Предисловие
Относительно недавно попалось мне на глаза хоть и студенческое, но все-таки, на мой взгляд, интересное видео из «Курилки Гутенберга» под названием «Психоакустика: звуковые иллюзии». Видео вдохновило меня порыться уже в своих студенческих конспектах и материалах…
Признаюсь честно, я не очень любил предмет Audio Coding, будучи студентом TU Ilmenau на программе Communication and Signal Processing — стресс и юношеский максимализм делали свое темное дело. Однако, со стороны чаще я слышал противоположную точку зрения: «Классный предмет, че ты жалуешься? Один из ваших лекторов — сам Карлхайнц Брандербург — лови момент!»

Один из главных разработчиков формата MP3, если вы не узнали, позирует в наушниках. (источник изображения)
По прошествии времени я, конечно, пересмотрел свой взгляд на данный предмет. Знание на стыке цифровой обработки сигналов, биологии, физики и вычислительной техники — это же круто! Одна тема уже упомянутой психоакустики чего только стоит.
И вот однажды мне пришла в голову очередная авантюрная мысль, и я сказал себе: «Почему бы не написать научно-популярную статью про аудиокодинг? Так сказать, «для самых маленьких» — для таких же студентов, коим был и я»?
Сказано — сделано.
Структура статьи
Перечислим темы, о которых будем говорить.
- Введение
Кратко об основных идеях перцептивных и lossless кодеков. - Перцептивные кодеки
(это MP3, AAC и им подобные)
2.1. Анатомия и ЦОС
Поговорим о составляющих слуховой системы, а также обсудим, как к ней относится цифровая обработка сигналов.
2.2. Порог в тишине
Рассмотрим математические модели восприятия человеком разных частот.
2.3. Маскинг (на пальцах)
Затронем основную идею, лежащую в основе перцептивных стандартов (без формул, но с картинками). - Lossless (кратко)
Для сравнения поговорим и о данной группе стандартов (очень немного поговорим).
Что ж, для матерых знатоков темы вряд ли найдется что-то новое, вещи довольно базовые, однако я буду рад дополнениям и корректировкам в комментариях! Всем заглянувшим заранее спасибо!
Введение
Я думаю, ни для кого из интересовавшихся темой аудиостандартов не секрет, что существуют в Мире две большие (и непримиримые между собой) парадигмы развития этих самых стандартов. А именно:
-
Lossless форматы (например, популярный FLAC);
-
Форматы на базе перцептивного (от англ. «perceptual» — относящийся к восприятию) кодирования (например, легендарный MP3 (MPEG-1/2/2.5 Layer 3) и его логическое продолжение AAC).
За первыми закрепилось звание тяжеловесных стандартов для меломанов. За вторыми стоит многолетняя практика применения: начиная от некачественных подборок музыки на дисках для MP3-плееров, кончая современными (достаточно качественными) потоковыми сервисами прослушивания музыки.
- В чем состоит их принципиальное отличие?
Если в двух словах, то первые стараются максимально точно воспроизвести исходный аудио-файл, убирая лишь избыточность (см. redundancy), а вторые на основе целой теории о том, как человек воспринимает звук, стараются максимально сжать исходный аудио-файл при минимально возможных потерях качества.
А теперь предлагаю поговорить об обеих концепциях чуть подробнее.
Перцептивные кодеки
Начнем со второй группы кодеков, а именно с их обобщенной схемы:
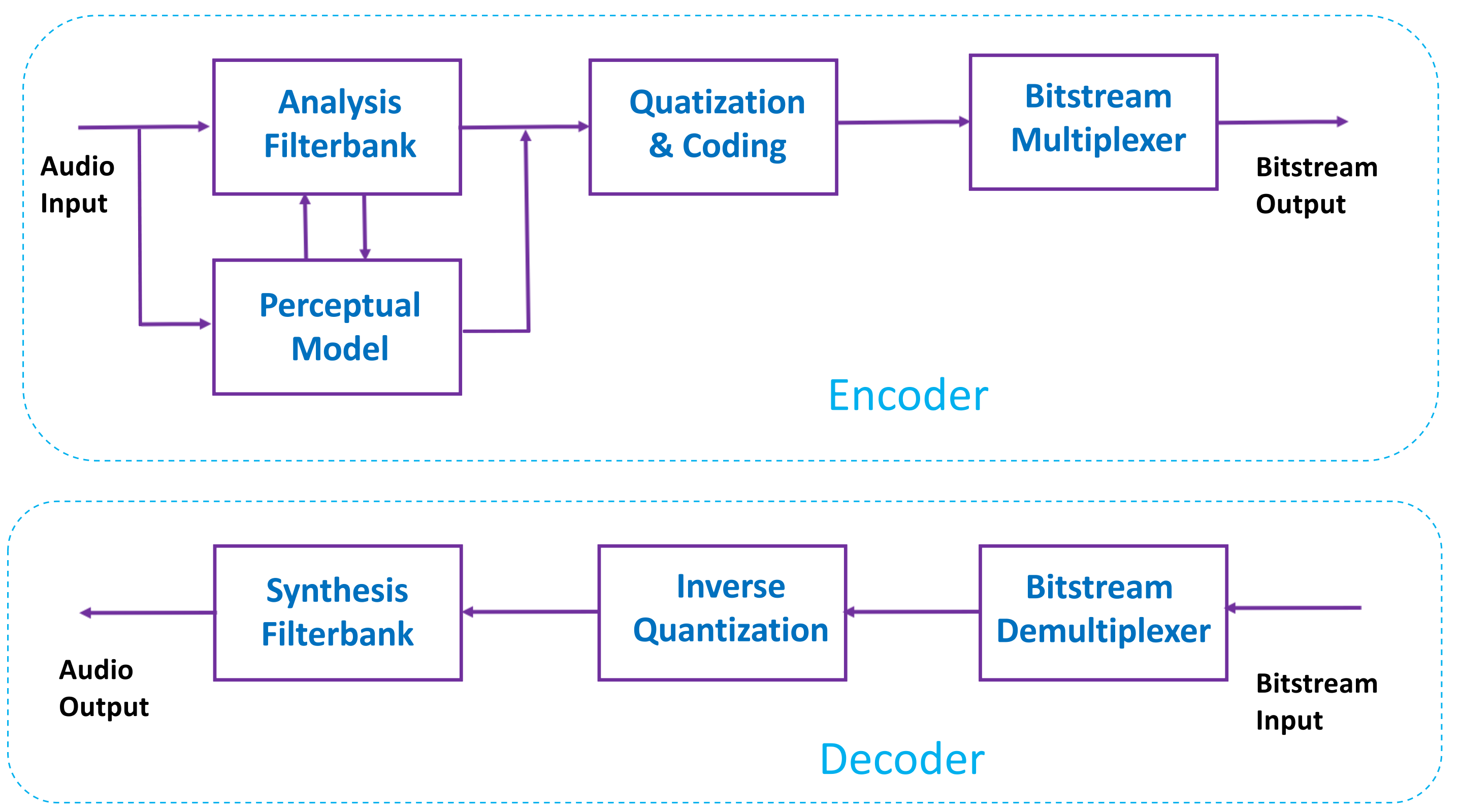
Рис. 1. Обобщенная структурная схема перцептивного кодирования.
