
Недавно три наших новых GPU-кластера заняли 19, 36 и 40 места в рейтинге суперкомпьютеров Top500. Это лучшие результаты среди всех участвующих в нём суперкомпьютеров России. Но сегодня мы поговорим не о местах в рейтинге, а о том, чем полезно на практике участие в подобных замерах.
Из этого поста вы узнаете про наши первые попытки создать свои кластеры и грабли на этом пути. Расскажем, как устроены суперкомпьютеры для машинного обучения и почему мы в итоге пришли к собственной архитектуре. Важная часть истории будет посвящена разбору проблем замеров производительности, которые, вопреки первым впечатлениям, принесли нам не только места в рейтинге, но и реальную пользу для наших ML-проектов.
Поможет мне в этом Дмитрий Монахов dmtrmonakhov. Он уже известен читателям Хабра по докладу о разработке ядра Linux. Передаю ему слово.
Привет! На связи Дмитрий. Последний год был очень необычным в Яндексе. Мы собрали и запустили три новых GPU-кластера для задач в области машинного обучения. (К примеру, теперь именно на них обучаются гигантские нейросетевые модели Поиска, Алисы и других наших сервисов.) Может показаться, что для запуска такого кластера самое сложное — это купить вагон GPU-карточек. В условиях «чипагеддона» это отчасти правда, но нет, самое сложное не в этом. Тут-то и начинается наша история.
Пробный подход к снаряду
В 2019 году произошла так называемая «революция трансформеров»: был опубликован ряд статей, которые показали, что применение гигантских нейросетей-трансформеров даёт удивительные результаты на задачах анализа текста. В частности, эти сети очень хорошо подходят для решения задачи ранжирования документов по запросу и для машинного перевода. Более того, их применение не ограничивается сугубо языковыми задачами: трансформерная архитектура позволяет генерировать голос из текста и наоборот, предсказывать действия пользователя и многое другое. В общем, именно трансформеры сейчас определяют качество основных продуктов Яндекса. (Если вам интересны детали, коллеги уже рассказывали на Хабре о внедрении этой архитектуры в нашем поиске.)
Но проблема была в том, что обучение таких моделей требует огромных вычислительных мощностей. Например, если обучать модель с нуля на обычном сервере, на это потребуется 40 лет, а если на одном GPU-ускорителе V100 — 10 лет. Но хорошая новость в том, что задача обучения легко параллелится, и если задействовать хотя бы 256 тех же самых V100, соединить их быстрым интерконнектом, то задачу можно решить всего за две недели. (Сейчас мы такую задачу можем решить за несколько часов, но об этом позже.)
Мы попробовали собрать «нулевой» кластер буквально из того, что было под рукой. Взяли несколько серверов, вставили в них по восемь GPU V100 от NVIDIA, а в качестве интерконнекта использовали две карты Mellanox ConnectX-5 EN в режиме RoCEv2. Попробовали. Расстроились.
Результаты замеров показали низкий КПД масштабирования. В попытках понять причину придумали методику оценки, которая не требовала глубокого понимания алгоритма работы конкретного обучения. Достаточно построить график потребления энергии и обмена трафиком в одном масштабе. Здесь приведён реальный график тех времен, полученный на «нулевом» клаcтере:
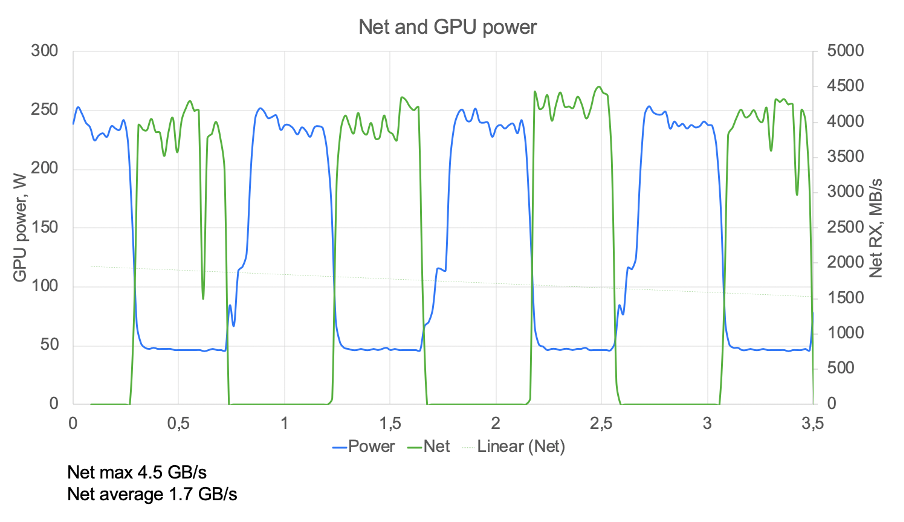
Даже без глубоких познаний в ML-моделях всё понятно. Обучение идет повторяющимися итерациями:
1. Каждый GPU получает свой batch и обсчитывает его (синяя ступенька)
2. Затем GPU обменивается по сети с соседями посчитанными результатами (зелёная ступенька)
3. GOTO 1
На графике сразу же виден корень проблемы. Время обмена по сети составило 50%, а GPU всё это время простаивал. Не самый эффективный способ использовать железо, согласитесь. Причина была в том, что серверы, которые у нас были под рукой, использовали PCIe Gen3 x8, и больше 62 Гбит/с по сети мы получить не могли. Эксперименты на таком кластере проводить можно, но считать что-то серьёзное — нереально. Поэтому стали собирать новое решение, «расшивая» все узкие места интерконнекта. Попутно столкнулись и с другими сложностями. Например, оказалось, что большинство стандартных утилит для работы с HPC (High Performance Computing) поддерживают только IPv4. Яндекс, в свою очередь, уже много лет живёт в дата-центрах IPv6-only. «Из коробки» мало что заработало сразу, пришлось фиксить. Фиксы, кстати, выкладываем в опенсорс.
