
Abstract
The transformative impact of artificial intelligence (AI) technologies on materials science has revolutionized the study of materials problems. By leveraging well-characterized datasets derived from the scientific literature, AI-powered tools such as Natural Language Processing (NLP) have opened new avenues to accelerate materials research. The advances in NLP techniques and the development of large language models (LLMs) facilitate the efficient extraction and utilization of information. This review explores the application of NLP tools in materials science, focusing on automatic data extraction, materials discovery, and autonomous research. We also discuss the challenges and opportunities associated with utilizing LLMs and outline the prospects and advancements that will propel the field forward.
Similar content being viewed by others
Introduction
Artificial Intelligence (AI) and Machine learning (ML) have been transforming materials science1,2,3,4,5,6,7,8,9,10. A number of examples have demonstrated the value of the data-driven materials approach in materials structural design6, composition and process optimization11,12,13,14,15,16,17, autonomous experiments4, and intelligent computation18 to uncover new relationships and insights. Large-scale and well-characterized data provide a foundation for this paradigm to determine the accuracy and reliability of materials inference. The overwhelming majority of materials knowledge is published as scientific literature, which has undergone peer-review with credible data3,19. The prevalent manner in which research has largely been conducted in the scientific and technological fields is by manually collecting and organizing data from the published literature and/or laboratory scale experiments. The development of data bases of materials has also provided additional sources of accessible data20,21,22,23,24. This process is undoubtedly very time-consuming and severely limits the efficiency of large-scale data accumulation. Automated materials information extraction has increasingly become a necessity.
The development of natural language processing (NLP) has provided an opportunity for the automatic construction of large-scale materials data sets and has given data-driven materials research a complementary focus in utilizing NLP tools. NLP was born in the 1950s25, and after 60 years of gestation and development, it entered the field of materials chemistry for the first time in 201126. It continues to have an impact in materials informatics19. The most common task employed is to use NLP to solve the automatic extraction of materials information reported in the literature, including compounds and their properties27,28,29, synthesis processes and parameters30,31,32,33,34, alloy compositions and properties35,36, and process routes37. By developing algorithms, such as named entity recognition and relationship extraction in specific fields, a series of materials literature data extraction pipelines have been formed.
The importance of word embeddings in NLP cannot be overstated. These distributed representations of words is what makes it possible for language models to easily read a sentence and the concepts and context underlying written words, like humans38,39. Beyond information extraction, materials science knowledge present in the published literature can be efficiently encoded as information-dense word embeddings. These dense, low-dimensional vector representations have been successfully used for materials similarity calculations that can assist in new materials discovery3,40. Recently, the emergence of pre-trained models has brought a new era in NLP research and development. Large language models (LLMs), such as Generative Pre-trained Transformer (GPT)41, Falcon42, and Bidirectional Encoder Representations from Transformers (BERT)43, have demonstrated their general “intelligence” capabilities via large-scale data, deep neural networks, self and semi-supervised learning, and powerful hardware41,42,43,44,45,46,47,48. The Transformer architecture, characterized by the attention mechanism49, is the fundamental building block to impact LLMs50,51,52, and this has been employed to solve many problems in information extraction, code generation53,54,55,56 as well as in the automation of chemical research4,6.
Recently, GPTs have emerged in materials science, offering a novel approach to materials information extraction through prompt engineering, distinct from the conventional NLP pipeline. Prompt engineering involves skillfully crafting prompts to direct the text generation of these models. These prompts, serving as input instructions or queries to the AI, play a pivotal role in determining the quality, relevance, and inventiveness of the AI’s responses. Well-designed prompts are essential for maximizing the effectiveness of GPTs, encompassing crucial elements of clarity, structure, context, examples, constraints, and iterative refinement. Though cloud-based GPTs efficiently infer information, their training demands substantial time, often spanning weeks to months for completion. Training duration impacts the model’s learning and convergence, with longer training periods potentially yielding superior performance. The choice and number of GPUs used during training influence the model’s size and training speed. Utilizing more potent GPUs or a greater number of them can facilitate training larger models and expedite experimentation and iteration. However, as we have seen recently with DeepSeek-R157, algorithmic efficiency and optimal use of resources can have a significant impact in reducing the size of language models without sacrificing performance. The size of the training corpus also significantly influences the performance of LLMs. Larger corpora offer broader and more varied knowledge, while the corpus quality (e.g., well-curated, low noise) affects the model’s capacity to grasp meaningful representations. The domain of the corpus can also shape the model’s proficiency in specific subject areas, such as a model trained on scientific literature exceling in scientific tasks over those trained on generic web content. Apart from information extraction, exploration of GPTs for materials prediction and design is underway. Through fine-tuning strategies, materials scientists aspire to equip large models with specialized materials knowledge beyond their general capabilities, enabling them to furnish quantitative reasoning outcomes in customized component design, process optimization, property prediction, and autonomous research.
Nevertheless, there exist notable gaps between the expectations of materials scientists and the capabilities of existing models. One major limitation is the need for models to provide more accurate and reliable predictions in materials science applications. While models such as GPTs have shown promise in various domains, they often lack the specificity and domain expertise required for intricate materials science tasks. Materials scientists seek models that can offer precise predictions and insights into materials properties, behavior, and performance under different conditions. They also require models to provide explanations for their predictions, enabling scientists to understand the underlying mechanisms and make informed decisions based on the model’s output. Furthermore, there is a need for models to integrate domain-specific knowledge effectively. Materials science is a complex field with diverse sub-disciplines and specialized terminology. Models should be able to leverage this domain knowledge to enhance their predictive capabilities and provide contextually relevant information. Additionally, the development of localized solutions using LLMs, the optimal utilization of computing resources, and the availability of open-source model versions are crucial aspects to consider. These factors represent significant thresholds for the application of LLMs in materials science, promising opportunities for advancement in the field.
Here, we provide an overview of NLP concepts, approaches, and results achieved to date in materials information extraction, materials language models and their consequences. While Olivetti et al.19 have reviewed the progress of information extraction methods through NLP and text mining in this field, the rapid evolution of LLMs has allowed us to utilize the advantages of contextual sequential representations that approach human-level understanding. Pei et al.58 have recently commented on the holistic design of alloys using LLMs, emphasizing their potential to accelerate alloy development. They suggest incorporating design criteria for certain tasks or parsing the information from publications or patents, processing the relationships holistically amongst constraints, and using engineering prompts to integrate and prioritize these constraints effectively depending on the objectives. We review the developments of the last several years that have given rise to prompt-based systems59, fine-tuned materials science models60 as well as the full integration of resources that make autonomous scientific research possible5,61. The review consists of five sections. We begin with the concept of NLP, including its evolution in materials science. In Section 3, we summarize the NLP pipelines for automatic materials data extraction and study cases for materials composition, property, and synthesis routes, including traditional materials information extraction and recent developments using LLMs. In Section 4, we discuss the results and impact on materials science of Language models. We show how word embeddings, fine-tuned language models, and AI agents work for materials discovery, property prediction, and autonomous research. Finally, section 5 reviews the current state of materials NLP and LLMs and outlines future challenges and opportunities. Our objective is not only to highlight the latest advances and trends in the field but also to provide practical guidance, critical analysis, and valuable insights that can inform and inspire researchers, practitioners, and stakeholders in the materials science community.
The development of NLP
NLP has a long history dating back to the 1950s25. The objective is to make computers understand and generate text, in particular, in two principal tasks, natural language understanding (NLU) and natural language generation (NLG)62. NLU focuses on machine reading comprehension via syntactic and semantic analysis to mine the underlying semantics. NLG is the process of producing phrases, sentences and paragraphs within a given context, in contrast to NLU. Initially, the systems developed used handwritten rules based on expert knowledge, which could only solve specific, narrowly defined problems. The ML era began in the late 1980s with a growing volume of machine-readable data and computing resources63. Instead of creating rules manually, ML algorithms analyzed a large corpus of annotated texts to learn relations. However, ML requires scientists to design features for words. Languages have hundreds of thousands of words, and the number of word combinations that could have a given meaning is impossible to count. Hence, processing language data with ML inevitably faced the problem of sparse data with the curse of dimensionality. The use of deep learning (DL), which automatically performs a degree of feature engineering from training data, led to neural network architectures, namely the bidirectional long short-term memory network (BiLSTM) and Transformer that is the core of LLMs. Figure 1 shows the different development stages of NLP technology from handcrafted rules to DL, as well as the NLP tasks corresponding to the requirements of information extraction and materials discovery. We briefly describe some of the key concepts that have advanced the field:

The horizontal axis represents the different development stages of NLP from handcrafted rules to large language models, and the vertical axis represents the specific NLP tasks corresponding to information extraction, materials discovery, and autonomous design. [Reprinted according to the terms of the CC-BY-NC-ND license ref. 117, the CC-BY license ref. 5, the CC-BY license ref. 37, with permission from ref. 3. Copyright 2019 Springer Nature, from ref. 59. Copyright 2023 Journal of the American Chemical Society].
