R — очень мощный инструмент для работы со статистикой: от предварительной обработки до построения моделей любой сложности и соответствующей графики.
Простой гугл-запрос выдаст большое количество литературы по тому, как «легко и быстро» использовать R. Здесь будут и огромные книги, и многочисленные заметки на Stack Overflow, которые, на первый взгляд, кажутся бесконечной кладезью примеров, из которой каждый в два счета соберет необходимый код для решения конкретной задачи. Однако, на деле это совсем не так. Материалов, которые бы рассказали, например, как построить простой график «с нуля» с готовыми рецептами для решения затруднений, которые возникнут по ходу решения этой задачи, очень мало.
Для решения практических задач нужны конкретные пошаговые инструкции, а не подробное описание всей мощи того или иного пакета. Кроме того, готовые учебные примеры (те же ирисы) зачастую малополезны, поскольку сразу пропускают один из самых важных этапов работы со статистикой — предварительный сбор и обработку самих данных. А ведь именно на эту работу зачастую уходит чуть ли не бóльшая часть всего времени! Отдельной проблемой оказывается создание графиков, которые соответствуют формальным, а чаще — неформальным, — стандартам определенной профессиональной среды.
Мне и моим коллегам регулярно требуется делать всё большее количество визуализаций статистики и основанных на них моделей для публикации научных результатов. Поскольку исследования касаются экономики, многие такие работы похожи и на профессиональную публицистику.
В какой-то момент стало понятно, что для эффективной коллективной работы нужен своего рода полноценный конвейер обработки статистики. Эта статья родилась как вводное руководство для коллег и шпаргалка для самого себя, чтобы запустить этот конвейер. Думается, что этот материал может быть полезен и более широкой аудитории.
Графика в R «без боли»: пошаговое руководство
Базовая настройка R
Для работы нужна стандартная связка: R + RStudio. Они доступны бесплатно для всех распространенных платформ. Сначала устанавливается R, затем RStudio. Здесь проблем обычно не возникает.
Перед работой лучше сразу сохранить новый скрипт где-нибудь в своей файловой системе и сразу установить рабочую директорию R в папку, где хранится скрипт (меню Session — Set Working Directory — To Source File Location). Последнее замечание важно, потому что иначе запуск любого внешнего или собственного скрипта после перезагрузки RStudio не случится. По какой-то причине RStudio по умолчанию не делает этого, что было бы логично.
Даже в базовом пакете R есть стандартные средства визуализации (функция plot), которые позволяют строить многие виды графиков, но всё же для полноценных, гибко настраиваемых иллюстраций этих возможностей явно недостаточно.
Наиболее широкой используемой библиотекой для графики в R является пакет ggplot2, который будем использовать и мы.
Также стоит сразу установить пакеты readxl (для чтения файлов .xls, .xlsx) и dplyr (для работы с массивами), scales (для работы с различными шкалами данных), Cairo (для вывода графики из ggplot в файлы). Всё это можно сделать одной командой:
install.packages("ggplot2", "readxl", "scales", "dplyr", "Cairo")Сбор и подготовка данных
Самое удивительное в том, что этому этапу в любой литературе, будь то серьезная теоретическая книга по прикладной теоретической статистике или руководства конкретных статистических пакетов, посвящено катастрофически мало места и времени. Тем не менее, по опыту самостоятельных исследований и руководства студентами и младшими коллегами известно, что именно на этот этап может приходиться львиная доля времени и сил, поэтому очень важно экономить их хотя бы при решении чисто технических задач.
Вопросов здесь два:
- Как выбрать правильный формат файла?
- Как лучше всего структурировать данные?
С форматом дилемма проста: CSV против Microsoft Excel (не так уж важно, «новый» .xlsx старый» .xls). Многие считают, что CSV выигрывает за счет простоты (по сути, это обычный текстовый файл, в котором значения столбцов отделяются запятой или точкой с запятой) и скорости. Но я выбираю Excel в силу двух причин: во-первых, в таком файле можно хранить несколько таблиц одновременно на разных вкладках, во-вторых, что более важно, не приходится задумываться о выборе правильного разделителя колонок и десятичного знака. Для CSV это часто приходится прописывать вручную в коде R и следить за тем, чтобы файл с данными сохранялся с такими же настройками.