Итак, что мы видим:
- банк фильтров (filter bank);
Штука слегка специфичная, однако, людям работающим в сфере цифровой обработки сигналов, я думаю, знакомая. Нужен этот блок для того, чтобы разбить входной сигнал на диапазоны и через это иметь больше степеней свободы для компрессии.
Если кто-то интересуется тематикой могу предложить следующие ресурсы:
- Слайды профессоров Геральда Шулера и Карлхайнца Бранденбурга:
— Filter Banks I,
— Filter Banks II.
— PQMF Filter Bank, MPEG-1 / MPEG-2 BC Audio - Filter Banks and Audio Coding (книга 2018 года от тех же профессоров).
- квантование (quantization) и эффективное кодирование (entropy coding).
Это классика. Проходят данные темы обыкновенно в купе с азами теории информации, и потому по данной тематике есть целая база знаний из всевозможных семинаров на различных языках программирования (поэтому сегодня обсуждать подробно мы их не будем).
- модель восприятия звука человеком (perceptual model — отсюда и название);
И вот по данному пункту хотелось бы поговорить более подробно. Ведь именно он и является основной точкой расхождения двух названных выше парадигм.
Следующий материал будет основываться преимущественно на двух лекциях профессора Геральда Шулера (TU Ilmenau):
- Physiological Effects (сокращенная версия с оф. сайта университета, более полная версия, оставшаяся у меня со студенчества)
- Psychoacoustics Models (с оф. сайта — здесь, вроде, ничего не убирали)
И начнем мы, так сказать, с самых основ — с биологии.
Анатомия — это ужас как интересно
Прежде чем говорить о том, как именно человек воспринимает звук, и какие математические модели под это можно подвести, поговорим о главном: что вообще позволяет человеку воспринимать звук?
Конечно же, слуховая система (auditory system)! А если быть точным, то преимущественно внутреннее и среднее ухо и их конкретные составляющие:
- барабанная перепонка (eardrum): в виде вибраций передает колебания воздуха (звуковые волны) слуховым косточкам;
- слуховые косточки среднего уха (ossicular bones): молоточек, наковальня, стремя — передают механические колебания улитке;
- улитка (cochlear structure): индуцирует бегущие волны по длине базилярной мембраны;
- нервные рецепторы (neural receptors): преобразовывают колебания в химические и электрические сигналы (имеют соединения по всей длине базилярной мембраны).

Рис. 2. Внутреннее строение человеческого уха.
Всё, вроде бы, интуитивно понятно, при условии некоторого багажа школьных знаний. Затруднение обычно вызывает только улитка: что значит эта заумная фраза: «индуцирует бегущие волны по длине базилярной мембраны»?
Как это ни парадоксально, но тут тоже всё достаточно просто. Во-первых, перечислим из чего состоит ушная улитка:
- внутри улитки есть жидкости: перелимфа и эндолимфа;
- также внутри находится базилярная (базальная, основная) мембрана;
- к базилярной мембране прикреплены волосковые клетки (часть кортиева органа).
Барабанная перепонка передаёт звуковые колебания косточкам среднего уха; 
косточки среднего уха передают колебания переимфе и эндолимфе;
под действием колебаний перелимфы и эндолимфы колеблется и базилярная мембрана;
из-за движений базилярной мембраны волосковые клетки вырабатывают сигналы, которые передаются нервным клеткам.
Подробнее предлагаю прочитать здесь и здесь.
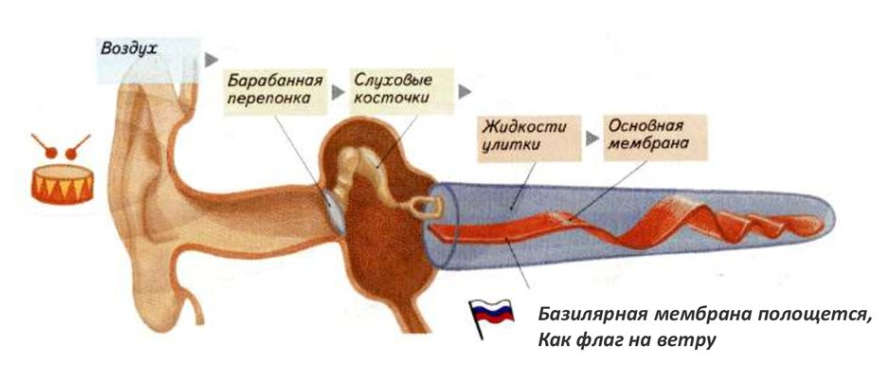
Рис. 3. Внутреннее строение человеческого уха: базилярная мембрана в «развернутом» виде (ссылка на источник иллюстрации).
Благодаря форме базилярной мембраны (сужается к основанию) и тому, что к разным участкам данной мембраны подсоединяются клетки, отвечающие за восприятие разных частот, ушная улитка — это нелинейная система с частотной избирательностью.
А что если посмотреть на ушную улитку глазами цифровой обработки сигналов?
С точки зрения ЦОС, ушная улитка — это банк полосовых фильтров. При этом фильтры сильно перекрывают друг друга.
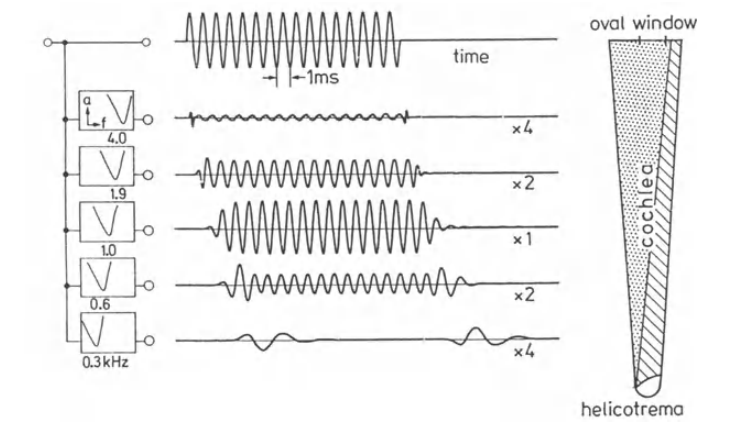
Рис. 4. Отклики тона в разных местах базилярной мембраны [1, c. 63].