— perftest не умеет в IPv6. Фикс здесь.
— openmpi неправильно работает, когда на интерфейсе больше одного IPv6-адреса. Забавно, что параллельно были написаны два фикса: первый и второй.
— nccl-test с перебором всех возможных маршрутов.
Времени прошло мало, поэтому многие патчи ещё не удалось донести до mainstream, но мы постараемся это сделать в ближайшее время.
Первые кластеры
Первый мини-кластер GPU, созданный специально под задачи применения трансформеров c учётом описанных выше узких мест, появился у нас во владимирском дата-центре летом 2020 года. Он был построен из стандартных серверов c NVIDIA Tesla V100-SXM2-32GB. В кластере было 62 узла по 8 GPU в каждом — всего 496 видеокарт. Казалось бы, сотни видеокарт! Но этого по-прежнему было мало для наших задач, хотя кластер и помог нам начать внедрять трансформеры для улучшения Поиска.
Затем в другом нашем ДЦ, в городе Сасово в Рязанской области, появился первый большой кластер. Мы назвали его в честь Алексея Ляпунова — знаменитого математика, чьи работы лежат в основе кибернетики и теории машинного обучения.

«Ляпунова» мы уже строили из серверов на базе NVIDIA HGX A100, в каждом из которых было:
— 2x AMD EPIC 7662, 512GB RAM
— 8x A100-40G
— 4x Mellanox ConnectX-6 IB 200Gib
В теории скорость обмена по сети между хостами должна была составить 96 ГБ/с, но первые замеры показали жалкие 40 ГБ/с. Мы вновь где-то потеряли 50%. В ходе многочасового хакатона с инженерами NVIDIA выяснилось, что проблема в скорости обмена по PCIe-шине между GPU и сетевой картой. Пришлось искать причины и оптимизировать.
— Отключение IOMMU/ACS. Включённый IOMMU стоил до 30% производительности, потому что трафик шёл не P2P, а через CPU.
— Оптимальные настройки сетевой карты при обмене PCIe позволили выжать заветные 200 Гбит/с из одного сетевого интерфейса и дали недостающие 20%.
Так мы получили 90 ГБ/с на тесте nccl-test/all_reduce_per и решили, что «Ляпунов» готов. Коллеги из локального офиса NVIDIA посоветовали потратить ещё несколько дней на замеры производительности, чтобы зарегистрировать кластер в списке Top500. Но в тот момент мы от этого отказались: торопились отдать кластер нашим ML-инженерам, чтобы загрузить его работой уже на новогодние праздники. Тем более, что тогда мы ещё не осознавали никакой практической пользы от замеров.
Первый кластер собственной архитектуры
У нас сильная команда R&D и мы уже давно проектируем собственные серверы, благодаря чему экономия на охлаждении может достигать 50%. Логично было распространить этот опыт и на GPU.
Для размещения кластеров выбрали недавно переданные в эксплуатацию модули в дата-центрах Сасово и Владимира. Сами кластеры назвали соответственно «Червоненкис» (в честь Алексея Червоненкиса, одного из крупнейших теоретиков машинного обучения) и «Галушкин» (Александр Галушкин — один из главных исследователей теории нейронных сетей).

