
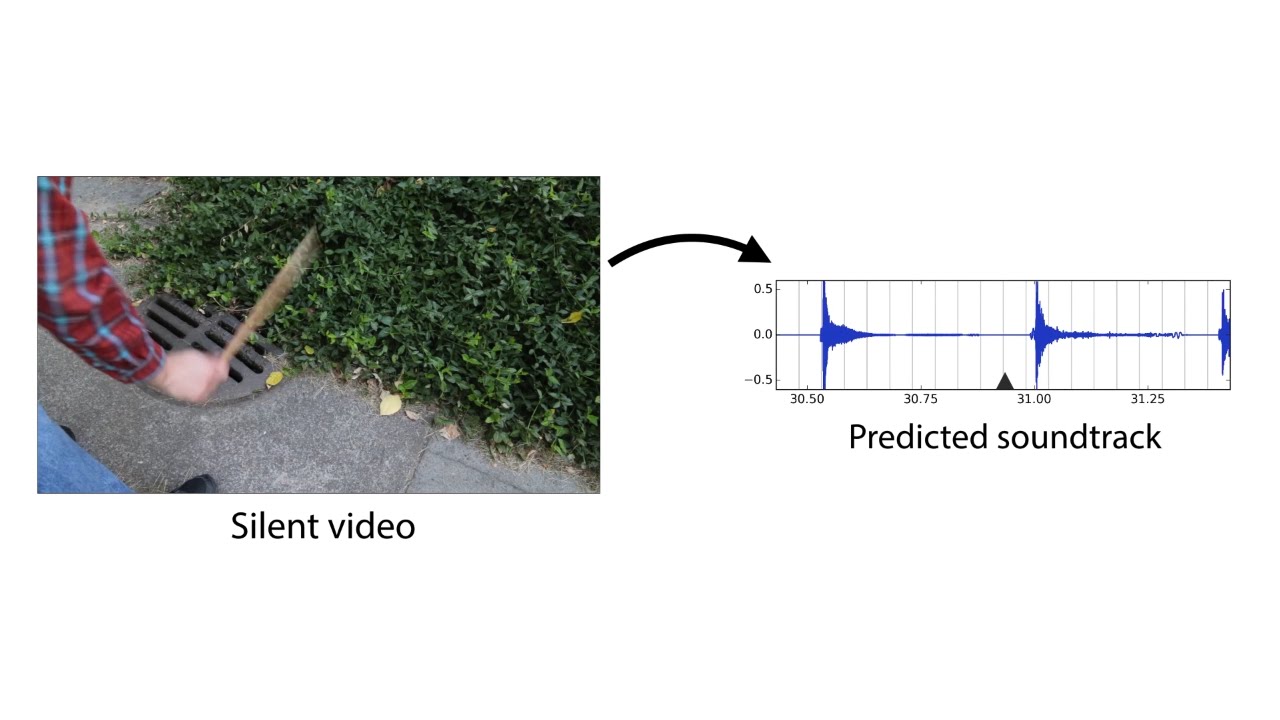
Сотрудники лаборатории информатики и искусственного интеллекта (CSAIL) Массачусетского технологического института и подразделения Google Research спроектировали нейросеть, которая обучилась озвучивать произвольный видеоряд, генерируя реалистичные звуки и предсказывая свойства объектов. Программа анализирует видео, распознаёт объекты, их движение и тип соприкосновения — удар, скольжение, трение и так далее. На основании этой информации она генерирует звук, который человек в 40% случаев считает более реалистичным, чем настоящий.
Учёные предполагают, что эта разработка найдёт широкое применение в кинематографе и на телевидении для генерации звуковых эффектов по видеоряду без звука. Кроме того, она может быть полезна для обучения роботов лучше понимать свойства окружающего мира.
Окружающие звуки многое говорят о свойствах окружающих объектов, поэтому в процессе самообучения будущие роботы могут действовать как дети — трогать предметы, пробовать их на ощупь, тыкать в них палкой, пробовать сдвинуть, поднять. При этом робот получает обратную связь, узнавая свойства объекта — его вес, упругость и так далее.
Издаваемый предметом звук при соприкосновении тоже несёт важную информацию о свойствах предмета. «Когда вы проводите пальцем по стакану с вином, издаваемый звук соответствует количеству жидкости, налитой в стакан», — объясняет аспирант Эндрю Оуэнс (Andrew Owens), ведущий автор опубликованной научной работы, которая пока не готова для научного журнала, а только опубликована в открытом доступе на сайте arXiv.org. Презентация научной работы состоится на ежегодной конференции по машинному зрению и распознаванию образов (CVPR) в Лас-Вегасе в этом месяце.
Учёные подобрали 977 видеороликов, в которых люди совершают действия с окружающими объектами, состоящими из различных материалов: царапают, бьют их палкой и т.д. В общей сложности видеоролики содержали 46 577 действий. Студенты CSAIL вручную разметили все действия, указав тип материала, место соприкосновения, тип действия (удар/царапание/другое) и тип реакции материала или объекта (деформация, статичная форма, жёсткое движение и др.). Видеоролики со звуком использовались для обучения нейросети, а расставленные вручную метки — только для анализа результата обучения нейросети, но не для обучения её.