Что изображено на рисунке:
- Тон длительностью 1 мс, а значит частотой 1 кГц (временная функция обозначена на верхней плашке) производит отклики в пяти разных местах на базилярной мембране (пять функций ниже, изображенных напротив определенных мест на мембране).
- Максимальный отклик соответсвует середине мембраны — там, где она откликается на частоты в 1 кГц (логично).
- Минимальные отклики — по краям мембраны (x4, x2, x1 обозначают, насколько увеличили графики для иллюстрации).
Добрые люди нарисовали уже и полезные структурные схемы:
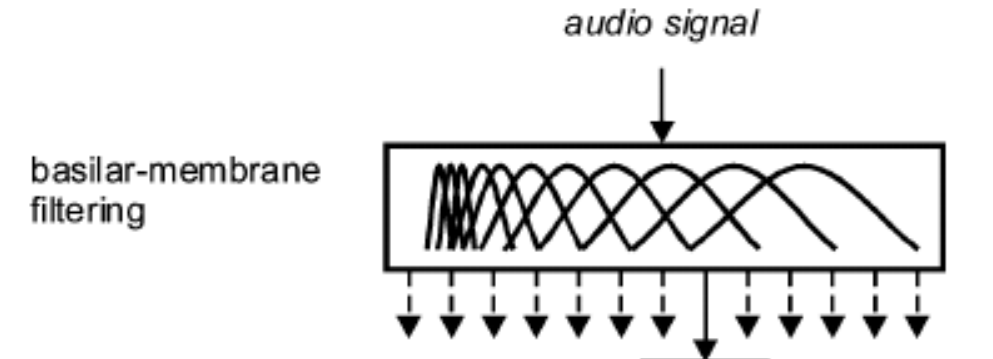
Рис. 5. Часть схемы модели восприятия (см. PEMO Model), касающаяся базилярной мембраны.
Перекрывающиеся фильтры показаны, на мой взгляд, очень наглядно.
В какой-то момент знание об ушной улитке, как о банке фильтров, решили как-то уложить в простую и доступную модель. В ходе ряда аудиторных экспериментов [1, c.82-85] ученые определили, что:
-
у частотных групп, на которые базилярной мембраной разбивается аудио-сигнал, фиксированная ширина полосы;
-
ширина полосы частотной группы зависит от средней частоты группы нелинейно.
Более того, для удобства, договорились считать, что фильтры нашей слуховой системы прямоугольные.
Всё вышеперечисленное в конечном итоге было обобщено в понятие шкалы Барков — шкалы критических диапазонов частот (см. RWTHxCA101 — Critical bands), ширина которых нелинейно зависит от средней частоты:
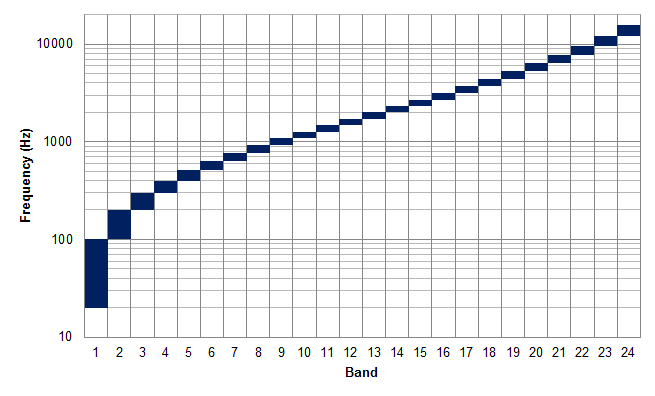
Рис. 6. Шкала Барков (источник).
Давайте, запомним этот факт, он нам еще пригодится.
Пока искал иллюстрации по шкале Барков наткнулся на это изображение:
Bark!
Хорошо, теперь мы чуть лучше представляем, что за система позволяет нам слышать. Более того мы выяснили, что органы слуха — это нелинейная частотно-избирательная система. Мы даже выяснили как устроена ее избирательность с точки зрения ширины критических диапазонов.
Но мы пока не говорили, одинаково ли мы слышим те или иные частоты. Быть может, есть какие-то подходящие эксперименты?
Порог в тишине
Конечно же, такие эксперименты есть. Более того, проведены такие эксперименты уже давно. Например, Эберхард Цвикер описывает один из них следующим образом [1, c. 63]:
Перед испытуемым, регистрирующим порог слышимости, ставится задача изменять при помощи переключателя уровень звукового давления так, чтобы с уверенностью отмечались моменты едва заметного появления и исчезновения звука. При этом перо самописца вычеркивает на бумаге зигзагообразную полосу, состоящую из вертикальных штрихов, в пределах которой окажутся те значения давления, для которых нет уверенности, был ли слышен звук или нет.
В конечном итоге, собрали 100 таких замеров от людей обоих полов в возрасте 20-25 лет и посчитали усредненные значения.

Рис. 7. Усредненные кривые порога слышимости для молодых испытуемых со здоровым слухом. [1, c. 64]
А потом медиана (кривая между 10% и 90% на рис. 7) была названа порогом слышимости (или «порогом в тишине«) и вошла в стандарты (в том числе и наш ГОСТ).
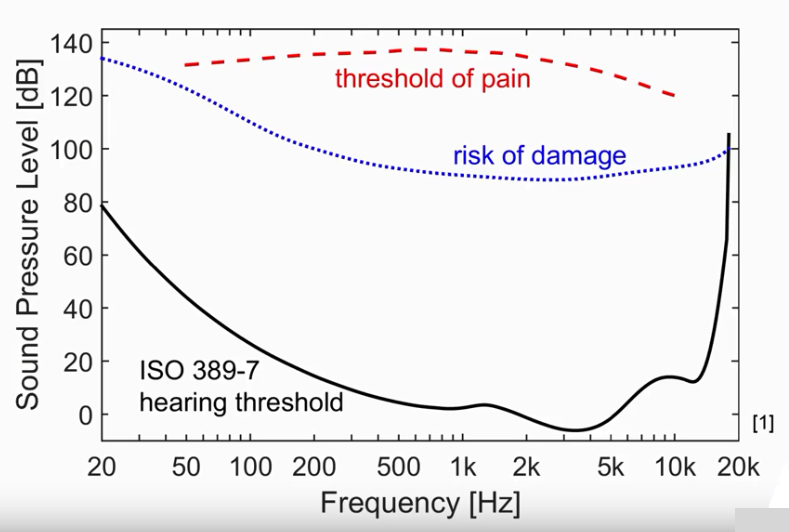
Рис. 8. Порог слышимости в тишине (threshold in quiet, hearing threshold), уровень риска повреждения органов слуха (risk of damage), уровень болевых ощущений (threshold of pain) (источник). Да, боль не предупреждает об опасности, а просто констатирует факт негативного влияния на слух.