Word embeddings
To make it possible for language models to easily read a sentence and the concepts behind written words, akin to humans, it is essential that a word in a dataset be numerically represented. Ideally, such a representation needs to refer to a word’s linguistic meaning and semantic interconnections with other words. Word embeddings allow us to represent words as a vector. These are dense, low-dimensional representations that preserve contextual word similarity39. Continuous Bag-of-Words (CBOW) and Skip-Gram (SG) models are two popular shallow architectures to learn effective word embeddings to capture the latent syntactic and semantic similarities among words64. Word2vec and GloVe are popular implementations of these models, which are computed by global word-word cooccurrence statistics from a large corpus64,65. Words with similar meanings then have a similar representation. The cosine similarity between vectors often serves as a measure of the association between two vectors encoding the words. The embeddings were initially “static” and did not encode the ordering of words in a sequence. The “contextual” or dynamic embeddings resulted from advances such as the self-attention mechanism.
Attention mechanism
The attention mechanism was first introduced in 2017 as an extension to an encoder-decoder model49. An encoder-decoder model organizes two recurrent neural networks. The first network encodes a source sequence, while the second decodes the source sequence into the target sequence. With the attention mechanism, a model focuses on parts of a source sentence (a word or phrase) where the most relevant information is concentrated. Then it predicts a target word based on the context of surrounding words. In self attention49, the input static word embedding is essentially transformed into a dynamic or contextual embedding by considering the correlations of a word with the preceding and following words in a sequence.
Pretraining techniques
One of the biggest challenges in NLP is the shortage of training data as task-specific datasets often contain only a few thousand human-labeled training samples. To narrow this gap in data, pretraining techniques have been developed to train general-purpose language representation models using the enormous amount of available unannotated text66. The pretraining tasks are crucial for learning the universal representation of language, which can be divided into three categories: supervised learning (SL), unsupervised learning (UL), and self-supervised learning (SSL)66. SL attempts to learn a function that maps input features to an output property based on training data consisting of input-output pairs. In UL the objective is to extract patterns or knowledge from unlabeled data via clusters, densities, and latent representations. The learning paradigm in SSL is to predict any part of the input from other parts of the input in some form. For example, the masked language model (MLM) is a self-supervised task that attempts to predict the masked words in a sentence given the rest of the words67. The pre-trained model can then be fine-tuned on relatively small, focused datasets, which usually leads to better generalization performance and a speed-up in convergence on the target task.
Large language models
Intuitively, pretrained language models, such as ELMo68 and BERT43, focus on learning contextual word embeddings to represent the word semantics depending on the context69. Recently, LLMs have shown their ability in learning universal language representations, text understanding and generation. LLMs refer to a model with a large number of parameters, vast training data, and substantial compute, enabling it to capture complex language patterns. The GPT (Generative Pretrained Transformer) is a large-scale language model developed by OpenAI that consists of multiple layers of Transformer blocks, each with a self-attention mechanism and a forward neural network, such that each input token is propagated forward to the following token with autoregressive properties70. GPT-171 was developed in 2018, and a year later, GPT-2 introduced the idea of multi-task learning72 with more network parameters and data for training than GPT-1. To further improve the model performance on few-shot or zero-shot73 settings, GPT-3, with 100 times more parameters than GPT-2, combines meta-learning74 with in-context learning75 to improve the generalization ability of the model. When it comes to the pilot version of ChatGPT (also known as one of the derivative versions of the GPT3.5 series models), reinforcement learning with human feedback (RLHF) is used to incrementally train the GPT-3 model76. Finally, ChatGPT produces human-level performance on a variety of professional and academic benchmarks41. It is based on GPT-4, a large multimodal model with image and text as inputs and text as output.
As shown in Fig. 1, the typical application of NLP in materials science includes three aspects. The first is information extraction, including compound and composition details, synthesis routes and parameters, and properties. This sifts through the vast and continuously expanding body of unstructured scientific publications to create a database for further data-driven materials design. Second, the knowledge of materials science presented in the published literature can be efficiently encoded as information-dense word embeddings. Leveraging semantic textual similarity, new materials with similar properties can be identified without human labeling or supervision. These embeddings can also be utilized for encoding information related to property prediction. The third aspect utilizes conversational LLMs in a closed loop to automatically design, plan, and execute complex experiments to enable autonomous research on materials.
The NLP pipeline for automatic materials data extraction
Overview of NLP and how it differs from LLMs
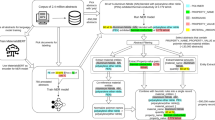
NLP encompasses a wide range of tasks, such as information retrieval (IR), named entity recognition (NER), relation extraction, text classification, topic modeling, semantic textual similarity, machine translation, question answering (QA). Building on these tasks, NLP pipelines have been developed for the automatic extraction of materials data from journal articles related to the chemical composition, properties, and synthesis procedures of organic and inorganic chemical compounds, as well as alloys. Extracting materials information from scientific literature involves two primary approaches: traditional NLP and LLM-based NLP methods. Both approaches share several common stages, including corpus acquisition, pre-processing, information extraction, and interdependency resolution. Traditional NLP encompasses specific steps for information extraction, such as text classification, table parsing, named entity recognition (NER), and entity relationship extraction. In contrast, LLM-based extraction primarily relies on prompt engineering and fine-tuning to facilitate information extraction through conversation, as illustrated in Fig. 2.

The schematic workflow of NLP pipeline for materials information extraction from the scientific literature including both traditional NLP and LLM-based NLP methods.
The first step is to acquire a relevant corpus of subject articles automatically. Many journals and publishers provide the content as hypertext markup language (HTML), plain text or extensible markup language (XML) via their developer APIs, which are much easier to interoperate than the portable document format (PDF)77. The content comprises article text and meta-data (including journal name, title, abstract and author information). After the corpus is obtained, a series of steps for text preprocessing need to be undertaken, such as corpus cleaning, tokenization, and part-of-speech (POS) tagging. Corpus cleaning aims to remove the markups in HTML and XML documents and the unrelated metadata of the programmatically downloaded articles. Tokenization segments text into the relevant sentences, phrases, words, or word pieces, to be processed individually or as a sequence29. This yields a clean and normalized corpus for information extraction.
In traditional NLP, this is followed by text classification to determine which sentence or paragraph contains the target composition, properties, and synthesis procedures to be extracted by training a binary classifier with positive samples representing related paragraphs and negative samples representing all other paragraphs, topic modeling, or by a rules-based approach. Tables are attractive targets for materials information extraction due to their high data density, and table parsing transforms complete table information, including table caption and body, into a structural format35. NER and relation extraction tasks are considered critical components of data extraction from materials articles. As presented in section 3.2, they help to identify the compounds, alloy compositions, properties, synthesis actions and parameters, and solve the semantic relationships between entities, such as the relationship between a compound and its properties for a given material object. Interdependency resolution resolves the linkage to chemical composition, processing routes, and property data fragments for one specific material.
In LLM-based NLP, pre-processing is followed by prompt engineering, which guides LLMs to produce outputs that align with extraction requirements during inference without altering the model’s parameters. This approach eliminates the need for additional training, allowing for prompt refinement to better tailor the model’s responses to the task at hand59,78,79. If prompt engineering alone doesn’t yield sufficient results, fine-tuning becomes necessary. In this case, utilizing a materials-specific corpus allows for further training of the model, enhancing its ability to address the unique requirements of materials information extraction in a particular context80.
Traditional NLP pipeline
The general methods of NER and entity relation extraction range from dictionary look-ups and rule-based, semi-supervised and machine-learning approaches28,29,35,81,82, as shown in Fig. 3. The approaches vary according to the scale of annotated corpus. More direct supervised ML-based approaches would require the development of larger annotated corpora and quantifying similarity by computing representation similarity83. Given a substantial amount of labeled corpus, training a BiLSTM network with a conditional random field (CRF) layer can be used for NER and entity relation extraction tasks. BiLSTM is a bidirectional recurrent neural network with an LSTM cell to solve the problem of long-term dependency in text data, capturing more semantic context dependence of sentences. The input to BiLSTM is a layer of the word embedding to yield a transformation function that accepts a plain text word and outputs a dense, real-valued, fixed-length vector. The outputs of BiLSTM are the corresponding probabilities under all labels of each word in a sequence, which are input into the CRF layer afterward to consider the correlations between labels in neighborhoods and jointly decode the best chain of labels for a given input sentence. For a limited annotated corpus, semi-supervised ML strategies32,37,81,84 and rules-based methods26,35,36 work better.