Структурирование данных — вопрос более сложный, требующий базового понимания того, как должны быть устроены базы данных. Если не вдаваться в теорию реляционных баз данных про разные нормальные формы, то таблица данных должна быть избыточной, то есть содержать лишние столбцы. Это нужно для того, чтобы потом уже в скрипте в R иметь возможность гибко отбирать те или иные фрагменты информации для дальнейшей обработки. Например, если мы хотим изобразить примитивный временной ряд, то мы должны сделать колонки, соответствующие всем возможным группировочным признакам. Например, если это ряд ежегодных наблюдений над численностью населения условного города Северовосточинска, то нам понадобятся следующие столбцы: year (год), var (название показателя), value (значение показателя).
| year | var | value |
|---|---|---|
| 1990 | Численность населения | 102 |
| 1991 | Численность населения | 103 |
| 1992 | Численность населения | 104 |
К этому стилю представления информации мы будем приводить любые исходные данные.
Пример
Задача: построить сопоставление динамики объемов лесозаготовки в России, Сибирском федеральном округе и Красноярском крае в 2009—2018 гг.
Данные для этой задачи получить довольно просто: достаточно найти соответствующий показатель в Единой межведомственной информационно-статистической системе. Дальше возникает тонкость. Можно сразу скачать данные в формате .xlsx и затем вручную структурировать их так, как показано выше. К счастью, некоторые источники информации (например, ЕМИСС) позволяют делать это возможностями самого сервиса, что сильно упрощает работу и сокращает время, требуемое для ее выполнения.
Итак, для ЕМИСС достаточно перейти в режим «Настройки» (соответствующая кнопка в правом верхнем углу страницы данных) и переместить все признаки, кроме «Период» из графы «Столбцы» в графу «Строки». Получается таблица, практически готовая для нашей дальнейшей работы. Далее уже в Excel (или любом другом подходящем редакторе) есть смысл привести структуру таблицы к виду, похожему на представленный выше и убедиться в том, что первая строка содержит только названия переменных, причем данных латиницей (в принципе, R может работать и с русскоязычными заголовками, но это неудобно при написании кода). Получилась такая таблица (приводится фрагмент в несколько строк).
| title | location | year | value |
|---|---|---|---|
| Объем заготовленной древесины | Россия в целом | 2009 | 158868,3 |
| Объем заготовленной древесины | Россия в целом | 2010 | 173633.7 |
| Объем заготовленной древесины | Сибирский ФО | 2009 | 47161.58 |
| Объем заготовленной древесины | Красноярский край | 2009 | 12111.48 |
| Объем заготовленной древесины | Красноярский край | 2010 | 12078.6 |
Теперь можно назвать этот лист logging, сохранить всю книгу в файл graphs.xlsx и переходить в RStudio.
Подключаем нужные библиотеки.
library(ggplot2)
library(readxl)
library(Cairo)
library(scales)
library(dplyr)Если график готовится для русскоязычного издания, нужно обязательно настроить соответствующую локаль. Самый современный вариант, который будет работать в большинстве случаев — это, разумеется, кодировка UTF-8:
Sys.setlocale("LC_ALL", "ru_RU.UTF-8")Если система старая (какой-нибудь древний Windows или Linux), то понадобится сначала понять, какая кодировка используется по умолчанию — это всё уже не такая простая задача, которая далека от цели данной статьи.
Теперь нужно загрузить данные в R.
df_logging <- read_excel("graphs.xlsx", sheet ="logging")Опция sheet здесь задает имя листа внутри книги Excel, из которого будут загружаться данные.
Построим самый простой вариант требуемого графика.
ggplot(data=df_logging, aes(x=year, y=value)) +
geom_line(aes(linetype=location))

В принципе, практически «из коробки» получился весьма достойный график, который вполне пригоден для начального анализа изучаемого процесса, но с точки зрения возможной публикации требует еще значительной доработки.