Под это есть даже специальная формула:

где  — это, как нетрудно догадаться, частота в килогерцах.
— это, как нетрудно догадаться, частота в килогерцах.
Проговорим суть порога слышимости ещё раз: чтобы какой-либо звук мог быть услышан, он должен превысить значение «порога в тишине». То есть эволюция все расставила так, что мы почти гарантированно услышим звуки вблизи 2-4 кГц, однако, почти так же гарантированно не услышим слишком низкие и слишком высокие частоты.
Порог в тишине в том виде, в котором он представлен на рисунке 5, актуален как правило для усредненной группы именно молодых людей. С возрастом восприятие высоких частот меняется:
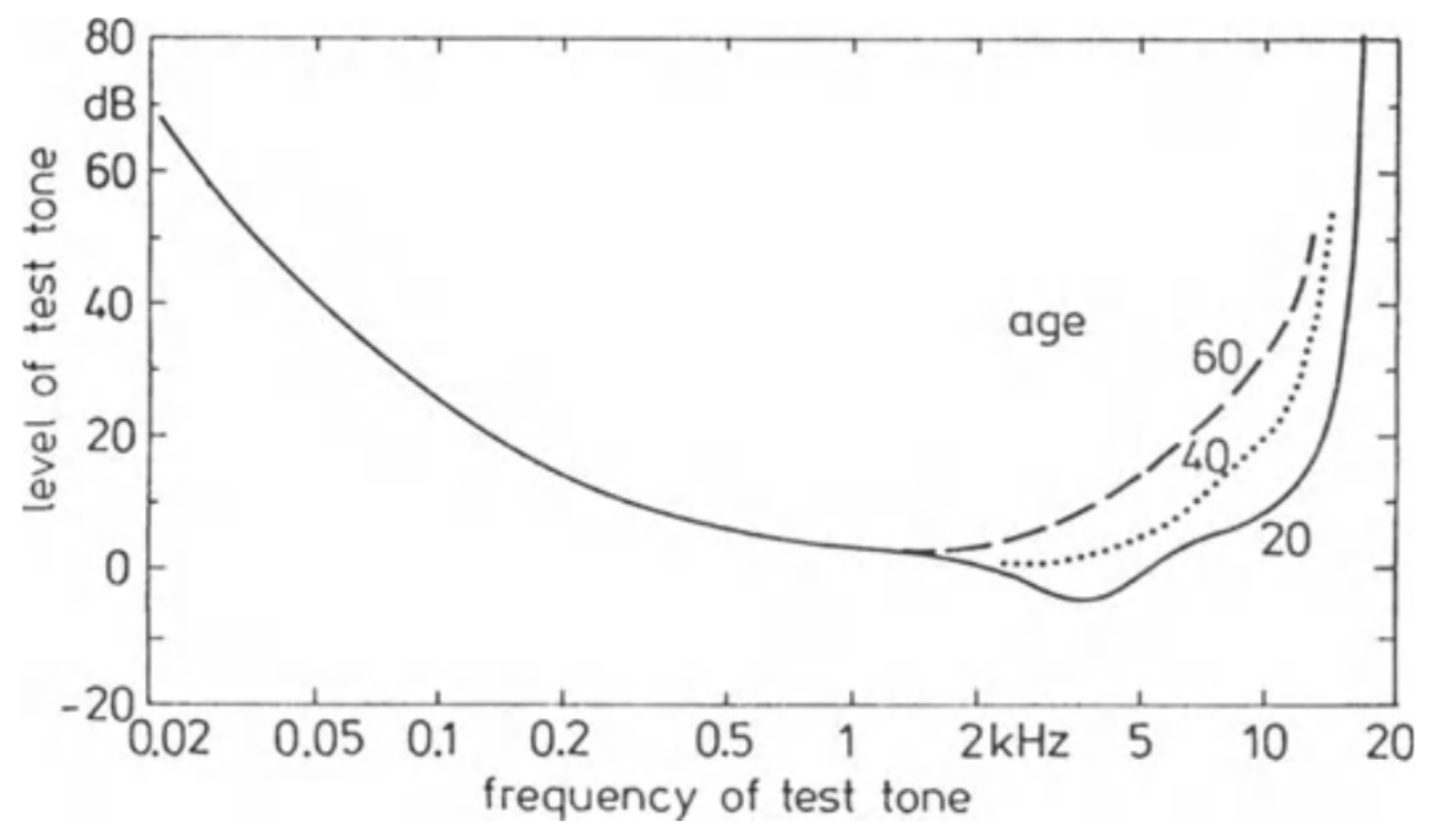
В свое время этот факт, насколько я знаю, стал основой для тиражирования среди подростков ультразвукового сигнала вызова телефона: предполагалось, что взрослые (например, учителя) его слышать не будут, и поэтому не станут раздражаться на посторонние шумы. Ну, в годы моей молодости ничего, кроме «пыток» одноклассников раздражающим и назойливым звуком посреди урока со стороны кучки «пассионариев», эта идея не принесла…
Почему к данной кривой применяется словосочетание «в тишине»?
