
Иногда в нашей жизни случаются неожиданности (и даже неприятности), но, если относиться к своим поступкам ответственно, то можно признать, что значительная часть происходящего — следствие собственных действий, а не цепь случайных событий. В целом, это вопрос уверенности в себе. Можно вообще не переживать, не сомневаться, не думать об этих вещах и заниматься чем-то прекрасным. С другой стороны, возможность найти собственную инструкцию по эффективной эксплуатации открывает новые возможности. Все очень просто: есть несколько вещей, которые человеку хочется знать наверняка.
- Первое: к каким болезням он наиболее предрасположен. Возрастные заболевания есть следствие образа жизни, а не чей-либо умысел.
- Второе: здоровье детей. Опять же, говорить об этом имеет смысл, если речь идет об ответственном человеке, который осознанно планирует свою семью, а не экономит на средствах контрацепции, игнорируя последствия.
- Третье: что делать, чтобы жить лучше. Человеческий организм — это механизм. И хотя принципы работы у всех одни, они могут несколько различаться от тела к телу. То, что подходит одному человеку, может быть вредно для другого.
- Четвертое: что «я» такое. С точки зрения функционирования, знание о своем происхождении не поможет жить дольше или лучше. Скорее это позволит ощутить себя персонажем истории человечества, героем, действующим и развивающимся независимо от чьих-то сиюминутных интересов или личных убеждений.
Все это можно узнать из ДНК, прочитав определенные участки генов. Ген — это отдельный смысловой фрагмент ДНК, который в самом простом случае кодирует отдельный признак. Под словом «фенотип», кстати, следует понимать совокупность всех признаков наблюдаемого состояния (например, цвет глаз, форму мочки, склонность к диабету, усваиваемость лактозы). И тогда возникает тот же вопрос, что и в школьные годы: что именно нужно читать, можно ли читать не все и как разобраться с прочитанным.
Чтобы сделать из технологии прогностических ДНК-тестов массовую медицинскую услугу, нужно обратить внимание на несколько тонких моментов в анализе данных. Во-первых, это проблема персонализации: отбирать маркеры необходимо тщательно. Большинство исследований, направленных на установление ассоциации «генотип — фенотип», проводятся на больших выборках. Выборки (анализируемые группы людей), как правило, не очень разнородны: они могут быть объемными, но состоять из представителей одной этнической группы. С одной стороны, это упрощает статистический анализ в рамках исследования, с другой — ставит вопрос о релевантности обнаруженной ассоциации по отношению к другим группам людей.
Вторая проблема заключается в количестве маркеров — тот самый случай, когда необходимо найти золотую середину. И тут не обойтись без вечного балансирования между двумя параметрами теста: чувствительностью и специфичностью. Увеличение числа генетических маркеров, несомненно, повышает чувствительность анализа к определенным заболеваниям. И вместе с тем специфичность теста может падать. Так как речь идет о, например, выявлении предрасположенности к серьезным заболеваниям, ложноположительная ошибка при выявлении страшного диагноза будет опаснее, чем уточнение вероятности развития заболевания. Помимо этого, увеличение числа маркеров ведет к повышению себестоимости тест-системы, что также затрудняет выход на масс-маркет.
Универсального решения для этих проблем не существует. На начальном этапе работы исследователь сталкивается с ситуацией, когда «есть много статей, и их все нужно прочитать». По этой причине научный отдел Genotek предложил алгоритм отбора, который значительно упрощает выбор полиморфизмов для анализа признака. Важно, что речь идет именно о полиморфизмах, а не о генах целиком: у двух мужчин на каждой из X хромосом есть один и тот же ген андрогенового рецептора, но у первого мужчины в локусе rs6152 находятся аденины (AA), а у второго — гуанины (GG). Вероятность того, что у последнего шевелюра к 40 годам останется такой же пышной, составляет около 30%. В данном случае чтобы понять это, не нужно прочитывать последовательность гена целиком — достаточно найти и прочитать всего одну точку на ДНК, а затем сравнить ее с той, что лежит напротив.
Что искать
Характерные черты, которые мы перенимаем у своих предков, генетики называют фенотипическими особенностями. Фундаментальная проблема биологии в целом — это взаимосвязь генотипа и фенотипа, а также то, как одно кодирует другое. В нашем случае есть два взгляда на наследуемость фенотипических особенностей. С одной стороны, различаться может характер наследования. Так, отдельный признак может не наследоваться вовсе, а его проявление никак не будет связано с генетическим вкладом. Такие признаки, возникающие под влиянием образа жизни или внешних условий среды, не представляют интереса для разработчиков ДНК-тестов.