Сначала приведем сам по себе графический стиль к более академическому. В пакете ggplot2 есть несколько готовых базовых тем оформления. Наиболее подходящей для нашего случая можно признать тему theme_classic. В рамках ее настройки можно сразу задать базовый кегль шрифта и его гарнитуру. Мои личные предпочтения принадлежат современной шрифтовой системе PT Sans, PT Serif, PT Mono. Но, разумеется, можно задать более классический Times или Helvetica. Также, у издания, в котором планируется публикация, на этот счет могут быть особые указания. Базовый кегль опытным путем определен как 12 пт.
ggplot(data=df_logging, aes(x=year, y=value)) +
geom_line(aes(linetype=location)) +
theme_classic(base_family = "PT Sans", base_size = 12)
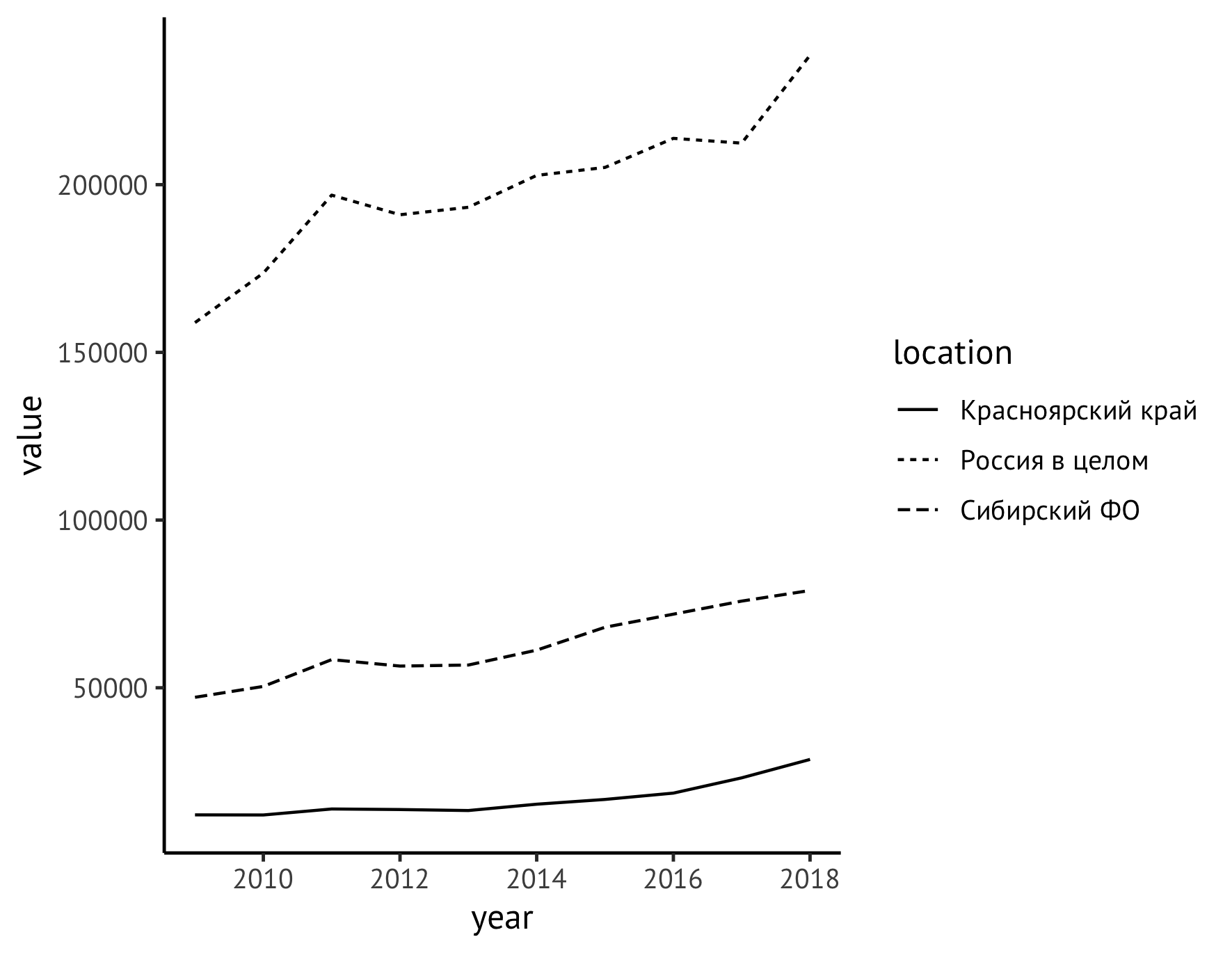
Далее передвинем легенду из правого поля графика вниз (с помощью инструкции theme) и одновременно зададим осмысленные названия осям (инструкция labs). Вдоль оси Y напишем название показателя с единицами измерения («Объемы лесозаготовки, млн куб. м»), а подписи по оси X удалим вовсе, поскольку ясно, что там отмечены годы.