Three strategies for materials named entity recognition including (a) rule or dictionary-based, (b) semi-supervised, and (c) ML-based extraction.
Significant effort has been devoted to extracting material compositions and their properties by traditional NLP pipeline. This has benefited from the development of information extraction tools in the chemical field. As early as 2011, researchers began to recognize chemical entities in the chemical literature, such as OSCAR26, ChemicalTagger85, and ChemDataExtractor27,29. These are a series of chemistry text-mining tools and methods for the automated extraction of chemical entities, their associated properties and measurements. They were developed to populate structured chemical databases. In 2016, Swain et al.29 created ChemDataExtractor as a hybrid approach that combines dictionary and rule-based methods with ML methods to provide an extensible, chemistry-aware, natural language processing pipeline for tokenization, part-of-speech tagging, named entity recognition, and phrase parsing. Subsequently in 2018, Court et al.81 adapted a version of the ChemDataExtractor that included a semi-supervised, probabilistic, and quaternary relationship extraction stage based largely on the modified Snowball relationship extraction algorithm. An upgraded framework, ChemDataExtractor2.0, was issued in 2021 as an automated population of ontologies that enables data extraction for chemical and physical properties with the ability to organize hierarchical data as nested information. It has been used to extract 15,818 perovskite- and 41,680 dye-sensitized solar cells86, 100,236 semiconductor band gap records87, 39,822 chemical compounds and their Curie and Néel temperatures81, 64,269 yield strength records and 30,285 grain size records88, 49,076 refractive index and 60,804 dielectric constant data records89. Weston et al.82 trained a BiLSTM-CRF NER model to extract more than 80 million materials-science-related named entities using an 800 hand-annotated corpus to achieve an overall F-score of 87%. Shetty et al.83 trained a BERT-based single-layer neural network to recognize ~300,000 polymer property records using 750 annotated abstracts for a diverse range of applications, such as fuel cells, supercapacitors, and polymer solar cells to recover non-trivial insights.
In contrast to the vast amount of literature available on organic and inorganic materials, the corpus related to alloys, including superalloys, aluminum alloys, steel, and others, is relatively small, comprising only tens of thousands of publications. This limited corpus presents challenges in terms of the availability of adequate and effective large hand-labeled datasets for training supervised deep learning methods for tasks such as NER or relation extraction. Wang et al.35 proposed an automated NLP pipeline to capture a dataset with 2531 instances covering chemical compositions and physical properties, such as the γ′ solvus temperature, density, solidus temperature, and liquidus temperature, for superalloy. With the dataset, they built a data-driven model for γ′ solvus temperature to predict unexplored Co-based superalloys Co-36Ni-12Al2Ti-1W-4Ta-4Cr, Co-36Ni-12Al-2Ti-1W-4Ta-6Cr and Co-12Al-4.5Ta35Ni-2Ti with γ′ solvus temperatures higher than 1250 °C, within the extracted 2531 records from 14,425 articles. Also, Yan et al.84 proposed a semi-supervised Snorkel framework for materials domain via automatically generated corpus to expand labeled data to improve the property extraction precision for superalloys. Pfeiffer et al.36 used a rule-based method to extract aluminum alloy compositions and properties from a corpus of scientific manuscripts and US patents.
The discovery of materials with specific properties requires not only addressing chemical compositions and structural complexity, but one needs to take into account a multitude of processing pathways. Synthesis and processing routes are typically described in the form of continuous events, with actions linked in sequence. These actions encompass diverse types, exhibit flexible expressions, and are subject to varied conditions and parameters. Moreover, the continuous flow of synthesis and processing events is frequently intertwined with extensive discussions on experimental phenomena and intermediate products, presenting significant challenges in extracting actions and parameters.
There have been many studies related to extracting chemical synthesis procedures in inorganic materials, as shown in Fig. 4. Kim et al.90,91 used a neural-network and parse-based method to extract a dataset of synthesis parameters across 30 different oxide systems from over 640,000 journal articles. Wilary et al.92 developed a software tool, the ReactionDataExtractor for automatically extracting information from multistep reaction schemes. Huo et al.32 demonstrated a semi-supervised machine-learning method named latent Dirichlet allocation to classify inorganic materials synthesis procedures from written natural language, and accurately reconstructed a flowchart of possible synthesis procedures by Markov chain representation of the order of experimental steps. They combined the BiLSTM-CRF model, sentence dependency and rule-based methods to obtain inorganic materials synthesis recipes including targets, precursor, operations, conditions and reactions30,90,93,94, as well as synthesis procedures34,95 for gold nanoparticles and solution-based inorganic materials. They used a knowledge base of 29,900 solid-state synthesis recipes, text-mined from the scientific literature, to automatically learn precursors to recommend for the synthesis of a novel target material. The data-driven approach learns the chemical similarity of materials and refers the synthesis of a new target to precedent synthesis procedures of similar materials with a success rate of at least 82%93,94. To further utilize the extracted synthesis data, Vaucher et al.31 designed a set of synthesis actions with predefined properties and a deep-learning sequence to sequence model based on the transformer architecture to convert experimental procedures to action sequences. Kim et al.96,97 presented an unsupervised conditional variational autoencoder method for connecting scientific literature to context-aware insights for inorganic materials synthesis planning.

a A heatmap (partial) of the frequency of extracted superalloy actions reported from 2004 to 2021 [Reprinted according to the terms of the CC-BY license ref. 37]. b Machine-learned flowchart of the transition between experimental steps for different types of synthesis [Reprinted according to the terms of the CC-BY license ref. 32]. c System workflow of converting synthetic procedures described using natural language into hardware-independent chemical code, which is represented and can be visually edited as natural language but internally stored as XML[Reprinted with permission from ref. 33. Copyright 2020 The American Association for the Advancement of Science].
In alloy corpora, synthesis and processing actions are described at both token-level and chunk-level entities, depending on the length of the phrase, unlike in chemical synthesis, where primarily token-level action entities are used. Additionally, the description of actions in the alloy process routine varies depending on their position; for example, aging treatment can take different forms such as primary aging and secondary aging. This presents additional challenges in manually labeling entities accurately. Wang et al.37 introduced a semi-supervised recommendation algorithm for token-level action and a multi-level bootstrapping algorithm for chunk-level actions to extract the parameters corresponding to the sequence of actions of synthesis and processing from superalloy corpus, and in total, 9853 superalloy synthesis and processing actions with chemical compositions are automatically extracted from a corpus of 16,604 superalloy articles.
Recent developments using LLMs
Traditional NLP offers simplicity and tailored solutions but struggles with flexibility and complex tasks. Recently, GPT models have used the Transformer decoder architecture consisting of self-attention and feed-forward layers to generate text. Conversational LLMs such as GPT-4 have demonstrated their remarkable capability for efficiently extracting data from extensive collections of research papers. The application of LLMs to analyze information, extract pertinent details, and create responses, is becoming increasingly popular in several research fields in a stand-alone mode. This harnesses LLMs by use of prompt engineering and fine-tuning and their integration with other scientific tools.