С другой стороны, если признак наследуется, то важно понимать, какое именно генетическое взаимодействие лежит в основе наблюдаемого состояния. В самом простом случае влиять на развитие заболевания может всего один ген — тогда речь идет о моногенном наследовании. Например, фенилкетонурия — метаболическое заболевание, которое развивается в связи с «поломкой» в одном гене. В таком случае нельзя говорить о предрасположенности: если у человека уже есть две копии сломанного гена, у него все равно разовьется заболевание. Однако в такой ситуации генетическая диагностика может уточнить диагноз для выбора более адекватного лечения.
Сложнее, когда вклад в фенотипическую особенность вносят несколько генов. Важно разобраться с тем, как именно происходит формирование признака, полигенный ли он или мультифакторный. Полигенный признак развивается в результате нескольких полиморфизмов — тут также нет вероятностного характера развития признака. При определенном сочетании полиморфизмов можно достоверно получить определенный цвет глаз человека. Сейчас проблема предсказания цвета глаз (и других внешних черт) стоит в криминалистике. Ее решают как с помощью математических моделей, так и путем обучения нейросетей на больших наборах данных. Мультифакторный фенотип, помимо генетической основы, развивается под влиянием определенных условий внешней среды. Именно такие признаки представляют наибольший интерес для медицинского прогностического анализа, поскольку это состояния, которые можно корректировать с помощью определенного образа жизни.
Собственно алгоритм выглядит так:
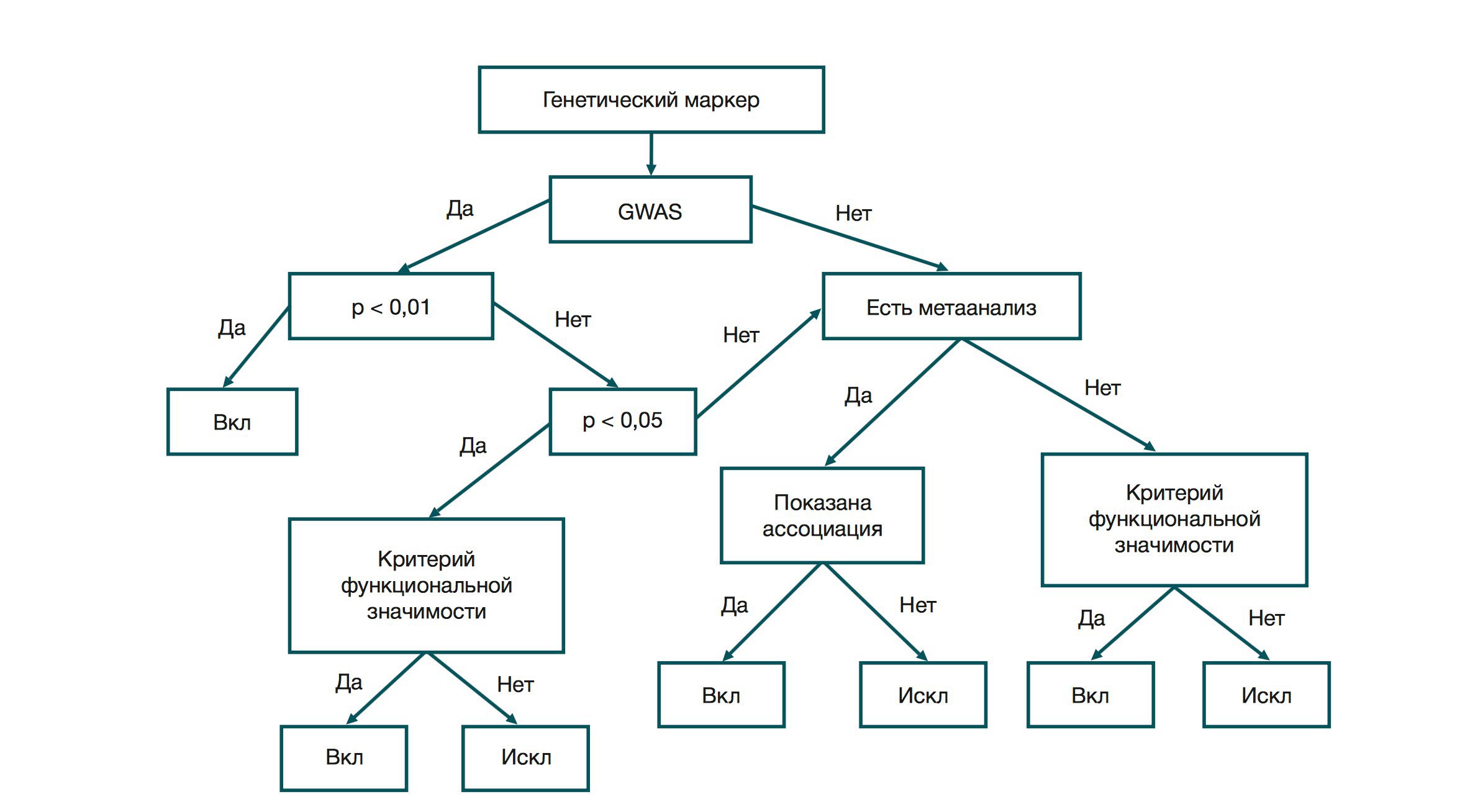
Первый этап — проверка на наличие полногеномного поиска ассоциаций (GWAS — genome wide association study). Это направление генетических исследований стали активно использовать с развитием технологии микрочипирования. Цель исследования — найти отличия между геномами людей с определенным признаком и без него. Для GWAS-исследований характерны большие выборки. Например, в GIANT (Genome Investigation of Antropometric Traits — геномное исследование антропометрических признаков) приняли участие около 300 000 человек. Исследование подтвердило серьезное влияние генетического фактора на развитие ожирения. Вероятность наблюдения ассоциации «генотип — признак» у больных и здоровых испытуемых, при условии, гипотеза об ассоциации неверна, составляет p-value эксперимента. Если это значение GWAS-исследования меньше 0,01 (с поправкой на множественность), полиморфизм попадает в шорт-лист маркеров заболевания. Если оно входит в интервал 0,01—0,05, требуется соответствие одному из критериев функциональной значимости.