ggplot(data=df_logging, aes(x=year, y=value)) +
geom_line(aes(linetype=location)) +
theme_classic(base_family = "PT Sans", base_size = 12) +
theme(legend.title = element_blank(), legend.position="bottom", legend.spacing.x = unit(0.5, "lines")) +
labs(x = "", y = "Объемы лесозаготовки, тыс. куб. м", color="")

Чтобы сделать единицы измерения показателя более удобными для восприятия, перейдем от тыс. куб. м к миллионам. Для этого нужно просто разделить значения на 1000, то есть откорректировать первую строку нашего кода следующим образом:
ggplot(data=df_logging, aes(x=year, y=value/1000))Одновременно нужно изменить единицы измерения в надписи:
labs(x = "", y = "Объемы лесозаготовки, млн куб. м", color="")И сразу немного улучшим стиль изображения, добавив точки для обозначения каждого наблюдаемого значения, для чего допишем инструкцию:
geom_point(size=2)Также можно явно задать стиль самих линий. Логично показатель для России сделать сплошной линией, а для СФО и Красноярского края — разными версиями прерывистых:
scale_linetype_manual(values=c("twodash", "solid", "dotted"))Теперь общий код и график выглядят так:
ggplot(data=df_logging, aes(x=year, y=value/1000)) +
geom_line(aes(linetype=location)) +
geom_point(size=1) +
theme_classic(base_family = "PT Sans", base_size = 12) +
theme(legend.title = element_blank(), legend.position="bottom", legend.spacing.x = unit(0.5, "lines")) +
scale_linetype_manual(values=c("twodash", "solid", "dotted")) +
labs(x = "", y = "Объемы лесозаготовки, млн куб. м", color="")

Остается решить более содержательную задачу — повысить информативность нашего графика. Сейчас по нему видно, что в целом показатель для всех объектов наблюдения рос, причем примерно с 2014 года сильнее, чем прежде. Но было бы куда нагляднее, если бы мы изобразили прямо на графике еще и значения в первый и последние годы и, скажем, в пиковом 2011-м. В этом поможет новая инструкция geom_text:
geom_text(aes(label=format(value/1000, digits = 3, decimal.mark = ",")),
data = subset(df_logging, year == 2009 | year == 2018 | year == 2011),
check_overlap = TRUE, vjust=-0.8)На первый взгляд, выглядит довольно сложно, и надо сказать, что действительно собрать ее было не так просто. Постараюсь объяснить, что здесь происходит. Сама по себе geom_text добавляет на график текстовые надписи. Для этого инструкции необходим набор данных data. Если бы мы указали в нем непосредственно df_logging, то получили бы надписи над каждой точкой. Так делают довольно часто, но для достаточно простых динамических рядов, как наши, такой подход только создаст ненужный визуальный шум, не снабдив нас новой информацией о поведении наблюдаемого показателя. Поэтому мы возьмем только те годы, которые существенны для понимания динамики показателя: 2009 (начало наблюдений), 2011 (локальный пик), 2018 (конец наблюдений). В этом поможет стандартный subset.
Для корректного отображения чисел в соответствии с русскоязычной традицией нам нужна запятая как разделитель целой и десятичной частей (decimal.mark), а для отсечения количества знаков после запятой — инструкция digits. Различные эксперименты с ней, в том числе с применением функции round привели к тому, что если нам нужен один знак после запятой, в digits надо передать значение 3.