Кластеры строили по модульной схеме, где к каждому серверу подключается JBOG-и (Just a bunch of GPUs). Разберём, как устроены стойки в кластере:
— Четырёхюнитный JBOG c x8 NVIDIA А100-80G, x6 NVSwitch, 4x Mellanox ConnectX-6 IB HDR 200G. Размер обусловлен встроенной системой охлаждения.
— Сервер половинной ширины 2x AMD 7702, 1024GB RAM на два юнита. В нём находится пятая сетевая карта Mellanox ConnectX-6 100G Ethernet.
— Сетевые карты IB HDR JBOG-ов скоммутированы оптическими кабелями в Infiniband через патч-панель в середине стойки. Они связывают GPU для вычислений.
— Серверные сетевые карты 100GE обеспечивают связность кластера и доступ к хранилищам данных.
— В каждой стойке по три комплекта оборудования. Это продиктовано энергопотреблением — до 20 кВт.
(Кстати, такие же NVIDIA А100-80G мы сейчас открываем для клиентов Yandex.Cloud, но об этом поговорим в другой раз.)

Обратите внимание на отсутствие любых декоративных пластиковых элементов. Зато есть много свободного места, чтобы воздух мог обдувать огромные радиаторы GPU в центре, именно за счёт этого получается экономить электричество на охлаждении.
В кластере 199 серверов с GPU — такое количество обусловлено экономической целесообразностью сборки ядра Infiniband по стандартной схеме на 800 портов с использованием 40-портовых 1U HDR-коммутаторов. Двухсотый сервер не имеет GPU в своем составе и используется для управления сетью Infiniband.
Легко заметить: в отличие от стандартной DGX-A100 от NVIDIA со схемой 8(1-GPU + 1-IB_NIC), мы построили своё решение по схеме 4(2-GPU + 1-IB_NIC). Это позволило создавать кластеры в два раза большего размера по сравнению с коробочным решением SuperPod. Дело в том, что NVIDIA SuperPod — это решение общего назначения, которое решает любые задачи одинаково хорошо. А мы оптимизировали наши кластеры под решение именно наших задач и показали, что сети 768 Гбит/с на хост вполне достаточно. Например, вот так выглядят типичные итерации обучения.
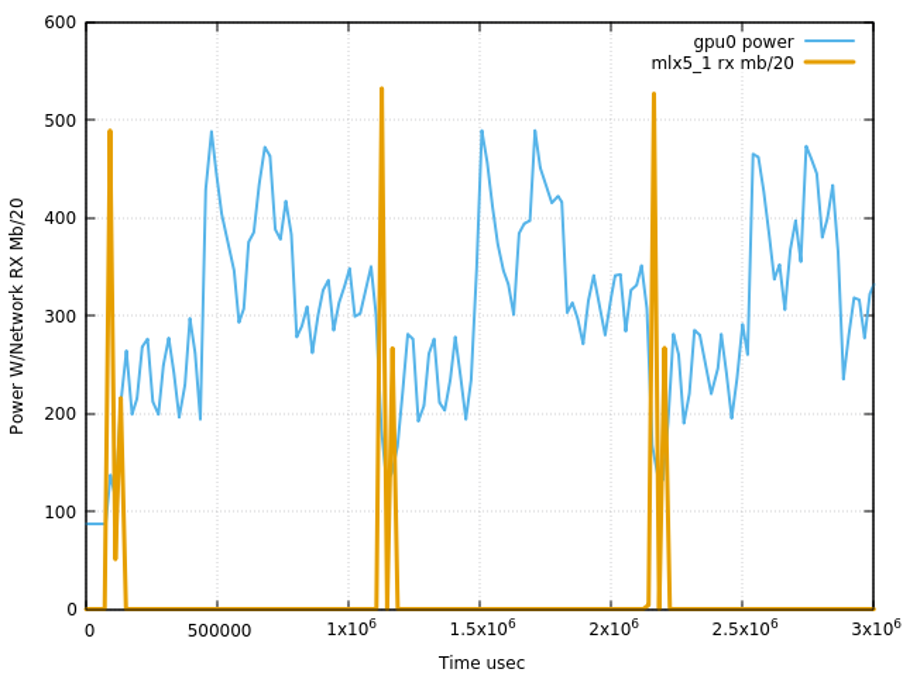
Видно, что на фазу обмена по сети тратится совсем мало времени, поэтому дальнейшее расширение интерконнекта не целесообразно.
Первый подход к замерам
Вскоре после запуска новых кластеров у нас появилось немного времени, чтобы позволить себе прогнать стандартный тест и зарегистрировать кластеры в рейтинге Top500. Казалось бы, что могло пойти не так?