Критерий один: известен прямой или опосредованный механизм влияния полиморфизма на признак. Если известен метаболический путь того или иного вещества (то есть цепочка превращений вещества A в вещество X), то знание того, какие ферменты задействованы в этой цепочке, может указывать на релевантность этого полиморфизма. Например, нам известен фермент, который активирует фолиевую кислоту, чтобы та катализировала превращение гомоцистеина в метионин. Метионин — незаменимая аминокислота, а при накоплении гомоцистеина может повреждаться эндотелий кровеносных сосудов. То есть мы можем говорить о замене в локусе, кодирующем активный центр фермента, как о причине снижения метаболизма гомоцистеина. При этом наличие единственного полиморфизма такого рода не гарантирует развития заболевания.
Если по результатам GWAS значение p-value ассоциации больше 0,05, требуется привлечение данных метаанализа. Метаанализ — это исследование, в котором выявление ассоциации проводилось путем обобщения результатов множества исследований. Если в метаанализе показана ассоциация «генотип — фенотип», полиморфизм берут в работу. Если данных по метаанализу нет, полиморфизм снова проходит проверку по критерию функциональной значимости.
Поскольку основную часть работы составляет изучение публикаций, существуют жесткие критерии отбора научных статей для нахождения ассоциаций. Для исследований GWAS этих критериев 3:
- объем выборки — не менее 750 пациентов в первичном исследовании;
- P-value < 0,01;
- ассоциации должны быть подтверждены хотя бы в одном исследовании (не обязательно для редких заболеваний), причем импакт-фактор издания должен быть не менее 2.
Для публикаций, направленных на выявление соответствия критерию функциональной значимости, критерии таковы:
- данные должны быть получены при исследовании тканей (прижизненная биопсия, материал аутопсии, послеоперационный материал) или биологических жидкостей участников;
- ассоциации должны быть экспериментально получены в рассматриваемой научной публикации;
- P-value < 0,05;
- размеры выборок участников должны быть достаточно велики для возможности обнаружения ассоциации генетических маркеров с определенными частотами встречаемости;
- если есть несколько публикаций, в которых исследовали ассоциацию данного генетического маркера с риском развития заболевания, то для анализа выбирают: a) более позднюю (например, из двух статей 2009 и 2015 гг. — статью за 2015 г.); б) публикацию, в которой исследование проводилось на большем количестве образцов.
Результаты метаанализа, если он есть, находятся в приоритете. Требования к метаанализу также очень высокие: в самой публикации должны быть тщательно отобраны источники, среди которых есть как подтверждающие, так и опровергающие ассоциацию полиморфизма с признаком. Должны быть указаны источники информации и ключевые слова, по которым проводился поиск, а также требуется обоснование критериев включения и исключения публикаций (объем выборок, статьи только на английском языке, демографические характеристики участников и прочее). Отдельное внимание уделяется так называемому анализу предвзятости отдельных публикаций методом воронкообразного графика или анализа чувствительности. При включении маркера в анализ мы акцентируем внимание на том, какие популяции принимали участие в исследовании.
Несмотря на то, что сама технология уже давно существует на рынке, это не какая-то «рутинная практика», по которой написаны тонны мануалов. Конвейер ДНК-тестов работает, и это один из его участков. Постепенно будем знакомить вас с каждым его фрагментом.
Источник