Опция check_overlap здесь напрямую не нужна, но может пригодиться в других случаях: это автоматический контроль наложения надписей друг на друга. Опция vjust управляет размещением надписей по вертикали. Значение подобрано, исходя из вкусовых соображений.
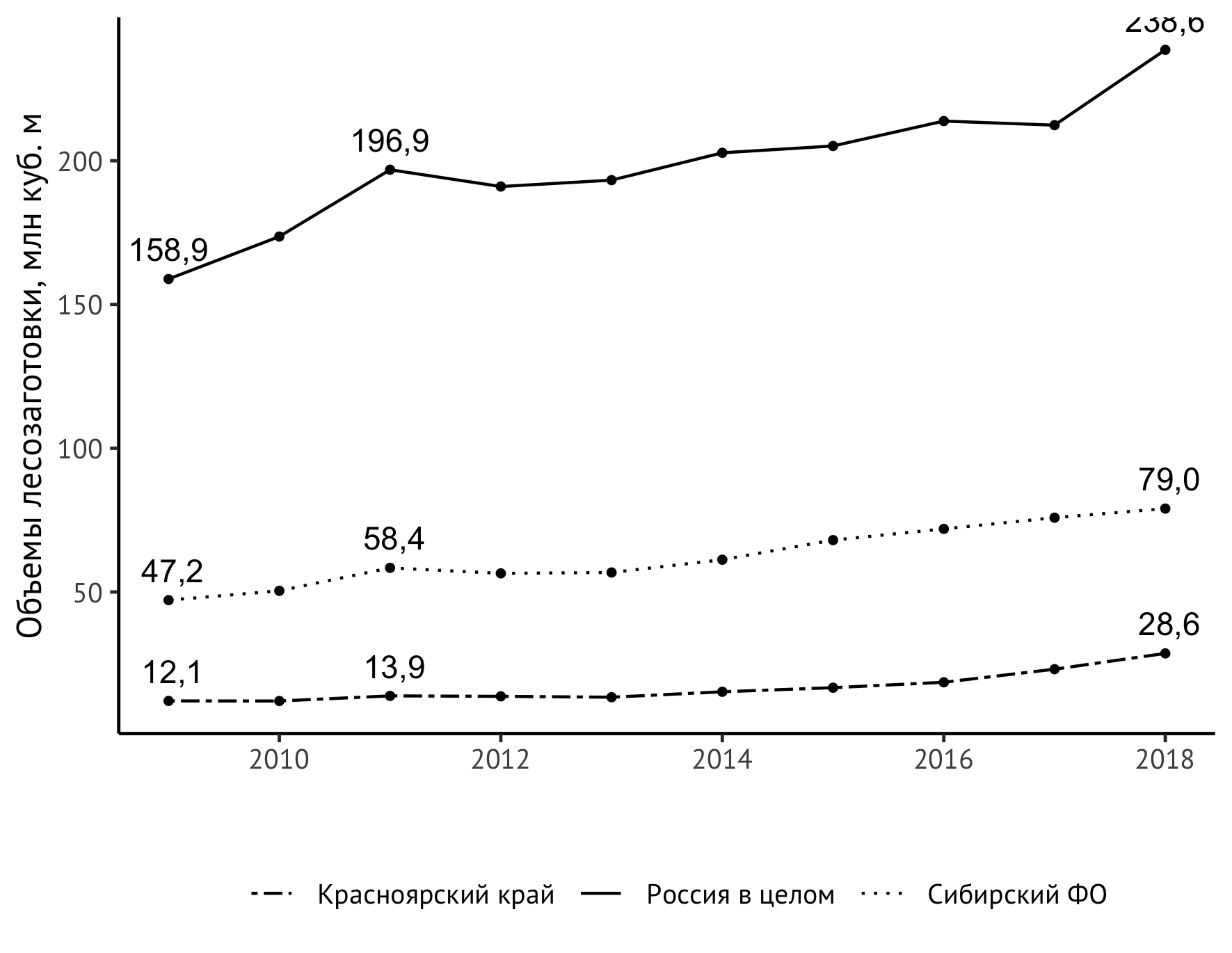
Теперь график действительно интересно рассматривать!