Нейросеть анализировала характеристики звука, который соответствует каждому типу взаимодействия с объектами — громкость, высота и другие характеристики. При обучении система покадрово изучала видеоролик, анализировала звук в этом кадре и находила соответствие с наиболее похожим звуком в уже накопленной базе данных. Самое главное было научить нейросеть растягивать звук на кадры.
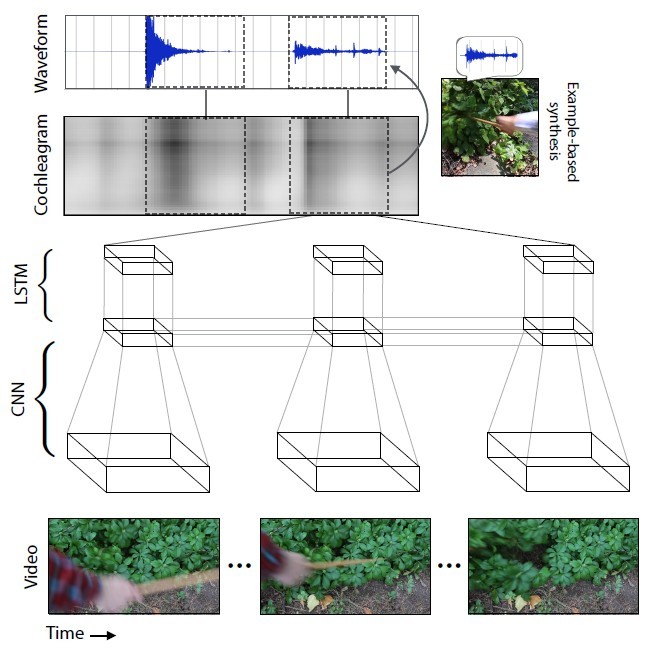
С каждым новым видеороликом точность предсказания звуков увеличивалась.
Сгенерированный нейросетью звук для разных сцен, по сравнению с настоящим

В результате нейросеть научилась точнейшим образом предсказывать самые разнообразные звуки со всеми нюансами: от стучания камней до шуршания плюща.
«Нынешние подходы исследователей в области искусственного интеллекта фокусируются только на одном из пяти органов чувств: специалисты по машинному зрению изучают визуальные изображения, специалисты по распознаванию речи изучают звук и так далее, — говорит Абхинав Гупта (Abhinav Gupta), доцент кафедры робототехники университета Карнеги–Меллон. — Нынешнее исследование — это шаг в правильном направлении, который имитирует процесс обучения таким же способом, каким это делают люди, то есть интегрируя звук и зрение».
Чтобы проверить эффективность ИИ, учёные провели онлайновое исследование на Amazon Mechanical Turk, участникам которого предлагалось сравнить два варианта звукового сопровождения конкретного видеоролика и определить, какой звук настоящий, а какой — нет.
В результате эксперимента ИИ удалось обмануть людей в 40% случаев. Впрочем, по мнению некоторых комментаторов на форумах, обмануть человека не так уж сложно, потому что значительную часть знаний о звуковой картине мира современный человек получает из художественных фильмов и компьютерных игр. Звуковой ряд для фильмов и игр составляют специалисты, используя коллекции стандартных образцов. То есть мы постоянно слышим примерно одно и то же.
В онлайновом эксперименте в двух случаях из пяти люди считали, что сгенерированный программой звук более реалистичный, чем настоящий звук с видеоролика. Это более высокий результат, чем у других методов синтезирования реалистичных звуков.

Наиболее часто ИИ вводил в заблуждение участников эксперимента звуками таких материалов, как листья и грязь, потому что эти звуки более сложные и не такие «чистые», какие издаёт, например, дерево или металл.
Возвращаясь к обучению нейросети, как побочный результат исследования обнаружилось, что алгоритм может различать мягкие и твёрдые материалы с точностью 67%, просто предсказывая их звук. Другими словами, робот может посмотреть на асфальтовую дорожку и траву перед собой — и сделать вывод, что асфальт твёрдый, а трава мягкая. Робот будет знать это по предсказанному звуку, даже не ступая на асфальт и траву. Затем он может ступить куда хочет — и проверить свои ощущения, сверив с базой данных и в случае необходимости произведя коррекцию в библиотеке звуковых образцов. Таким способом в будущем роботы будут изучать и осваивать окружающий мир.
Впрочем, исследователям предстоит ещё большая работа по совершенствованию технологий. Нейросеть сейчас часто ошибается при быстром движении объектов, не попадая в точный момент контакта. Кроме того, ИИ способен генерировать только звук на основании прямого контакта, который записан на видео, а ведь вокруг нас так много звуков, которые не основаны на визуальном контакте: шум деревьев, гул вентилятора в компьютере. «Что было бы по-настоящему здорово, это как-то симулировать звук, который не настолько точно связан с видеорядом», — говорит Эндрю Оуэнс.