Потому что предполагается, что так люди воспринимают звук в отсутствии посторонних шумов. При появлении шума порог будет, как бы, «приподниматься». В случае широкополосного шума картина станет такой:
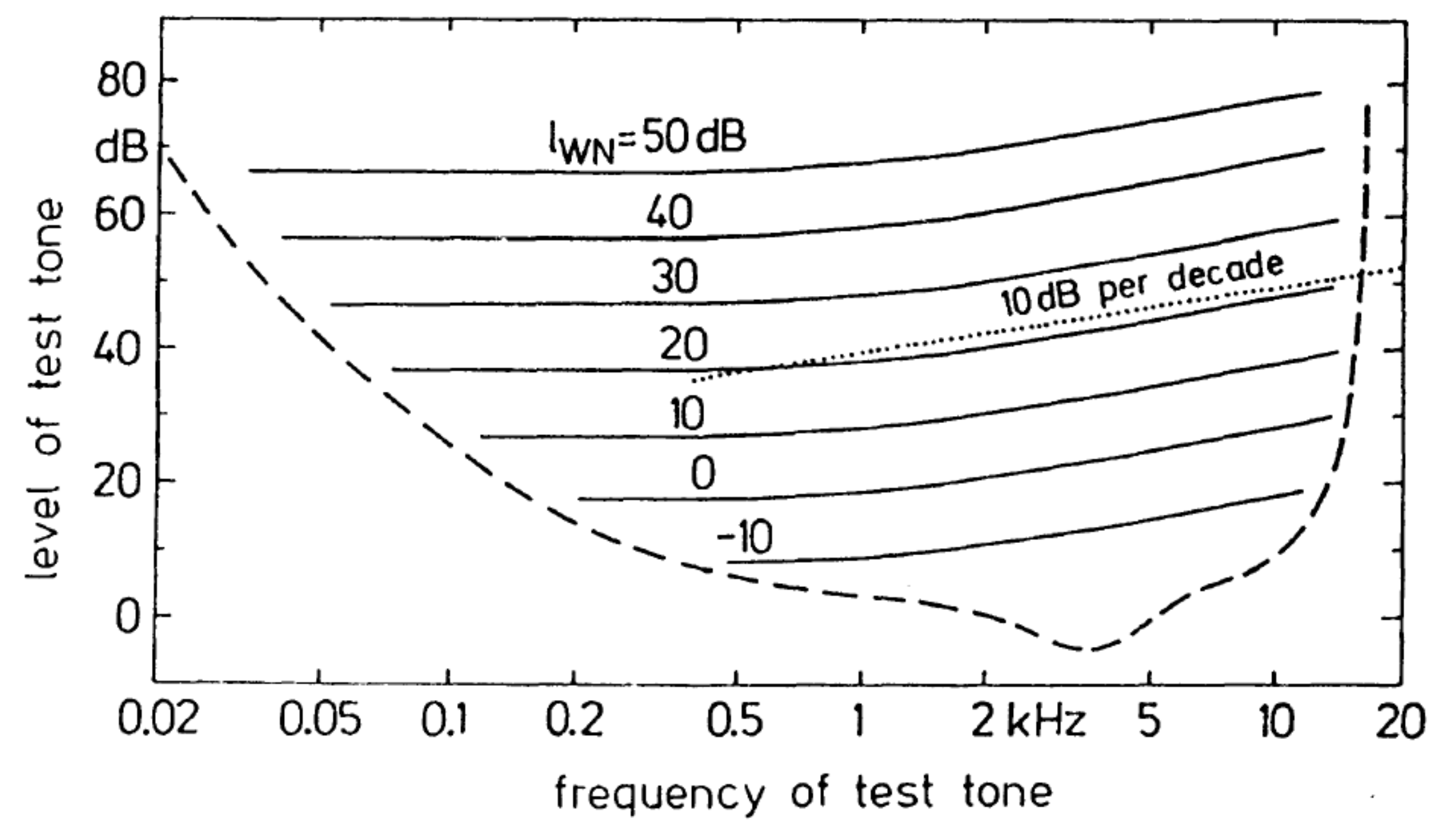
Рис. 8. Уровни порогов маскирования (термин обсудим ниже) белым шумом в зависимости от частоты тестового тона. Пунктиром отмечен уклон (slope) кривых на высоких частотах. [2, c. 62]
А в случае узкополосных шумов?
Маскинг (на пальцах)
В случае узкополосных шумов порог слышимости будет выглядеть так:
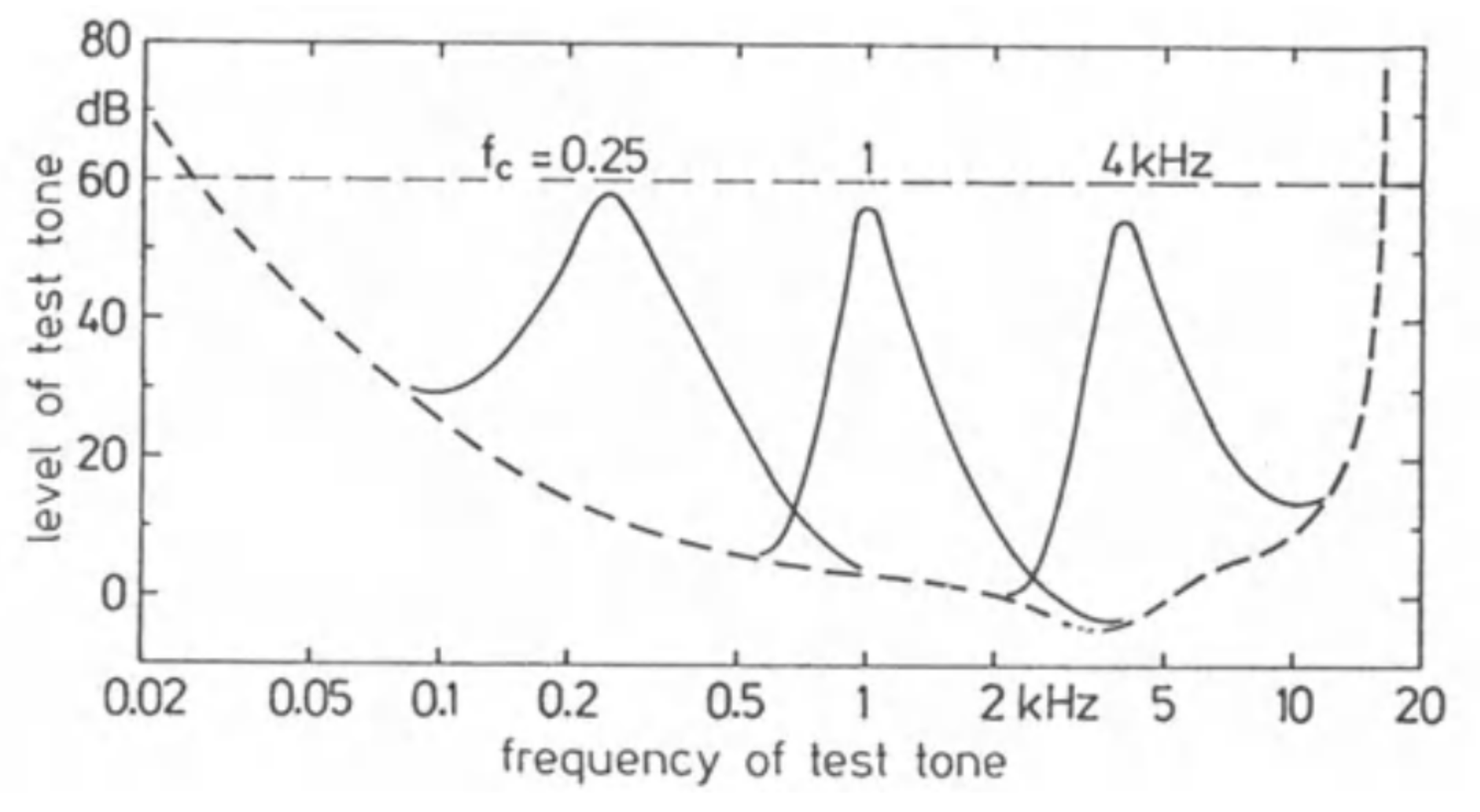
Рис. 9. Уровни, показывающие начало слышимости тестового тона, замаскированного тонами шириной критических диапазонов с центральными частотами 250 Гц, 1 кГц и 4 кГц и уровнем 60 дБ. [2, c. 64]
Быть может, моя следующая аналогия будет не совсем точной, но я вот смотрю на эту иллюстрацию и вижу, будто покрывало (порог слышимости) приподнимают снизу чем-то, вроде палки (тон) — и появляются скаты во все стороны (влияние на соседние частоты). И все, что под покрывалом, скрыто от наблюдателей. Замаскировано…
Этот феномен называют эффектом частотного маскирования (frequency masking). То есть шумы маскируют собой более слабые сигналы в частотной области.