Но обнаружилась неожиданная проблема — верхнее правое значение «срезается» размером изображения по вертикали. Решить эту проблему можно разными способами. Я выкрутился с помощью небольшого растяжения шкалы вертикальной оси с указанием явной верхней границы в 250 млн куб. м:
scale_y_continuous(limits = c(0,250))
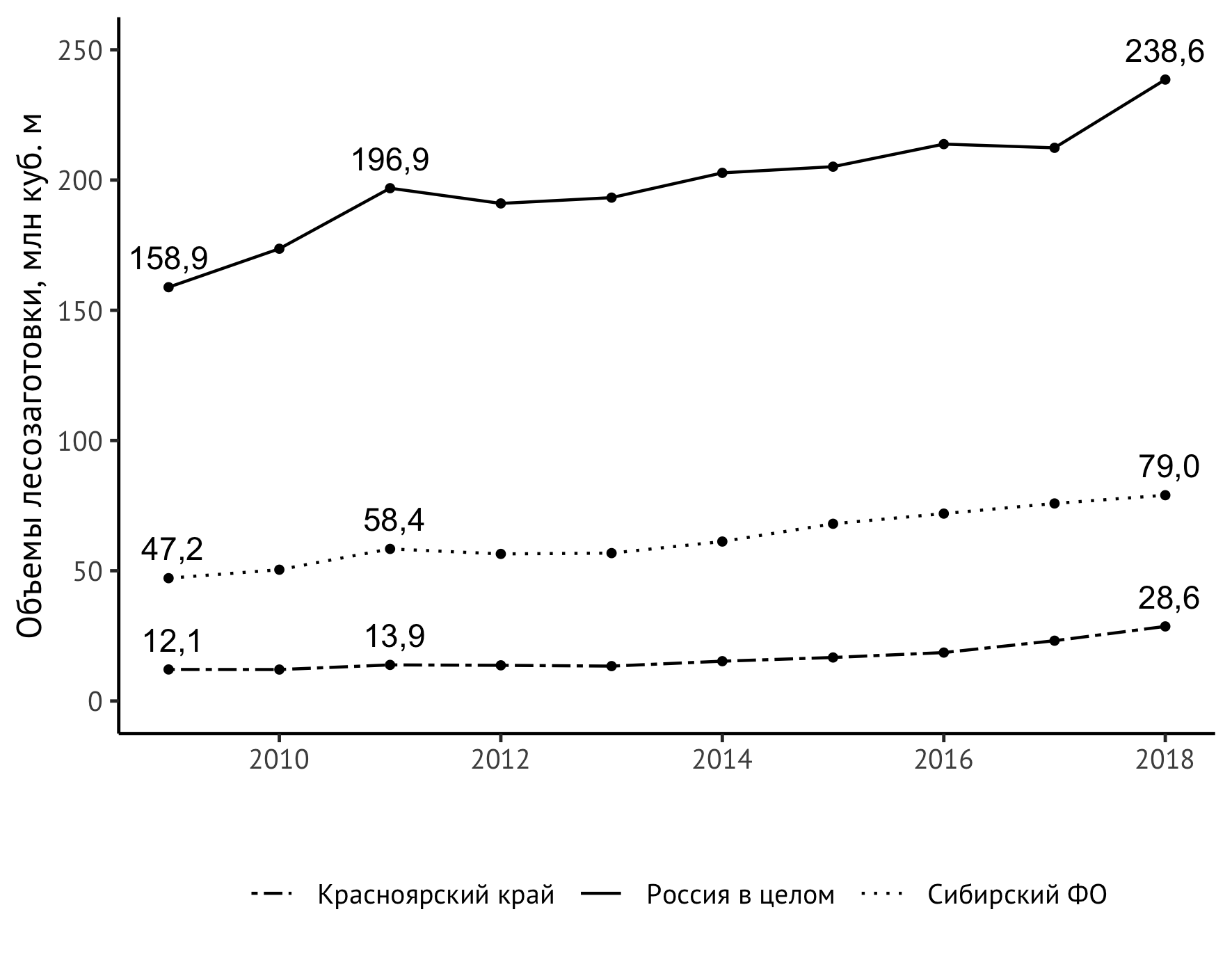
Готово! Итак, итоговый код выглядит так:
ggplot(data=df_logging, aes(x=year, y=value/1000)) +
geom_line(aes(linetype=location)) +
geom_point(size=1) +
theme_classic(base_family = "PT Sans", base_size = 12) +
theme(legend.title = element_blank(), legend.position="bottom", legend.spacing.x = unit(0.5, "lines")) +
geom_text(aes(label=format(value/1000, digits = 3, decimal.mark = ",")),
data = subset(df_logging, year == 2009 | year == 2018 | year == 2011),
check_overlap = TRUE, vjust=-0.8) +
geom_text(aes(label=format(value/1000, digits = 3, decimal.mark = ",")),
data = subset(df_logging, year == 2009 | year == 2018 | year == 2011),
check_overlap = TRUE, vjust=-0.8) +
scale_linetype_manual(values=c("twodash", "solid", "dotted")) +
scale_y_continuous(limits = c(0,250)) +
labs(x = "", y = "Объемы лесозаготовки, млн куб. м", color="")Полученное в итоге изображение входит в монографию: Структурная модернизация как фактор повышения конкурентоспособности региона (на примере Красноярского края) / под ред. Шишацкого Н. Г. — Новосибирск: ИЭОПП СО РАН, 2020 (в печати).
Экспорт
Встроенный в RStudio плагин просмотра графиков позволяет экспортировать изображения в несколько форматов без дополнительных команд, буквально в несколько кликов. Проблема в том, что для практических задач этот сервис оказывается практически бесполезным. При сохранении в растровые форматы (.jpg, .png), по умолчанию выставляется очень низкое разрешение, поэтому при импорте изображения, например, в Word, оно будет размытым. С векторными .eps или .pdf ситуация откровенно хуже: сохранение происходит либо с ошибками, не позволяющими затем открыть файл, либо сохраняется без возможности использования русскоязычных надписей.