Официальным тестом Top500 является HPL — High Performance Linpack. Это распределённый алгоритм решения системы линейных уравнений. Первые попытки прогона linpack’а показали, что всё очень плохо, и даже на одном хосте результат в десять раз ниже ожидаемого. Мы что-то явно делали не так. Решили посоветоваться с коллегами из NVIDIA. Выяснилось, что, по их мнению, linpack — один из лучших интеграционных тестов для GPU-кластера и если он не показывает нужный результат, значит, это проблема и, скорее всего, продуктовое обучение ML-моделей тоже будет страдать. Начали копать. И началось…
Дальше я опишу примеры проблем, с которыми мы столкнулись, на сугубо техническом языке, чтобы мои коллеги по индустрии могли извлечь из нашего опыта максимум пользы. Но если вам интересен только финал истории, то смело переходите к разделу с результатами замеров.
Также, по нашим замерам, hpcx-v2.9.0 работает чуть хуже hpcx-v2.8.1 (разница — около 1%).
Периодически находились отдельные GPU, которые перегревались и снижали собственную частоту. При этом проверочные нагрузочные тесты этого не ловили: их задача — убедиться, что GPU выдерживает максимальную нагрузку. А вот теста на перегрев не было, и Linpack оказался отличным способом искать такие проблемы. Наши инженеры проверяли систему охлаждения, и всё налаживалось.
К локальному перегреву случайных GPU приводил рваный темп их работы. Наши дата-центры охлаждаются атмосферным воздухом, а в это время на улице стояла страшная июльская жара. Как тогда выяснили, запуск linpack приводил к повышению температуры в ДЦ на 2 градуса. Пришлось запускать замеры по ночам, с 2 до 5 часов утра. Но проблема перегрева была лишь следствием рваного темпа работы GPU, который, в свою очередь, был вызван проблемами в интерконнекте Infiniband. Мы починили это, перенастроив PID controller охлаждения в JBOG.
— Как выяснилось, мы прокидывали не все нужные устройства внутрь контейнера, из-за чего тест не падал, но работал неоптимально. Всегда начинайте тестирование со сравнения bare metal vs container.
— Высокий рейт отказов нового железа приводил к тому, что при обнаружении проблемы на хосте автоматика пересоздавала контейнеры с нуля. Это очень сильно осложняло отладку. На сыром нестабильном железе использование средств автоматизации скорее вредит.
— Порядок созданных контейнеров всегда был случайным. Но, как выяснилось позже, порядок хостов имеет значение, поэтому любой детерминизм сильно упрощает поиск проблем. Если есть проблема, фиксируйте всё, что можно, даже если это кажется малозначительным.
В результате на этапе отладки пришлось отказаться от автоматизации создания контейнеров и создавать всё shell-скриптом с явной привязкой по хостам. Дальше действовали итеративно:
1. запускаем linpack на каждом хосте, отсеиваем все хосты с плохими результатами, вызванными проблемами в железе;
2. объединяем хосты в пары и прогоняем тест для всех пар, должны получить результат x2;
3. повторяем шаг 2, сливая две группы хостов в одну, и проводим замер.
Когда у нас было 4 группы по 32 хоста, выяснился любопытный эффект: объединение двух групп, g1 и g2, давало ожидаемое линейное масштабирование, а при объединении g3 и g4 получался перфоманс на уровне g3 или g2 по отдельности. После этого стало понятно, что проблема не в отдельных хостах, а где-то в районе Infiniband-сети.

Мы сообщили о проблеме в Mellanox и попутно выяснили: в адаптивном роутинге существуют «прóклятые маршруты», по которым данные передаются в тысячу раз медленнее, чем должны. Это сразу объяснило причину нестабильности работы linpack’а. Но что делать, было совершенно непонятно. Коллеги из Mellanox ушли думать, а мы на свой страх и риск обновили FW на свичах и карточках на самую свежую версию от Mellanox, и проблема исчезла. Версии прошивок с фиксами: FW-HCA — 20.30.1004, FW_SWITCH — 27.2008.2500. Мораль: Infiniband, как и любая сложная система, требует внимания. Нужно явно тестировать все маршруты на фабрике, чтобы убедиться в её полной работоспособности.
Замеры
После успешного решения этих и других проблем мы наконец-то получили заветное линейное масштабирование на 152 хостах, доступных на тот момент. Получилось 15,2 петафлопса. Но была одна проблема: пока мы настраивали кластер, закрылось окно подачи в июньский рейтинг. Мы опоздали буквально на одну неделю. Поэтому решили взять паузу с замерами linpack до осени. За это время мы внедрили все найденные оптимизации на новых кластерах и отдали их пользователям — разработчикам и инженерам внутри компании. Кластер «Ляпунов» решили пока не выводить на обслуживание, потому что он в два раза меньше и у нас не было уверенности, что в нём проявится баг с адаптивным роутингом. Обслуживание означало задержку в расчётах критически важных ML-обучений. Поэтому тоже решили отложить до осени.