Conversational LLMs can be significantly enhanced by employing prompt engineering, which meticulously designs prompts to steer LLMs toward generating precise and pertinent information. Prompt engineering is the process of designing and refining input prompts given to an LLM toward generating precise and pertinent information. Well-designed prompts in a given context can effectively minimize the hallucination of LLMs. As shown in Fig. 5a, Zheng et al.59 presented a framework using prompt engineering to guide ChatGPT to extract 26257 distinct synthesis parameters of 800 metal-organic frameworks from the scientific literature, resulting in precision, recall, and F1 scores of 90 − 99%. An ML model is then trained to predict MOF crystallization with precision, recall, and F1 scores of 90−99%. Da et al.98 leveraged LLMs to automatically extract synthesis details of reticular materials from the scientific literature. They developed detailed prompts incorporating task instructions and examples to guide LLMs in performing classification and information extraction. With a relatively small set of examples, multiple LLMs achieved impressive performance, attaining an F1 score of up to 0.98 in paragraph classification tasks and an accuracy of 0.96 in information extraction tasks. A GPT-3.5-based framework for parsing and extracting synthesis information from the scientific literature was also studied by Thway et al.99 to aid in the development of thermoelectric materials, focusing, in particular, on solid-state synthesis recipes for ternary chalcogenides. By curating a domain-expert “Gold Standard” dataset and creating a prompt set to achieve 73% extraction accuracy, they demonstrated the framework’s ability to parse synthesis data from 61 out of 168 research articles. Polak et al.100 proposed ChatExtract to automate precise data with minimal initial effort and background knowledge. By leveraging ChatGPT in a zero-shot manner with a well-engineered set of prompts, this provides a versatile, accurate, and efficient approach to extract materials properties in the form of Material, Value, and Unit triplets. It achieves 90.8% precision and 87.7% recall on bulk modulus, and 91.6% precision and 83.6% recall on critical cooling rates for metallic glasses.

a Three core principles of ChemPrompt Engineering as applied to extract and summarize synthetic conditions from specific sections of research articles to organize the information into well-structured tables [Reprinted with permission from ref. 59. Copyright 2023 Journal of the American Chemical Society]. b Document-level joint named entity recognition and relationship extraction for materials via partial training of LLMs in a “human-in-the-loop” annotation process [Reprinted according to the terms of the CC-BY license ref. 80].
Fine-tuning enables LLMs to concentrate more effectively on materials knowledge and task requirements through targeted training. This approach enhances the accuracy of materials information extraction, improves adaptability and robustness, and expands the model’s capabilities. As shown in Fig. 5b, Dagdelen et al.80 explore a sequence-to-sequence approach for extracting structured information from scientific text using large LLMs such as GPT-3 and Llama-2. The study demonstrates that LLMs fine-tuned with a few hundred annotated text-extraction pairs can effectively perform NER and relation extraction for complex, domain-specific scientific information to enable large-scale, structured knowledge extraction from the scientific literature. Xie et al.101 introduced so called “structured information inference”, as a new natural language processing task designed to transform unstructured scientific data into structured formats for materials science applications. By fine-tuning llama-7b-hf, an end-to-end framework that efficiently updates a perovskite solar cell dataset is created with an F1 score of 87.14% in schema generation and capturing multi-layered device information from the recent literature.
Materials development driven by Language models
Word embeddings for materials discovery
While NLP technology is still in its early stages within the materials field, there is a growing trend toward the development of material-specific pre-trained language models to provide high-quality word embeddings for chemical substances, elements, and other materials information such as word2vec and BERT. These embeddings can help capture latent syntactic and semantic similarities among words in literature, facilitating candidate materials screening and serving as input vectors for property prediction.
Initially, word embeddings for materials science have been constructed with Word2vec using information about the co-occurrences of words in the scientific literature. During training, target words are represented as vectors with ones at their corresponding vocabulary indices and zeros everywhere else (one-hot encoding). These one-hot encoded vectors are used as inputs for a neural network with a single linear hidden layer, which is trained to predict all words mentioned within a certain distance (context words) from the given target word. For similar materials such as “iron” and “steel”, when trained on a suitable body of text, such methods should produce a vector representing the word “iron” that is closer by cosine distance to the vector for “steel” than to the vector for “organic”. Words with similar meanings often appear in similar contexts, and the analogies are expressed by finding the nearest word to the result of subtraction and addition operations between the embeddings. As shown in Fig. 6a, Tshitoyan et al.3 utilized the skip-gram variation of Word2vec on 3.3 million scientific abstracts from over 1000 materials-related journals published between 1922 and 2018. This model was trained to predict context words near the target word, enabling the learning of a 200-dimensional embedding for each target word. Subsequently, this word embedding was employed to identify potential material formulae with similar properties through cosine similarity calculations. They found that several materials that have relatively high cosine similarities to the word ‘thermoelectric’ never appeared explicitly in the same abstract with this word or any other words that unequivocally identify materials as thermoelectrics. Pei et al.40 also adopted the skip-gram algorithm on 6.4 million materials-related abstracts plus abstracts on metallic materials, and successfully represented high-entropy alloys by 200-dimensional word vectors, shown in Fig. 6b. The approach identified the representative FCC Cantor and BCC Senkov alloys as the most promising high-entropy alloys, long before they had been discovered and synthesized. Word2vec captures the semantic meanings of words, allowing to find words that have similar meanings. The model is shallow with two-layer neural networks and is relatively efficient to train. However, the embeddings produced by word2vec are static and do not account for the context in which a word is used. Also, it cannot handle out-of-vocabulary words at inference time. New words or rare words that did not appear in the training data have no vector representation.

a One-hot encoded vectors are used as inputs for a neural network with a single linear hidden layer, which is trained to predict context words from the given target word. A ranking of thermoelectric materials produced using cosine similarities of material embeddings with the embedding of the word ‘thermoelectric’ [Reprinted with permission from ref. 3. Copyright 2019 Springer Nature]. b To design multi-component high-entropy alloys with word embeddings, one method starts with one element that must be included and its four most similar elements are then selected according to cosine similarity. The second method considers all participating elements equally with the cosine similarity of any two elements averaged to measure its potency as a candidate. The five-component alloys are ranked by their context similarity for different publication years including the Senkov alloy of TiZrNbHfTa, TiZrNbMoHf, and TiZrMoHfTa. [Reprinted according to the terms of the CC-BY license ref. 40].
Fine-tuned language models and property prediction
To overcome these shortcomings, transformer-based language models, which rely on self-attention mechanisms to weigh the importance of different parts of the input data, have the capability to capture long-range dependencies in the text. BERT was introduced by Google in 2018 and produces contextualized word embeddings, meaning that the embedding for a word is dependent on the surrounding words in the sentence. This is different from traditional word embeddings methods Word2Vec or GloVe, where each word has a single, static embedding. It has also inspired numerous follow-up studies and variations, such as RoBERTa, ALBERT, and DistilBERT, which aim to improve upon BERT’s performance and efficiency. The original BERT model utilized a 30-million token vocabulary in its dictionary and was pre-trained on the Books Corpus (800 million words) and English Wikipedia (2500 million words). However, the original pretrained BERT lacks materials domain knowledge and therefore does not give reliable embeddings for materials information. As shown in Fig. 7, to enhance BERT’s domain adaptation capabilities within the scientific field, Beltagy et al.102 introduced SCIBERT, a pre-trained language model based on BERT. SCIBERT was trained on a large multi-domain corpus of scientific publications comprising 1.14 million papers, with 18% from the computer science domain and 82% from the broader biomedical domain using a single TPU v3 with 8 cores, resulting in a total corpus size of 3.17 billion tokens. SCIBERT significantly outperformed BERT-Base and achieves new state-of-the-art results on several downstream scientific NLP tasks.

The BERT model by Google utilizing the Transformer framework serves as the foundation for materials BERT models. These specialized models are refined through pre-training and fine-tuning with targeted materials corpora, which can be utilized as encoders to generate numerical representations for materials information sequence, such as polymer chemical fingerprinting and synthesis routes, facilitating the establishment of correlations with material properties.
By extending the pre-training of SciBERT, Gupta et al.103 introduced a materials-aware language model, MatSciBERT, which was trained on a corpus of peer-reviewed materials science publications covering five key materials science families: inorganic glasses, metallic glasses, alloys, cement and concrete, and two-dimensional materials. MatSciBERT was effectively trained with a maximum sequence length of 512 tokens over a period of fifteen days on 2 NVIDIA V100 32GB GPUs on a corpus comprising 3.17 billion (SciBERT) + 0.28 billion (MatSciBERT) = 3.45 billion words. MatSciBERT exhibits superior performance on several downstream information extraction tasks, such as document classification, NER, and relation classification, compared to SciBERT. Yoshitake et al.104 employed the original BERT code to train MaterialBERT using 750,000 inorganic, organic, and composite materials articles published between 2005 and 2019 with approximately 3000 million words in the corpus. The model was trained on two NVIDIA Tesla V100 GPUs, taking three months to complete. MaterialBERT models can be used as a starting point for transfer learning to generate a narrower domain-specific BERT model in the materials science field such as “phase diagram,” “resin,” “liquid crystal,” etc.