Иными словами достаточно сильный тон влияет еще и на своих соседей. Выглядит это примерно так:
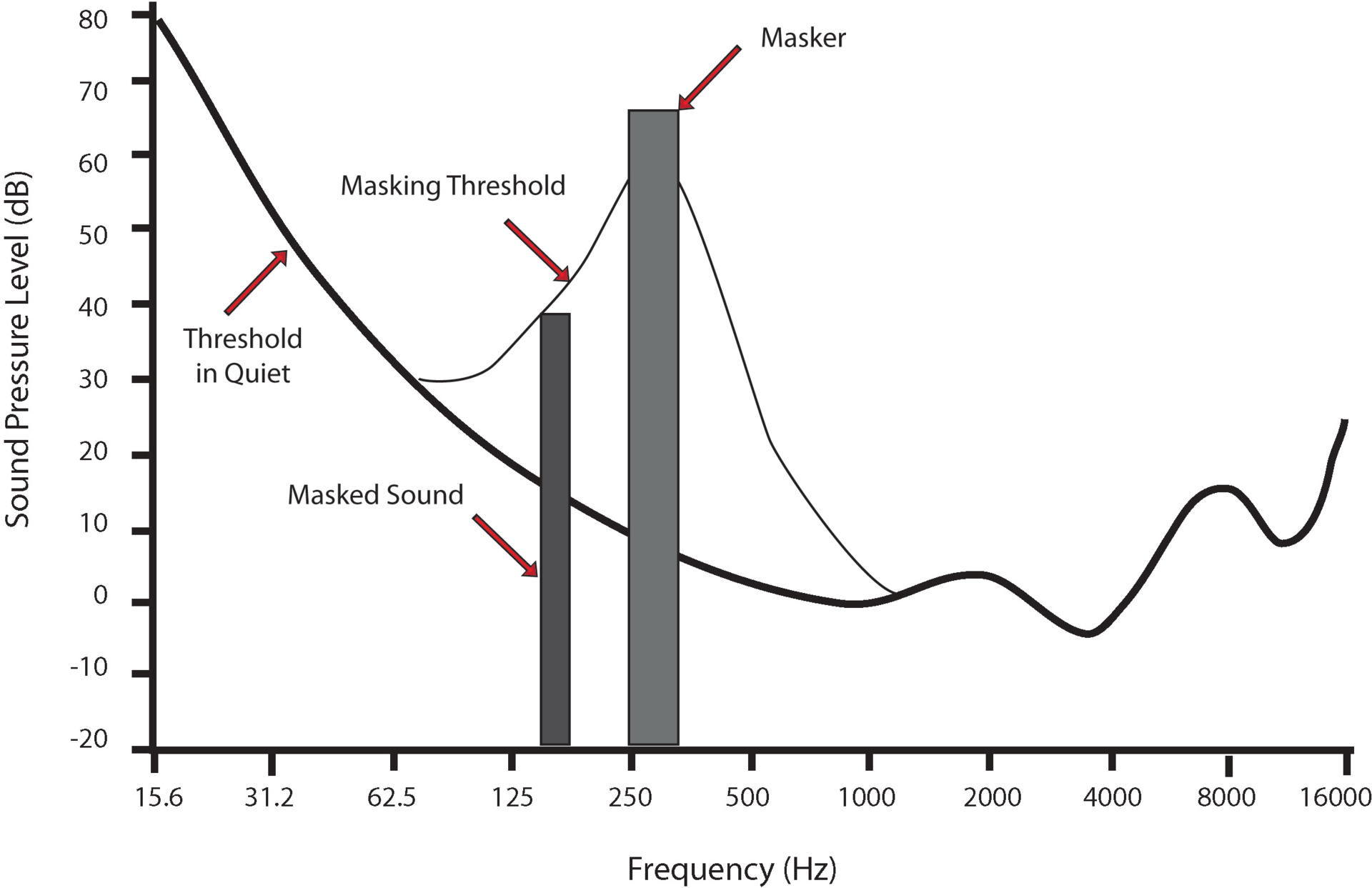
Рис. 10. Пример маскирования одного тона другим тоном более высокой частоты (источник).
То есть, иначе говоря, более сильный тон замаскировал своего более слабого соседа, и поэтому сосед перестал быть заметным для слуховой системы. Функция, которая определяет порог маскирования, называется функцией распространения (spreading function) и вычисляется на основе эмпирически полученных коэффициентов и шкалы Барков (формулы можно найти, например, в Википедии — см. Одновременная маскировка (Психоаккустика)).
Существует, к слову, и временное маскирование (маскирование во временной области): громкий сигнал маскирует собой как следующий за ним более слабый, так и предшествующий ему более слабый сигналы. Согласен, вторая часть утверждения звучит немного странно, но нужно все же держать в голове, что органы слуха и восприятия — это система со своей инерцией и задержками.
Возникает вопрос: зачем вообще тратить память на запись того, что в принципе не будет услышано?