Первый замер
8 октября мы провели первый замер всех трёх кластеров. ML-инженеры согласились отдать кластеры всего на несколько часов: за это время нужно было сделать несколько прогонов, чтобы подобрать оптимальные параметры. Вот какие результаты у нас получились:
— Кластер «Червоненкис» (SAS-GPUIB2), 196 узла — 21,52 петафлопса,
— Кластер «Галушкин» (VLA-GPUIB3), 104 узла — 11,5 петафлопса
— Кластер «Ляпунов» (SAS-GPUIB1), 134 узла — 9,46 петафлопса
Результаты хорошие, но «Ляпунов» явно не дотягивал до ожидаемых значений. Стало очевидно, что проблема с адаптивным роутингом влияет на него больше, чем мы полагали. Дальнейшие разбирательства показали, что потери производительности на «Ляпунове» проявлялись уже на масштабе 8 хостов, а на масштабе всего кластера составляли около 30%. Мы решили выводить кластер на обслуживание как можно раньше.
Второй замер
19 октября «Ляпунов» был успешно обновлён. Теперь самое интересное. Сравните результаты:
— Было 9,46 петафлопса
— Стало 12,81 петафлопса
Итого рост +35% к масштабируемости всего кластера. Это очень круто. В реальности с обучением ML-моделей на масштабах 8-24 хостов мы ожидаем получить приращение 10-15%.
В процессе второго замера обратили внимание, что график сети продолжает быть нестабильным. Как выяснилось, проблема в эффекте резонанса мониторинговых сервисов. У нас есть несколько таких сервисов, которые периодически опрашивали состояние GPU через утилиту nvidia-smi, что на больших запусках приводило к деградации в 2-4%. Мораль: опрос перфоманс-метрик в драйвере NVIDIA не бесплатный, не нужно проводить его слишком часто.
Третий замер
Буквально на прошлой неделе мы закончили монтаж новых стоек — число узлов в кластере «Галушкин» должно увеличиться со 104 до 195. Очень хотелось успеть обновить результат до закрытия окна подачи в Top500, то есть до 7 ноября. Но к этому моменту мы успели подключить и проверить только 136 узлов. Зато у нас уже было гораздо больше опыта, и мы починили проблему с излишним влиянием мониторингов. Поэтому результат получился очень хороший: 16,02 петафлопса. В сумме по трём кластерам вышло 50,3 петафлопса. В ближайшее время нужно проверить оставшиеся узлы. Нам ещё есть над чем работать, но это уже другая история.
Чему мы научились
Мы строили свои кластеры для решения реальных задач машинного обучения, руководствуясь имеющимся опытом (в серверах, сетях, средах окружения и так далее). Linpack мы рассматривали как незначительную вспомогательную задачу. В результате мы поняли, что строить и валидировать такие системы — совершенно новый и полезный опыт для нас. Также оказалось, что linpack — отличный инструмент интеграционного тестирования. Он позволил найти и починить сразу несколько багов в продакшене, которые мы раньше просто не замечали.
Возникает вопрос: почему именно linpack оказался настолько хорошим инструментом? Чтобы ответить, нужно посмотреть на график обмена данными за 1 секунду.

Видно, что за секунду он успевает сделать 4,5 синхронных итерации — это в 2-4 раза чаще, чем наши реальные обучения. Именно поэтому linpack гораздо чувствительнее к различным задержкам на узлах. Например, альтернативный тест HPCG показал себя намного хуже: он не загоняет GPU в критические температурные режимы и использует лишь 10% сети.
Итоги
Построение и эксплуатация суперкомпьютеров — интересная, но сложная задача. Экспертизы очень сильно не хватает: абсолютное большинство компаний не собирают свои суперкомпьютеры. В то же время учиться на собственных ошибках — дорогое удовольствие: простой кластера стоит десятки тысяч долларов в сутки. Поэтому для нас обмен опытом — критически важная вещь. Она экономит время и деньги всем, кто двигает индустрию вперёд. Если у вас есть опыт или идеи в области HPC/GPU, не держите их в себе, делитесь. Буду рад вашим комментариям. Со своей стороны постараюсь вскоре вернуться с новой историей, на этот раз посвящённой проблемам, c которыми столкнулись наши ML-инженеры при использовании кластера.