By using the literature corpus in a specific material field and based on a certain version of the BERT model, a dedicated BERT model for a specific material field can be trained. The scope of material corpus for training depends on the application of the downstream task. Zhao et al.105 introduced two “materials-aware” text-based language models for optical research, namely OpticalBERT, which was trained on a corpus of optical materials. They also developed a battery-focused BERT model, called BatteryBERT, which was trained on a dataset of battery research papers106. The pretrained BatteryBERT model was subsequently fine-tuned for specific downstream tasks, such as battery paper classification and question-answering for categorizing battery device components such as anode, cathode, and electrolyte materials. Such dedicated BERT models exhibit superior text classification and NER performance compared to the original BERT models when evaluated on these domain-specific tasks.
Beyond materials information extraction tasks, the dedicated BERT models can also be used as an encoder to generate numerical representations for materials information sequence, such as polymer chemical fingerprinting and synthesis routes, which can be further used to establish relationship with properties. Kuenneth et al.60 trained polyBERT using DeBERTa on a dataset comprising 100 million hypothetical polymers generated by exhaustively combining chemical fragments derived from a database of over 13,000 synthesized polymers. Through training, polyBERT learns to convert input PSMILES strings into numerical representations as polymer fingerprints, and a multitask ML framework then predicts polymer properties. The total CO2 emissions for predicting 29 properties of 100 million hypothetical polymers is estimated to be 5.5 kgCO2eq. At the same time, Xu et al.107 introduced TransPolymer for polymer property predictions, which is pretrained through MLM with approximately 5 million augmented unlabeled polymers from the PI1M database. In MLM, tokens in sequences are randomly masked with the objective to recover the original tokens based on the context. TransPolymer is finetuned on ten datasets of polymers with various properties, covering polymer electrolyte conductivity, band gap, electron affinity, ionization energy, crystallization tendency, dielectric constant, refractive index, and p-type polymer OPV power conversion efficiency.
For alloys, Tian et al.108 pretrained SteelBERT using DeBERTa on a corpus comprising 4.2 million abstracts related to materials science and 55,000 full-text articles on steels, as illustrated in Fig. 8. SteelBERT is a linguist specialized in the language of steel materials. After tokenization, the training corpus is passed to DeBERTa with12 attention heads in each of the 12 Transformer encoders. SteelBERT is used to generate embeddings with 768 dimensions for textual processing routes and chemical compositions. Subsequently, a deep learning network model is trained to receive the embedded composition and text associated with the processing route as input to predict mechanical properties. The determination coefficients (R2) for yield strength, ultimate tensile strength, and total elongation reach 78.17% (±3.40%), 82.56% (±1.96%), and 81.44% (±2.98%), respectively for 18 recently reported steels. Further, through an additional fine-tuning strategy with small laboratory datasets, the model efficiently optimizes the novel text sequence for the fabrication process, exceeding those of reported 15Cr austenitic stainless steels.

Quantitative mechanical property prediction with SteelBERT, encompassing several steps of corpus collection, pretraining, context-aware representation of steel information, a predictive model using a deep learning network and fine-tuning on laboratory dataset for austenitic stainless-steel design.
To fully harness the potential of LLMs, fine-tuning GPT models with materials-related datasets can align LLMs toward scientific inquiry in the materials domain109. Xie et al.110 introduced DARWIN, a collection of specialized LLaMA designed for natural sciences, particularly in the fields of physics, chemistry, and materials science. These tailored LLMs utilize open-source frameworks and integrate both structured and unstructured scientific information sourced from public datasets and the literature. DARWIN is trained to be equipped to perform a wide range of tasks related to materials and device predictions, including classification, regression, and inverse design. GPT models can serve as material generation tools to expand the chemical space and identify materials with desired properties. Mok et al.111 introduced the Catalyst Generation Pretrained Transformer (CatGPT), a model trained to generate string representations of inorganic catalyst structures across a broad chemical space. CatGPT generates catalyst structures and serves as a base model for targeted catalyst generation through text conditioning and fine-tuning. The model was fine-tuned using a binary alloy catalyst dataset, enabling the generation of catalyst structures specifically tailored for two-electron oxygen reduction reaction.
AI agents for autonomous research in materials science
Fine-tuning improves a model’s performance on specific tasks, such as materials property prediction, whereas AI agents powered by LLMs and integrated tools are trained to autonomously solve complex tasks. An AI agent is equipped to plan, make decisions, and call up tools. Its role is defined through prompt engineering so that users can customize the agent’s behavior to meet specific requirements. In-context learning allows an AI agent to accumulate experience and evolve so that its actions become increasingly consistent, logical, and effective over time. Techniques such as chain-of-thought and tree-of-thought approaches allow to decompose complex tasks into smaller, more manageable sub-tasks. By interacting with external tools, the plans devised by AI agents are translated into actionable steps and executed effectively.
AI agents have also recently been applied to autonomous materials design and experiments. By integrating LLMs with retrieval tools, agents can autonomously retrieve information from documents, databases, knowledge bases, and knowledge graphs. They perform tasks such as summarization, program planning, and task execution, enabling materials knowledge question-answer, hypothesis generation, performance and structure prediction, and automated experimentation.
For hypothesis generation, Ghafarollahi et al.112 introduced SciAgents, an AI system that helps discover new ideas in materials science by generating and refining research hypotheses. Using a combination of language models, knowledge graphs, and specialized AI agents, SciAgents finds hidden connections between scientific concepts and explores new materials properties. The system automates complex research tasks, allowing agents to propose and improve ideas together. This approach speeds up discovery, suggesting that AI could become a valuable tool in advancing scientific research.
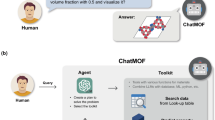
In particular, for performance and structure prediction, Ghafarollahi et al.113 introduced the AtomAgents platform, featuring AI agents that collaborate in a dynamic environment to automate complex materials design processes. By combining LLMs with knowledge retrieval, multi-modal data integration, and physics-based simulations, AtomAgents effectively perform alloy design. Computational experiments then reveal the proficiency in material property calculations and defect analysis, enabling the autonomous design of alloys with superior properties compared to pure metals. Ding et al.114 introduce MatExpert to leverages LLMs and contrastive learning for crystal generation. MatExpert performs detailed computations and structural generation and outperforms state-of-the-art methods in material generation tasks. Zhang et al.115 introduced HoneyComb, a framework that integrates a high-quality knowledge base (MatSciKB), a sophisticated tool hub, and an efficient retriever module to enhance LLM performance in materials science tasks, achieving improvements of up to 20.61% on the MaScQA dataset and 45.73% on the SciQA dataset. Kang et al.61 built an AI system called ChatMOF to manage data retrieval, property prediction, and structure generation tasks by leveraging a large-scale language model (GPT-4, GPT-3.5-turbo, and GPT-3.5-turbo-16k). ChatMOF shows high accuracy rates of 96.9% for text-based data searching, 95.7% for property predicting, and 87.5% for structure-generating tasks with GPT-4. Furthermore, ChatMOF successfully generates materials that meet user-defined requirements, such as structures with the largest surface area or targeted hydrogen uptake targets. Zhang et al.116 developed an AI agent for organic field-effect transistors (OFETs) by integrating a generative pre-trained GPT-4 with a well-trained ML algorithm. This system extracts experimental parameters for OFETs from the scientific literature, achieving over 92% accuracy and recall. Additionally, the AI agent provides a feasible optimization scheme that has tripled the charge transport properties of 2,6-diphenyldithieno[3,2-b:2′,3′-d]thiophene OFETs.
By integrating with robotic experimental platforms, AI agents can be empowered to conduct complex experiments, effectively replacing human involvement in the entire process. Boiko et al.5 developed an AI system called Coscientist to autonomously plan, execute, and optimize real-world chemical experiments (Fig. 9). Using large language models with tools such as internet and document search, code execution, and experimental automation, Coscientist demonstrates advanced reasoning and experimental design capabilities. The system effectively tackles complex scientific challenges and generates high-quality code. With appropriate prompt inputs, the system successfully performs and optimizes cross-coupling Suzuki and Sonogashira reaction experiments. This study demonstrates that AI has the potential to accelerate the pace of scientific discoveries, enhance their scalability, and improve the reproducibility and reliability of experimental outcomes.

The architecture of the Coscientist system to solve a complex problem by interacting with multiple modules (web and documentation search, code execution) to perform experiments. a Coscientist is composed of multiple modules that exchange messages. Boxes with blue background represent LLM modules, the Planner module is shown in green, and the input prompt is in red. White boxes represent modules that do not use LLMs. b Types of experiments performed using individual modules or their combinations. c Image of the experimental setup with a liquid handler. [Reprinted according to the terms of the CC-BY license ref. 5].
