеллектуального развития будет обходить человека по всем направлениям. Мы уже затрагивали тему, к чему в итоге может привести развитие ИИ, но стоит коснуться еще одного варианта развития событий. Вариант на самом деле очень старый и в фантастических произведениях не раз уже появлялся.
В романе Герберта Франке «Клетка для орхидей» земляне используют систему типа «аватар» и с ее помощью исследуют далекую звездную систему. Они оказываются на планете, где находят руины древней цивилизации. На окраинах давно покинутого города они видят, грубо говоря, уровень технологий а-ля наш XX век. Дальше они продвигаются к центру, периметр города сокращается, все более высокие технологии попадаются им. Они приближаются к самому ядру города, и встречаются наконец-то с машинами, которые говорят: «Слушайте, ребята, дальше всё, нельзя пройти. Наши создатели там живут, им хорошо, вы их можете потревожить. Идите отсюда». Люди всё же как-то пробиваются, где-то уговорами, где-то силой. И что они видят? Они видят гигантские чаны, в которых плавают дальние-дальние потомки создателей этих машин, у которых к тому моменту мозг атрофировался, остались одни центры удовольствия, в которые внедрены электроды, по которым ритмически проходят электрические импульсы. Потомки некогда великой цивилизации живут в абсолютном счастье, расслабленности, гармонии с собой и с природой.
Искусственный интеллект в России
Вместо заключения коснемся темы отставания от Запада в направлении исследований ИИ. На самом деле наука сейчас носит во многом интернациональный характер. Просто наши хорошие исследователи, нейрофизиологи, специалисты по computer science публикуются в международной прессе и мало публикуются в прессе российской. Вообще говоря, зачастую публикация в российском журнале с точки зрения научной репутации зачисляется не в «плюс», а в «минус» учёному, потому что обычно это означает, что результаты работы «не дотянули» до уровня стандартов международных научных изданий. Но это не значит, что никаких интересных проектов у нас нет. Например, в России было проведено значимое исследование с reverse engineering нервной системы червя. Плюс есть комьюнити, которое абсолютно интернационально, в него входят энтузиасты, которые обсуждают алгоритмы, делают opensource-проекты. А о некоторых крупных проектах еще только предстоит рассказать. До встречи в следующем посте!