Именно эта идея и стала базовой для перцептивных стандартов: удаляется не только избыточность на уровне эффективного кодирования, но и избыточность с точки зрения модели восприятия (irrelevance). Проводится такая «очистка» нерелевантных звуков на этапе квантования.
Подробно о процедуре квантования на основе психоаккустической модели можно прочитать здесь: Audio Coding Quantization and CodingMethods by Prof. Dr.-Ing. Karlheinz Brandenburg.
Суть состоит в том, что внутри каждого диапазона, полученного со входа банка фильтров, динамически вычисляется порог маскирования, и на его основе каждый отсчет квантуется и кодируется с таким шагом квантования, чтобы шум квантования оставался ниже некоторого допустимого порога.
А что же у lossless?
Если кратко, то данные форматы придерживаются двух основных принципов:
- декодированный и оригинальный сигналы идентичны вплоть до бита (или целого числа);
- убирается лишь только та избыточность, которая redundancy.
Структурная схема кодера выглядит так [3]:
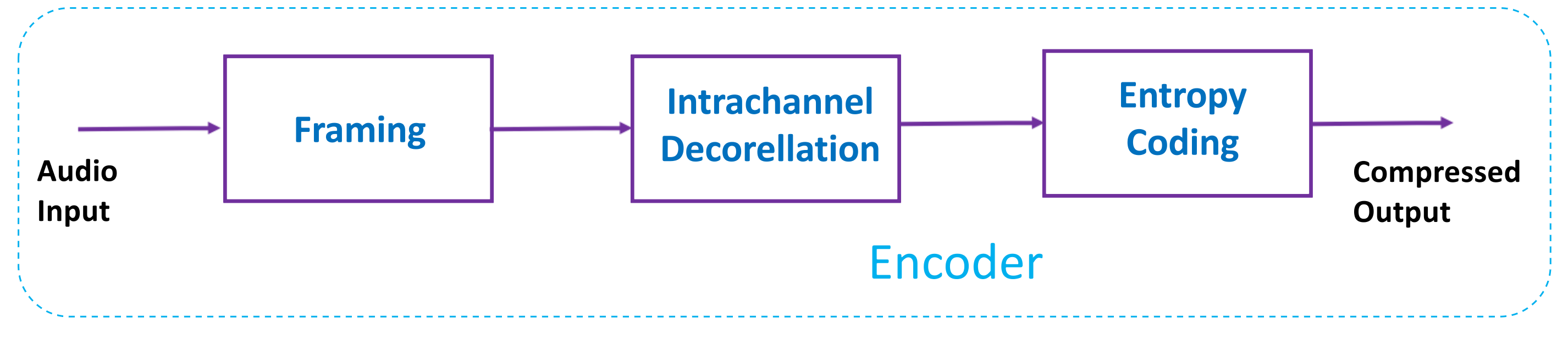
Рис. 11. Lossless-кодер.
Сначала аудио-сигнал разбивается на фреймы (кадры) в целях достижения изменяемости: работа осуществляется не со всем тяжеловесным исходником, а только с его частью — с фреймом (не слишком большим, но и не слишком малым).
Далее идет первый этап избавления от избыточности — декорреляция отсчетов (сэмплов) внутри фреймов. Звучит немного заумно, но на практике ничего сложного. Проследим на примере самой, пожалуй, распространенной реализации — на примере кодирование с предсказанием (на основе линейных фильтров):
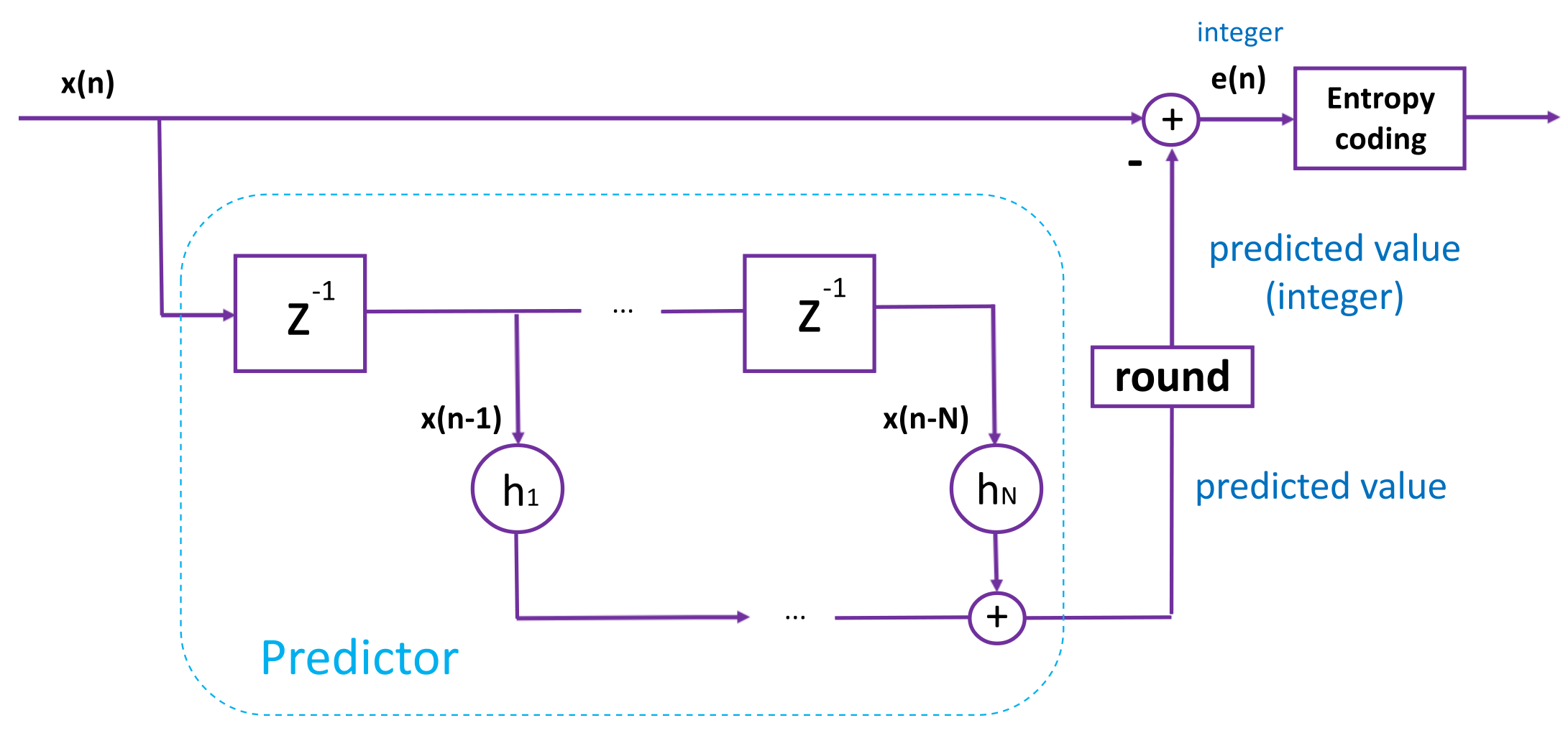
Рис. 12. Схема кодера с предсказанием.
