В 2013 году на страницах авторитетного научного издания PNAS была опубликована резонансная работа под заголовком «Automated reconstruction of ancient languages using probabilistic models of sound change». Если отбросить академическую терминологию, основная цель исследования заключалась в поиске способа автоматического воссоздания древних словоформ, чтобы избавить ученых от необходимости проводить годы над пыльными манускриптами с карандашом в руках. Зачастую именно такие амбициозные идеи рождаются в моменты интеллектуальных озарений.

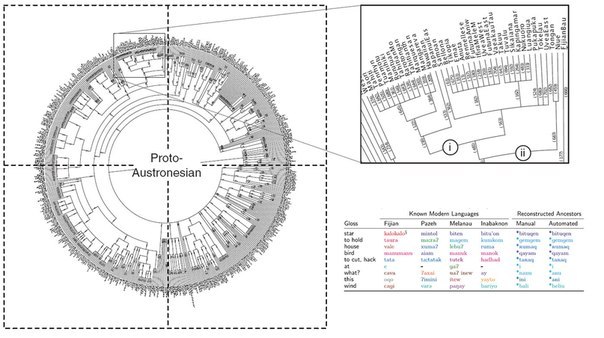
Для тех, кто не является специалистом в данной области, стоит пояснить предмет исследования. Речь идет о реконструкции праязыков — тех наречий, которые не только исчезли из обихода, но и вовсе не оставили после себя письменных памятников. Зачем это нужно? Мотивация схожа с попытками генетиков воскресить мамонтов: это колоссальный вклад в науку и ключ к пониманию эволюционных процессов, только в сфере лингвистики. И методология здесь во многом перекликается с биологической.
Современная наука рассматривает языки как результат эволюции от общих предков. Это напоминает бесчисленные копии одного и того же текста, в которые переписчики раз за разом вносили «типовые ошибки» — фонетические мутации. Глобальное языковое древо можно представить так: ветви и листья — это современные языки, а промежуточные узлы — протоязыки, звучание которых никогда не было зафиксировано. В основании же этой структуры гипотетически находится некий праязык, утраченный человечеством еще на заре цивилизации.
Лингвисты-компаративисты давно научились вручную восстанавливать эти промежуточные звенья, анализируя упомянутые «типовые ошибки». Используя сравнительно-исторический метод, они сопоставляют тысячи слов, выявляют закономерности звуковых переходов и на их основе воссоздают облик праязыка. Однако у этого кропотливого труда есть существенный недостаток: когда речь заходит о крупных языковых семьях, включающих сотни языков, объем данных становится непосильным для человеческого мозга, а время работы начинает превышать продолжительность жизни исследователя.
Как только запрос на автоматизацию процесса был озвучен, к решению задачи подключились математики, внедрив свои алгоритмы в гуманитарную сферу. В очередной раз подтверждается истина: математика — наука вездесущая, способная найти применение в самых неожиданных областях знаний.
«И пришли они, превратив всё в цифры».
Слова, представленные как последовательности звуков (фонем), превратились в строковые данные. Для каждой единицы были определены правила мутаций, аналогичные арифметическим действиям: замена, вставка или выпадение звука. Эту концепцию авторы заимствовали из вычислительной биологии. При воссоздании древних последовательностей ДНК биологи работают с аналогичными «строками», которые природа редактирует посредством замен и делеций.
Основная сложность заключалась в поиске наиболее вероятного сценария изменений. Бездумное комбинирование фонем привело бы к абсурду. Необходимо было вычислить, какая мутация была наиболее естественной для конкретного этапа. В традиционной лингвистике это опирается на интуицию и опыт эксперта (понятие «регулярных звуковых соответствий»). Если же поручить это машине без четких ограничений, она будет генерировать миллиарды бессмысленных вариантов, превращаясь в пресловутую обезьяну с печатной машинкой.
Чтобы избежать этого, помимо оцифровки звуков, были заданы вероятности трансформации слов от поколения к поколению. Иррациональные сценарии развития отсекались с помощью метода Монте-Карло, что позволило программе не тратить ресурсы на заведомо ложные пути. На этом базировалась вся архитектура системы.
Результаты оказались впечатляющими: авторы применили алгоритм к анализу 637 австронезийских языков. Полученные данные сравнили с результатами ручной реконструкции Роберта Бласта — признанного патриарха полевой лингвистики. Используя метрику «расстояния Левенштейна» (количество правок для превращения одной строки в другую), ученые выяснили, что более 85% машинных вариантов отличались от экспертных не более чем на один символ.

Что это означает для науки в целом?
Лингвистическое сообщество получило в свое распоряжение мощный инструмент для оперативного статистического анализа. Это своего рода специализированное ПО для гуманитариев. При этом авторы подчеркивают: технология не заменяет ученого. Без глубоких знаний эксперта программа остается лишь набором алгоритмов, поскольку живые языки постоянно взаимодействуют, заимствуют лексику и развиваются вопреки идеальным математическим моделям. Математика здесь — лишь эффективный инструмент в руках профессионала.
Помимо ускорения работы, автоматизация позволила количественно подтвердить давнюю лингвистическую теорию — «гипотезу функциональной нагрузки», выдвинутую еще в 1955 году. Она гласит, что звуки, играющие ключевую роль в различении смысла слов, менее подвержены изменениям и исчезновению. Проведенная реконструкция предоставила веские доказательства в пользу этой концепции.
Почему же звуковые изменения поддаются моделированию? По сути, это строгая алгоритмизация сравнительного метода, основы которого заложил еще Уильям Джонс.
В 1786 году сэр Уильям Джонс, будучи юристом по профессии и востоковедом по призванию, озвучил тезис о родстве санскрита, латыни и греческого языка. Его знаменитая фраза о том, что эти языки «произошли из общего источника, который, возможно, более не существует», стала фундаментом сравнительного языкознания. Именно с этого момента началась постепенная математизация лингвистики, наполнение её метриками и правилами, что в конечном итоге привело к созданию современных вычислительных методов.
Любопытный факт: отец сэра Уильяма, также носивший имя Уильям Джонс, был выдающимся математиком, соратником Ньютона и Галлея. Именно он ввел в научный обиход символ числа «пи». Вероятно, преемственность поколений и склонность к точному анализу сыграли свою роль в том, как его сын подошел к изучению языковых структур.
Автор: Александр Грибоедов