Challenges and future developments
NLP and LLMs have significantly enhanced the ability to analyze, extract, and interpret valuable information from extensive materials science literature. Leveraging LLMs in materials science presents considerable challenges due to the domain’s complexity and specificity. Key issues include numerical understanding, quantitative prediction, structural interpretation, and the need for scientific reasoning.
Numerical understanding
Numerical values in natural language text are essential for solving quantitative problems, especially in predicting material properties. However, LLMs often struggle with numerical comprehension. For instance, they typically have difficulty associating the word embedding of “100” with the numerical value 100.0, which can lead to inaccuracies when correlating composition and processing routes with material properties. Systematically enhancing the numerical capabilities of LLMs requires a focus on dataset construction, model architecture design, task planning, training strategy optimization, and tool integration. Creating a high-quality numerical dataset tailored for materials science is crucial in providing LLMs with accurate and comprehensive training corpus. Additionally, fine-tuning LLMs for numerical tasks specific to materials science will ensure they can accurately capture and interpret numerical information.
Quantitative prediction
Establishing a quantitative relationship between composition, processing routes, and properties from text is challenging for LLMs. For instance, instruct fine-tuning the Llama 8B model using only 677 records does not yield satisfactory prediction performance108. To address this, strategies such as developing an end-to-end framework that integrates a materials language encoder with a property prediction network are necessary. Additionally, employing AI agents that integrate computational tools, such as finite element modeling software, thermodynamic simulators, and material property prediction models, can enhance performance.
Efficiency and optimization of resources
Given the computational costs of training LLMs, there is a need to examine how LLMs with far fewer parameters may be devised that show comparable performance. For example, LLaMA 8B, the smaller counterpart to LLaMA 70B shows superior performance on fine tuning with datasets for steels108 than its larger counterpart, suggesting that larger decoder-only models, though effective for general tasks, may struggle in highly specialized domains like materials science. This is likely influenced by the distribution and composition of the training corpus. Larger models, such as LLaMA 70B, are typically trained on extensive and diverse datasets to enhance generalizability across a wide range of tasks. However, this broader focus can dilute attention to domain-specific patterns. In contrast, the smaller scale of the LLaMA 8B model may produce embeddings that are less affected by peripheral information from unrelated domains, thereby maintaining a stronger alignment with the core patterns embedded in the training data. A promising approach to balancing model size and performance is knowledge distillation, where a smaller student model is trained to mimic a larger teacher model while retaining essential reasoning capabilities. This technique compresses knowledge from high-parameter models into lighter, more computationally efficient architectures without significant performance degradation. From a practical standpoint, optimizing LLMs for materials science requires a careful balance between model size, dataset diversity, and domain specificity. Future research should explore hybrid strategies that combine parameter-efficient architectures, domain-specific fine-tuning, and distillation techniques to develop scalable and cost-effective LLMs tailored for materials science applications.
Scientific reasoning
The training corpus of LLMs primarily consists of general text data, which often lacks domain-specific terminology and precise scientific knowledge. As a result, LLMs may generate inaccurate, misleading, or hallucinated information, including incorrect numerical values and unrealistic materials or processes. This uncertainty poses challenges for reliable information extraction and question-answering, hindering their application in materials science. To mitigate hallucinations, retrieval-augmented generation (RAG) has emerged as an effective strategy, enabling LLMs to access verifiable, high-quality materials data before generating responses. Beyond retrieval, enhancing scientific reasoning through advanced training techniques is crucial. Recently, DeepSeek-R1 has been introduced and has generated enormous attention for its efficiency and limited use of resources. It implements state-of-the-art “reasoning” capabilities by leveraging large-scale reinforcement learning (RL)57 that builds on Proximal Policy Optimization that improves mathematical reasoning while reducing memory. By integrating a small amount of cold-start data, its multi-stage training pipeline is initiated with reasoning-oriented RL using rewards, followed by rejection sampling supervised fine tuning and a secondary stage of RL for further refinement. DeepSeek-R1 achieves performance comparable to OpenAI-o1-1217 on complex reasoning tasks. In addition, DeepSeek demonstrated the importance of distillation by drastically reducing the size of its large model by using it to train smaller models based on Llama and Qwen with far fewer parameters, which even outperform openAI-o1-mini and GPT-4o-0513 in reasoning tasks. Hence, incorporating RL into materials science applications117 promises to significantly enhance LLMs’ reasoning abilities, enabling better predictions for complex materials, data-driven discoveries, and reliable AI-assisted research workflows. As RL-driven optimization continues to evolve, LLMs are poised to become powerful tools in accelerating materials discovery and innovation.
Despite the challenges, NLP and LLMs have demonstrated some success in materials design. They have been employed to accelerate the discovery of materials by analyzing vast datasets to extract patterns, generate hypotheses and guide experiments. For example, they have been applied to predict materials properties60, identify optimal compositions3,40, and suggest processing conditions37 with promising results, especially in alloy development108 and polymer design60. Looking ahead, advances currently being made will enable LLMs to achieve even greater success by enhancing numerical reasoning, quantitative predictions, and structural interpretations. Future success will likely depend on a seamless integration of LLMs with computational, experimental, and data-driven tools, leading to real-time insights that empower researchers to rapidly make informed decisions. Ultimately, it is hoped that this evolution will not only streamline the materials design process but also foster innovative breakthroughs to significantly reduce the time and costs of materials discovery.
References
Wang, W. Y. et al. Artificial intelligence enabled smart design and manufacturing of advanced materials: The endless Frontier in AI + era. Mater. Genome Eng. Adv. 2, e56 (2024).
Ramprasad, R., Batra, R., Pilania, G., Mannodi-Kanakkithodi, A. & Kim, C. Machine learning in materials informatics: recent applications and prospects. Npj Comput. Mater. 3, 54 (2017).
Tshitoyan, V. et al. Unsupervised word embeddings capture latent knowledge from materials science literature. Nature 571, 95–98 (2019).
Szymanski, N. J. et al. An autonomous laboratory for the accelerated synthesis of novel materials. Nature 624, 86–91 (2023).
Boiko, D. A., MacKnight, R., Kline, B. & Gomes, G. Autonomous chemical research with large language models. Nature 624, 570–578 (2023).
Merchant, A. et al. Scaling deep learning for materials discovery. Nature 624, 80–85 (2023).
Esterhuizen, J. A., Goldsmith, B. R. & Linic, S. Interpretable machine learning for knowledge generation in heterogeneous catalysis. Nat. Catal. 5, 175–184 (2022).
Hart, G. L. W., Mueller, T., Toher, C. & Curtarolo, S. Machine learning for alloys. Nat. Rev. Mater. 6, 730–755 (2021).
Gu, L. et al. Bond sensitive graph neural networks for predicting high temperature superconductors. Mater. Genome Eng. Adv. 2, e48 (2024).
Xie, J. Prospects of materials genome engineering frontiers. Mater. Genome Eng. Adv. 1, e17 (2023).
Li, S. et al. Optimal design of high‐performance rare‐earth‐free wrought magnesium alloys using machine learning. Mater. Genome Eng. Adv. 2, e45 (2024).
Jiang, X., Wang, Y., Jia, B., Qu, X. & Qin, M. Using machine learning to predict oxygen evolution activity for transition metal hydroxide electrocatalysts. ACS Appl. Mater. Interfaces 14, 41141–41148 (2022).
Xue, D. et al. Accelerated search for materials with targeted properties by adaptive design. Nat. Commun. 7, 1–9 (2016).
Jiang, X. et al. A strategy combining machine learning and multiscale calculation to predict tensile strength for pearlitic steel wires with industrial data. Scr. Mater. 186, 272–277 (2020).
Wen, C. et al. Modeling solid solution strengthening in high entropy alloys using machine learning. Acta Mater. 212, 116917 (2021).
Wen, C. et al. Machine learning assisted design of high entropy alloys with desired property. Acta Mater. 170, 109–117 (2019).
Zhang, Y. et al. Phase prediction in high entropy alloys with a rational selection of materials descriptors and machine learning models. Acta Mater. 185, 528–539 (2020).
Yang, Z. et al. Scalable crystal structure relaxation using an iteration-free deep generative model with uncertainty quantification. Nat. Commun. 15, 8148 (2024).
Olivetti, E. A. et al. Data-driven materials research enabled by natural language processing and information extraction. Appl. Phys. Rev. 7, 041317 (2020).
Jain, A. et al. Commentary: The Materials Project: A materials genome approach to accelerating materials innovation. APL Mater .1, 011002 (2013).