Решением является использование функции ggsave из пакет ggplot.
Если на выходе требуется обычный растровый файл, например, формата .png, всё достаточно просто:
ggsave("logging.png", width=709, height=549, units="px")Геометрию (опции width и height) и единицы измерения (units) можно и не указывать, но тогда по умолчанию изображение будет экспортировать квадратным, что вряд ли удобно. Поэтому лучше придумать свою пропорцию и необходимый размер и задать эти параметры вручную, как это сделано в вышеприведенной строке кода.
Для последующего использования изображения в бумажных изданиях разумно экспортировать изображение в векторные форматы, чтобы потом при верстке была возможность свободного изменения геометрии изображения. Многие журналы предпочитают формат .eps — его же удобно использовать для экспорта в Word. Нам понадобится уже установленный и подключенный драйвер Cairo:
ggsave(filename = "export.eps", width=15, height=11.6, units="cm", device = cairo_ps)Файлы будут сохраняться в текущую директорию, в которой расположен скрипт R.
Что еще почитать
Литературы по графике в R довольно много. Вот несколько примеров, первым из которых является работа автора пакета ggplot:
- Wickham, Hadley. ggplot2: Elegant Graphics for Data Analysis;
- Chang, Winston. R Graphics Cookbook, 2nd edition;
- Prabhakaran, Selva. Top 50 ggplot2 Visualizations — The Master List (With Full R Code).
Наверное, лучшей и наиболее подробной книгой по графике в R на русском языке назовем книгу Тимофея Самсонова. Визуализация и анализ географических данных на языке R. Это отличный подробный путеводитель по очень многим общим и специфическим задачам, которые можно решить с помощью R.
Также можно посоветовать книгу на русском про R в целом:
Шитиков В. К., Мастицкий С. Э. Классификация, регрессия, алгоритмы Data Mining с использованием R. 2017.
Просто интересный и мотивирующий пример — мощная презентация об использовании ggplot2 при подготовке рисунков для влиятельной газеты Financial Times.