Предиктор (предсказатель) высчитывает некоторое значение, предполагаемое на основе предыдущих отсчетов; исходя из него вычисляется ошибка предсказания e(n), и именно она сжимается дальше эффективными кодеками. За счет этого происходит некоторая экономия памяти без потери качества.
Здесь важно, чтобы кодер и декодер были абсолютно идентичными, вплоть до выбора метода округления (обычно выбирается стандарт из IEEE).
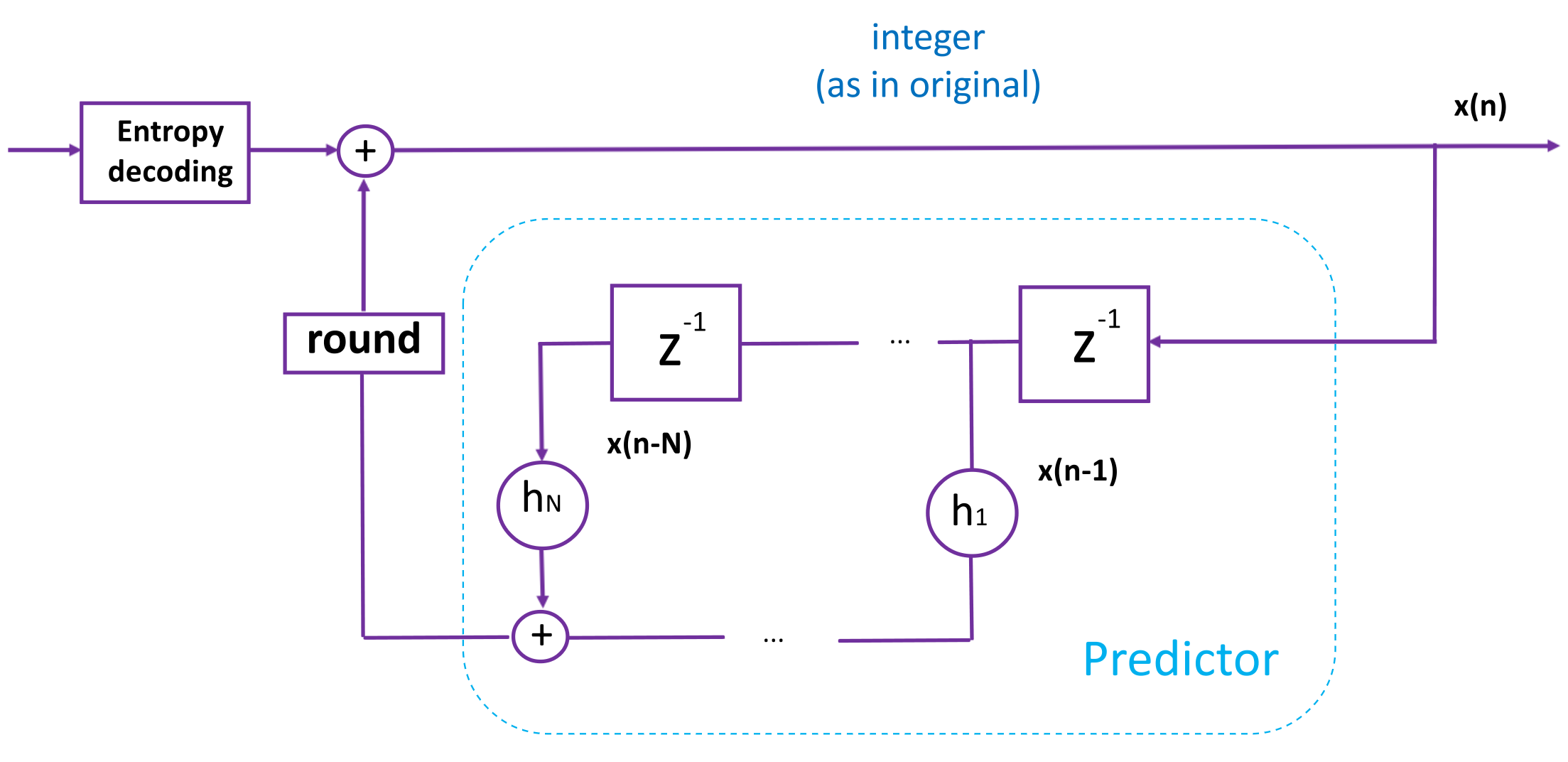
Рис. 13. Схема декодера с предсказанием.
Более подробно о предиктивном кодировании, а также о гибриде lossless с перцептивными подходами можно прочесть здесь: Prediction and Lossless Audio Coding Prof. Dr.-Ing. Karlheinz Brandenburg.
Вот такая лаконичная idea behind, в общем-то.
Мысли вслух (вместо послесловия)
Смотря на объемы теории с той и другой стороны, иногда я ловлю себя на мысли, что перцептивные стандарты разрабатывали хорошие ученые, а стандарты lossless — хорошие инженеры. С одной стороны сложная и интересная теория с экспериментальным обоснованием (и рядом допущений), а с другой простой и понятный подход: что было изначально, то и восстанови, а конечный объем — дело второго порядка. У обоих подходов есть плюсы и минусы, определяющие их области применения, а также, что закономерно, свои поклонники и противники.
Надеюсь смог хоть немного приоткрыть завесу идей, лежащих в основе. Рад буду вашим замечаниям и комментариям!
Слушайте хорошую музыку хорошего качества удобным для вас способом!
Литература
-
Цвикер Э., Фельдкеллер Р. Ухо как приемник информации //М.: Связь. – 1971.
-
Zwicker E., Fastl H. Psychoacoustics: Facts and models. – Springer Science & Business Media, 2013. – Т. 22.
-
M. Hans and R. W. Schafer, «Lossless compression of digital audio,» in IEEE Signal Processing Magazine, vol. 18, no. 4, pp. 21-32, July 2001.