Kirklin, S. et al. The Open Quantum Materials Database (OQMD): assessing the accuracy of DFT formation energies. Npj Comput. Mater. 1, 1–15 (2015).
Liu, S. et al. An infrastructure with user-centered presentation data model for integrated management of materials data and services. Npj Comput. Mater. 7, 88 (2021).
Esters, M. et al. aflow. org: A web ecosystem of databases, software and tools. Comput. Mater. Sci. 216, 111808 (2023).
Scheidgen, M. et al. NOMAD: A distributed web-based platform for managing materials science research data. J. Open Source Softw. 8, 5388 (2023).
Zhou, M., Duan, N., Liu, S. & Shum, H.-Y. Progress in neural NLP: modeling, learning, and reasoning. Engineering 6, 275–290 (2020).
Jessop, D. M., Adams, S. E., Willighagen, E. L., Hawizy, L. & Murray-Rust, P. OSCAR4: a flexible architecture for chemical text-mining. J. Cheminformatics 3, 41 (2011).
Mavračić, J., Court, C. J., Isazawa, T., Elliott, S. R. & Cole, J. M. ChemDataExtractor 2.0: Autopopulated Ontologies for Materials Science. J. Chem. Inf. Model. 61, 4280–4289 (2021).
Huang, S. & Cole, J. M. BatteryDataExtractor: battery-aware text-mining software embedded with BERT models. Chem. Sci. 13, 11487–11495 (2022).
Swain, M. C. & Cole, J. M. ChemDataExtractor: A Toolkit For Automated Extraction Of Chemical Information From The Scientific Literature. J. Chem. Inf. Model. 56, 1894–1904 (2016).
Kononova, O. et al. Text-mined dataset of inorganic materials synthesis recipes. Sci. Data 6, 203 (2019).
Vaucher, A. C. et al. Automated extraction of chemical synthesis actions from experimental procedures. Nat. Commun. 11, 3601 (2020).
Huo, H. et al. Semi-supervised machine-learning classification of materials synthesis procedures. Npj Comput. Mater. 5, 62 (2019).
Mehr, S. H. M., Craven, M., Leonov, A. I., Keenan, G. & Cronin, L. A universal system for digitization and automatic execution of the chemical synthesis literature. Science 370, 101–108 (2020).
Cruse, K. et al. Text-mined dataset of gold nanoparticle synthesis procedures, morphologies, and size entities. Sci. Data 9, 234 (2022).
Wang, W. et al. Automated pipeline for superalloy data by text mining. Npj Comput. Mater. 8, 9 (2022).
Pfeiffer, O. P. et al. Aluminum alloy compositions and properties extracted from a corpus of scientific manuscripts and US patents. Sci. Data 9, 128 (2022).
Wang, W. et al. Alloy synthesis and processing by semi-supervised text mining. Npj Comput. Mater. 9, 183 (2023).
Mikolov, T., Chen, K., Corrado, G. & Dean, J. Efficient estimation of word representations in vector space.Preprint at https://doi.org/10.48550/arXiv.1301.3781 (2013).
Mikolov, T., Sutskever, I., Chen, K., Corrado, G. S. & Dean, J. Distributed representations of words and phrases and their compositionality. Adv. Neural Inf. Process. Syst .26, 3111–3119 (2013).
Pei, Z., Yin, J., Liaw, P. K. & Raabe, D. Toward the design of ultrahigh-entropy alloys via mining six million texts. Nat. Commun. 14, 54 (2023).
OpenAI et al. GPT-4 Technical Report. Preprint at http://arxiv.org/abs/2303.08774 (2023).
Almazrouei, E. et al. The Falcon Series of Open Language Models. Preprint at http://arxiv.org/abs/2311.16867 (2023).
Devlin, J., Chang, M.-W., Lee, K. & Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies. Vol. 1, 4171–4186. Preprint at http://arxiv.org/abs/1810.04805 (2019).
Thoppilan, R. et al. LaMDA: Language Models for Dialog Applications. Preprint at http://arxiv.org/abs/2201.08239 (2022).
Touvron, H. et al. LLaMA: Open and Efficient Foundation Language Models. Preprint at http://arxiv.org/abs/2302.13971 (2023).
Touvron, H. et al. Llama 2: Open Foundation and Fine-Tuned Chat Models. Preprint at http://arxiv.org/abs/2307.09288 (2023).
Chowdhery, A. et al. Palm: Scaling language modeling with pathways. J. Mach. Learn. Res. 24, 1–113 (2023).
Driess, D. et al. PaLM-E: An Embodied Multimodal Language Model. Preprint at http://arxiv.org/abs/2303.03378 (2023).
Vaswani, A. et al. Attention is all you need. Adv. Neural Inf. Process. Syst. 30, 5998–6008 (2017).
Kaplan, J. et al. Scaling Laws for Neural Language Models. Preprint at http://arxiv.org/abs/2001.08361 (2020).
Zhao, W. X. et al. A Survey of Large Language Models. Preprint at http://arxiv.org/abs/2303.18223 (2023).
Han, X. et al. Pre-trained models: Past, present and future. AI Open 2, 225–250 (2021).
Chen, M. et al. Evaluating Large Language Models Trained on Code. Preprint at http://arxiv.org/abs/2107.03374 (2021).
Brown, T. et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 33, 1877–1901 (2020).
Austin, J. et al. Program Synthesis with Large Language Models. Preprint at http://arxiv.org/abs/2108.07732 (2021).
Ahmad, W. U., Chakraborty, S., Ray, B. & Chang, K.-W. Unified Pre-training for Program Understanding and Generation. Preprint at http://arxiv.org/abs/2103.06333 (2021).
DeepSeek-AI et al. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. Preprint at https://doi.org/10.48550/arXiv.2501.12948 (2025).
Pei, Z., Yin, J., Neugebauer, J. & Jain, A. Towards the holistic design of alloys with large language models. Nat. Rev. Mater. 9, 840–841 (2024).
Zheng, Z., Zhang, O., Borgs, C., Chayes, J. T. & Yaghi, O. M. ChatGPT Chemistry Assistant for Text Mining and the Prediction of MOF Synthesis. J. Am. Chem. Soc. jacs.3c05819 https://doi.org/10.1021/jacs.3c05819 (2023).
Kuenneth, C. & Ramprasad, R. polyBERT: a chemical language model to enable fully machine-driven ultrafast polymer informatics. Nat. Commun. 14, 4099 (2023).
Kang, Y. ChatMOF: an artificial intelligence system for predicting and generating metal-organic frameworks using large language models. Nat. Commun. 15, 4705 (2024).
Dong, L. et al. Unified language model pre-training for natural language understanding and generation. Adv. Neural Inf. Process 32, 13063–13075 (2019).
Cambria, E. & White, B. Jumping NLP curves: A review of natural language processing research. IEEE Comput. Intell. Mag. 9, 48–57 (2014).
Bojanowski, P., Grave, E., Joulin, A. & Mikolov, T. Enriching word vectors with subword information. Trans. Assoc. Comput. Linguist. 5, 135–146 (2017).
Pennington, J., Socher, R. & Manning, C. D. Glove: Global vectors for word representation. in Proceedings of the 2014 Conference on Empirical Methods In Natural Language Processing (EMNLP) 1532–1543 (2014).
Erhan, D., Courville, A., Bengio, Y. & Vincent, P. Why does unsupervised pre-training help deep learning? in Proceedings of the 13th International Conference on Artificial Intelligence and Statistics 201–208 (JMLR Workshop and Conference Proceedings, 2010).
Song, K., Tan, X., Qin, T., Lu, J. & Liu, T.-Y. Mass: Masked sequence to sequence pre-training for language generation. https://doi.org/10.48550/arXiv.1905.02450 (2019).
Peters, M. E. et al. Deep contextualized word representations. https://doi.org/10.48550/arXiv.1802.05365 (2018).
Ethayarajh, K. How contextual are contextualized word representations? Comparing the geometry of BERT, ELMo, and GPT-2 embeddings. https://doi.org/10.48550/arXiv.1909.00512 (2019).
Radford, A. et al. Language models are unsupervised multitask learners. OpenAI Blog 1, 9 (2019).
Radford, A., Narasimhan, K., Salimans, T. & Sutskever, I. Improving language understanding by generative pre-training. https://openai.com/index/language-unsupervised/ (2018).
Zhang, Y. & Yang, Q. A survey on multi-task learning. IEEE Trans. Knowl. Data Eng. 34, 5586–5609 (2021).
