
Одна из кистей удаляет/добавляет деревья, другая — людей и т. д.
Генеративно-состязательные сети (GAN) создают потрясающе реалистичные изображения, часто неотличимые от реальных. С момента изобретения таких сетей в 2014 году в этой области проведено много исследований и создан ряд приложений, в том числе для манипуляции изображениями и прогнозирования видео. Разработано несколько вариантов GAN, и эксперименты продолжаются.
Несмотря на этот огромный успех, по-прежнему остаются многие вопросы. Непонятно, в чём конкретно причины ужасно нереалистичных артефактов, какие минимальные знания нужны для генерации конкретных объектов, почему один вариант GAN работает лучше другого, какие фундаментальные различия закодированы в их весах? Чтобы лучше понять внутреннюю работу GAN, исследователи из Массачусетского технологического института, MIT-IBM Watson AI и подразделения IBM Research разработали фреймворк GANDissection и программу GANpaint — графический редактор на генеративно-состязательной сети.
Работа сопровождается научной статьёй, в которой подробно объясняется функциональность фреймворка и обсуждаются те вопросы, на которые исследователи пытаются найти ответы. В частности, они пытаются изучить внутренние представления генеративно-состязательных сетей. В этом должна помочь «аналитическая структура для визуализации и понимания GAN на уровне юнитов, объектов и сцен», то есть фреймворк GANDissection.
Методом разделения картины на части (segmentation-based network dissection) система определяет группы «интерпретируемых единиц», которые тесно связаны с концепциями объектов. Затем осуществляется количественная оценка тех причин, которые вызывают изменения в интерпретируемых единицах. Это делается «путём измерения способности интервенций контролировать объекты на выходе». Проще говоря, исследователи изучают контекстуальную связь между конкретными объектами и их окружением с помощью внедрения обнаруженных объектов в новые изображения.
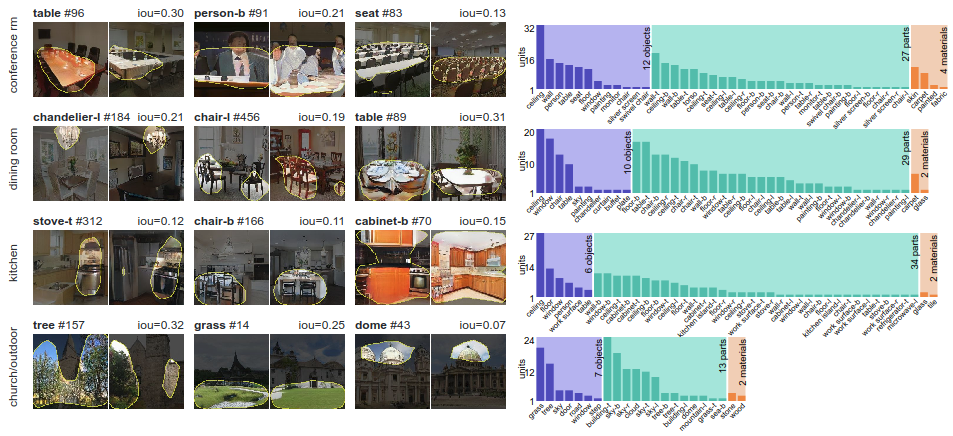
Фреймворк GAN Dissection демонстрирует, что конкретные нейроны в GAN обучаются в зависимости от типа сцены, которую он учится рисовать: например, нейрон пиджака появляется при изучении конференц-залов, а нейрон плиты появляется при рисовании кухонь
Чтобы убедиться, что наборы нейронов управляют рисованием объектов, а не просто коррелируют, фреймворк вмешивается в сеть и активирует и деактивирует нейроны напрямую. Так работает графический редактор GANpaint — это визуальная демонстрация аналитической фреймворка, разработанного авторами.

GANpaint активирует и деактивирует нейроны в сети, обученной для создания изображений. Каждая кнопка на левой панели соответствует набору из 20 нейронов. Всего семь кнопок:
- дерево;
- трава;
- дверь;
- небо;
- облако;
- кирпич;
- купол.
GANpaint умеет добавлять или удалять такие объекты.
Переключая нейроны напрямую, вы можете наблюдать структуру визуального мира, которую научилась моделировать нейросеть.
При изучении результатов работы других генеративно-состязательных сетей у постороннего наблюдателя может возникнуть вопрос: действительно ли GAN создаёт новое изображение или она просто составляет сцену из объектов, с которыми познакомилась во время обучения? То есть может сеть просто запоминает изображения и затем воспроизводит их точно так же? Данная научно-исследовательская работа и редактор GANpaint свидетельствуют, что сети действительно изучили некоторые аспекты композиции, считают авторы.
Одно интересное открытие состоит в том, что одни и те же нейроны управляют определённым классом объектов в различных контекстах, даже если конечный внешний вид объекта сильно варьируется. Те же нейроны могут переключаться на понятие «дверь» независимо от того, нужно добавить тяжёлую дверь на большой каменной стене или маленькую дверцу на крохотной избушке. GAN также понимает, когда можно, а когда нельзя создавать объекты. Например, при активации нейронов двери в нужном месте здания действительно появляется дверь. Но если сделать то же самое в небе или на дереве, то обычно такая попытка не имеет эффекта.
Научная статья “GAN Dissection: Visualizing and Understanding Generative Adversarial Networks” опубликована 26 ноября 2018 года на сайте препринтов arXiv.org (arXiv:1811.10597v2).
Интерактивные демонстрации, видео, код и данные опубликованы на Github и на сайте MIT.
Источник