Wang, Y., Yao, Q., Kwok, J. T. & Ni, L. M. Generalizing from a few examples: A survey on few-shot learning. ACM Comput. Surv. Csur 53, 1–34 (2020).
Finn, C., Abbeel, P. & Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. in International Conference on Machine Learning 1126–1135 (PMLR, 2017).
Dong, Q. et al. A survey on in-context learning. https://doi.org/10.48550/arXiv.2301.00234 (2022).
Ouyang, L. et al. Training language models to follow instructions with human feedback. Adv. Neural Inf. Process. Syst. 35, 27730–27744 (2022).
Lammey, R. CrossRef’s Text and Data Mining Services. Learn. Publ. 27, 245–250 (2014).
White, J. et al. A prompt pattern catalog to enhance prompt engineering with chatgpt. https://doi.org/10.48550/arXiv.2302.11382 (2023).
Liu, Y. et al. Jailbreaking chatgpt via prompt engineering: An empirical study. https://doi.org/10.48550/arXiv.2305.13860 (2023).
Dagdelen, J. et al. Structured information extraction from scientific text with large language models. Nat. Commun. 15, 1418 (2024).
Court, C. J. & Cole, J. M. Auto-generated materials database of Curie and Néel temperatures via semi-supervised relationship extraction. Sci. Data 5, 180111 (2018).
Weston, L. et al. Named entity recognition and normalization applied to large-scale information extraction from the materials science literature. J. Chem. Inf. Model. 59, 3692–3702 (2019).
Shetty, P. et al. A general-purpose material property data extraction pipeline from large polymer corpora using natural language processing. Npj Comput. Mater. 9, 52 (2023).
Yan, R., Jiang, X., Wang, W., Dang, D. & Su, Y. Materials information extraction via automatically generated corpus. Sci. Data 9, 401 (2022).
Hawizy, L., Jessop, D. M., Adams, N. & Murray-Rust, P. ChemicalTagger: A tool for semantic text-mining in chemistry. J. Cheminformatics 3, 1–13 (2011).
Beard, E. J. & Cole, J. M. Perovskite- and dye-sensitized solar-cell device databases auto-generated using ChemDataExtractor. Sci. Data 9, 329 (2022).
Dong, Q. & Cole, J. M. Auto-generated database of semiconductor band gaps using ChemDataExtractor. Sci. Data 9, 193 (2022).
Kumar, P., Kabra, S. & Cole, J. M. Auto-generating databases of yield strength and grain size using ChemDataExtractor. Sci. Data 9, 292 (2022).
Zhao, J. & Cole, J. M. A database of refractive indices and dielectric constants auto-generated using ChemDataExtractor. Sci. Data 9, 192 (2022).
Kim, E. et al. Materials synthesis insights from scientific literature via text extraction and machine learning. Chem. Mater. 29, 9436–9444 (2017).
Kim, E. et al. Machine-learned and codified synthesis parameters of oxide materials. Sci. Data 4, 170127 (2017).
Wilary, D. M. & Cole, J. M. ReactionDataExtractor: A Tool for Automated Extraction of Information from Chemical Reaction Schemes. J. Chem. Inf. Model. 61, 4962–4974 (2021).
He, T. et al. Similarity of Precursors in Solid-State Synthesis as Text-Mined from Scientific Literature. Chem. Mater. 32, 7861–7873 (2020).
He, T. et al. Precursor recommendation for inorganic synthesis by machine learning materials similarity from scientific literature. Sci. Adv. 9, eadg8180 (2023).
Wang, Z. et al. Dataset of solution-based inorganic materials synthesis procedures extracted from the scientific literature. Sci. Data 9, 231 (2022).
Kim, E. et al. Inorganic Materials Synthesis Planning with Literature-Trained Neural Networks. J. Chem. Inf. Model. 60, 1194–1201 (2020).
Kim, E., Huang, K., Jegelka, S. & Olivetti, E. Virtual screening of inorganic materials synthesis parameters with deep learning. Npj Comput. Mater. 3, 53 (2017).
da Silva, V. T. et al. Automated, LLM enabled extraction of synthesis details for reticular materials from scientific literature. https://doi.org/10.48550/arXiv.2411.03484 (2024).
Thway, M. et al. Harnessing GPT-3.5 for text parsing in solid-state synthesis–case study of ternary chalcogenides. Digit. Discov. 3, 328–336 (2024).
Polak, M. P. & Morgan, D. Extracting accurate materials data from research papers with conversational language models and prompt engineering. Nat. Commun. 15, 1569 (2024).
Xie, T. et al. Creation of a structured solar cell material dataset and performance prediction using large language models. Patterns 5, 100955 (2024).
Beltagy, I., Lo, K. & Cohan, A. SciBERT: A pretrained language model for scientific text. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 3615–3620 (Hong Kong, 2019).
Gupta, T., Zaki, M., Krishnan, N. M. A. & Mausam MatSciBERT: A materials domain language model for text mining and information extraction. Npj Comput. Mater. 8, 102 (2022).
Yoshitake, M., Sato, F., Kawano, H. & Teraoka, H. MaterialBERT for natural language processing of materials science texts. Sci. Technol. Adv. Mater. Methods 2, 372–380 (2022).
Zhao, J., Huang, S. & Cole, J. M. OpticalBERT and OpticalTable-SQA: Text- and Table-Based Language Models for the Optical-Materials Domain. J. Chem. Inf. Model. 63, 1961–1981 (2023).
Huang, S. & Cole, J. M. BatteryBERT: A Pretrained Language Model for Battery Database Enhancement. J. Chem. Inf. Model. 62, 6365–6377 (2022).
Xu, C., Wang, Y. & Barati Farimani, A. TransPolymer: a Transformer-based language model for polymer property predictions. Npj Comput. Mater. 9, 64 (2023).
Tian, S. et al. Steel design based on a large language model. Acta Mater. 285, 120663 (2025).
Xie, T. et al. Large Language Models as Master Key: Unlocking the Secrets of Materials Science with GPT. Preprint at http://arxiv.org/abs/2304.02213 (2023).
Xie, T. et al. DARWIN Series: Domain Specific Large Language Models for Natural Science. Preprint at http://arxiv.org/abs/2308.13565 (2023).
Mok, D. H. & Back, S. Generative Pretrained Transformer for Heterogeneous Catalysts. J. Am. Chem. Soc. jacs.4c11504 https://doi.org/10.1021/jacs.4c11504 (2024).
Ghafarollahi, A. & Buehler, M. J. SciAgents: Sciagents: Automating scientific discovery through multi-agent intelligent graph reasoning. https://doi.org/10.48550/arXiv.2409.05556 (2024).
Ghafarollahi, A. & Buehler, M. J. AtomAgents: Alloy design and discovery through physics-aware multi-modal multi-agent artificial intelligence. Preprint at http://arxiv.org/abs/2407.10022 (2024).
Ding, Q., Miret, S. & Liu, B. MatExpert: Decomposing Materials Discovery by Mimicking Human Experts. Preprint at http://arxiv.org/abs/2410.21317 (2024).
Zhang, H., Song, Y., Hou, Z., Miret, S. & Liu, B. Honeycomb: a flexible llm-based agent system for materials science. In Findings of the association for computational linguistics: EMNLP 2024. 3369–3382 Preprint at http://arxiv.org/abs/2409.00135 (Miami, Florida, USA, 2024).
Zhang, Q. et al. Large‐Language‐Model‐Based AI Agent for Organic Semiconductor Device Research. Adv. Mater. 36, 2405163 (2024).
Xian, Y. et al. Compositional design of multicomponent alloys using reinforcement learning. Acta Mater. 274, 120017 (2024).
Acknowledgements
This work is financially supported by the National Key Research and Development Program of China (2022YFB3707502), National Natural Science Foundation of China (92270001, 52201061, U22A20106, 52350710205), Guangdong Province Key Areas Research and Development Programs (2024B0101080003), Guangdong Basic and Applied Basic Research Foundation (2023A1515140101).
Author information
Authors and Affiliations
Contributions
Y.S. led the collaboration. Y.S. and T.L. developed the paper outline. X.J. wrote a major part of the paper, W.W., S.T., and H.W. revised the paper. All authors reviewed and edited the paper.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Jiang, X., Wang, W., Tian, S. et al. Applications of natural language processing and large language models in materials discovery. npj Comput Mater 11, 79 (2025). https://doi.org/10.1038/s41524-025-01554-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41524-025-01554-0
