
Привет! Это снова я 🙂
Первая статья из цикла “Скандальное разоблачение x86: ARM врывается с двух ног” получила отклик больше, чем я ожидал: 155+ комментариев и 55 плюсов. Спасибо всем за активное обсуждение — в комментариях получился холивар с кучей интересных мыслей по сабжу.
В конце той статьи я сделал голосование, чтобы узнать, ждут ли читатели Хабра продолжения?
-
66.6% (600+ голосов) ответили “да”
-
26% отметили, что они — человеки-пауки 😀
-
7.3% не хотят
В общем, спрос адский (не удержался от каламбура), а поэтому пришло время для второй части. Кстати, в конце будет новое голосование 🙂

Содержание:
Итак, это вторая статья из цикла про ARM-архитектуру. В первой я рассказал про ключевые различия x86 и ARM (на мой субъективный взгляд), а также разобрал, как британской компании удалось за 12 лет преодолеть 200-кратное отставание и не только догнать топовые модели Intel и AMD, но в чём-то и превзойти их.
В этой статье я расскажу про серверы и ARM-процессоры для них, а также пару слов про суперкомпьютеры. Обсудим, зачем бизнес вообще смотрит в сторону ARM. Так что заваривайте чаи и дошираки, пристёгивайтесь — и начнём.
ARM в серверах? Not bat.
")
Calxeda — компания-первопроходец в этом нелегком деле. Хвала безумцам. Бунтарям. Смутьянам. Неудачникам. Тем, кто всегда некстати и невпопад. Тем, кто видит мир иначе.
Они первыми бросили вызов Intel и AMD в серверном сегменте и в далёком 2011 году представили узел Calxeda Quad-Node EnergyCard. Это высокоплотный продукт для облачных вычислений, работающий по принципу “одна ОС на один чип”. У Calxeda получилась “физикализация” — альтернативный взгляд на потребности бизнеса, которые, как правило, закрывает старая добрая виртуализация.

Итак, Calxeda Quad-Node EnergyCard — это:
-
Четыре SoC EnergyCore ECX-1000 — построен на четырёх 32-битных ядрах Cortex-A9 с частотой 1.1-1.4 ГГц, ARMv7-A, 32 КБ L1 I-cache и 32 КБ L1 D-cache на ядро, 4-МБ общей кэш-памяти L2, 4 кэш-когерентных ядра (память доступна всем ядрам);

-
4 DIMM слота для 4 Гб памяти DDR3 с коррекцией ошибок (ECC);
-
Твердотельный накопитель;
-
Контроллеры памяти и интерфейсы I/O (10-Гб и 1-Гб каналы Ethernet, дорожки PCIe и 4 порта SATA на каждый SoC);
-
Энергопотребление в 20 Ватт при 100% нагрузке всех чипов, в простое — меньше.
-
В каждый чип EnergyCore ECX-1000 установлен блок EnergyCore Management Engine для удалённого управления устройством, словно оно находится прямо перед вами. Это аналог связки BMC-IPMI в классических серверах.
|
Здесь нужно небольшое отступление. BMC (Baseboard Management Controller) — это автономная система на кристалле, которую распаивают на материнской плате серверов (почти во всех моделях). Есть даже PCIe IPMI-карты, которые можно подключать к ПК или недорогим серверам, где BMC нет по дефолту. Питается этот SoC от дежурного питания, а потому работает постоянно и не зависит от основной системы, если сервер подключен к розетке. Так вот, BMC-контроллеры построены как раз на архитектуре ARM. При этом у разных производителей — разная реализация. Например: в SoC Aspeed AST2600 от тайваньского вендора есть 3 ядра: основные Cortex A7 и вспомогательное Cortex A3. Этот чип используют другие вендоры без своих разработок (Supermicro, ASUS). А есть проприетарные варианты, про которые я писал отдельные статьи: Dell — iDRAC, HPE — iLO и Lenovo — IMM. Поэтому, даже если основные процессоры вашего сервера построены на x86, в нём всё равно есть компоненты, которые построены на ARM архитектуре. |
Как вы поняли, в недрах Calxeda планировали брать серверный рынок за шкирку не мощью ядер, а их количеством, так как процессор Cortex-A9 не мог напрямую конкурировать с серверными решениями на x86 того времени. Освежу память — в 2011 году это был, например, Intel Xeon E3-1240. То есть Calxeda выбрала совсем другой подход, как, например, в продуктах ныне покойной SeaMicro — сервер высокой плотности на базе маломощных чипов Intel Atom, которые по своей сути были отдельными “серверами”.


Итак, вернёмся к Calxeda Quad-Node EnergyCard.
Компания HP планировала в паре с Calxeda разработать ARM-лезвия HP Redstone для уже существующих модульных шасси HP ProLiant SL6500. Проект назвали Project Moonshot. Каждое лезвие должно было вмещать 18 узлов EnergyCard, а это, на секундочку, 288 чипов EnergyCore ECX-1000 или 1152 ядер. И всё в корпусе 4U.
Да, снова 4 Блейда (ссылка), но в этот раз не под столом, а в стойке. А внутри ещё по 18… Бэтменов, и у каждого на поясе 4 бэтаранга.
Если вы ничего не поняли, то скажу проще: в стандартную стойку 42U должно было уместиться 2880 “серверов”. Эксплуатационные расходы за счёт этого планировали снизить на 63%. Да, это решение для узкого круга задач, но всё равно звучит вкусно, если ты владелец бизнеса или дата-центра.
Но, с сожалению, EnergyCard так и не пошла в релиз, а сделка с HP сорвалась.


По итогу разработки Calxeda не взлетели: $103 миллиона венчурного капитала закончились, новых инвесторов на четвёртом раунде финансирования не нашлось, а в 2013 году компания уволила сотрудников, закрыла офис и свернула деятельность (отрицательно открылась провела реструктуризацию на бизнесменском).
Пожалуй, Calxeda слишком рано двинулась в серверное направление с ARM-решениями, ведь никто не знал, насколько преуспеет ARM в разработках буквально через несколько лет. Да и физикализация — решение сомнительное (спросите у SeaMicro, которая тоже AFK).
Неудачи Calxeda отпугнули многие компании и капиталы, и только в 2016-2017 годах нахлынула вторая волна ARM: появились 64-битные процессоры, способные конкурировать с Intel и AMD. В этот раз решили не изобретать виртуализацию; стали проектировать многоядерные высокопроизводительные чипы общего назначения. То есть потенциальных конкурентов нынешним линейкам Xeon и EPYC.
Ещё через год-другой ситуация перевернулась с ног на голову, а мир увидел: Fujitsu A64FX, HiSilicon Kunpeng, Ampere Altra, Marvell ThunderX и другие чипы. Напомню, что M1 вышел позже — только в ноябре 2020-ого года. Так что, как я и говорил в первой статье, революция произошла раньше — в серверном сегменте.
А теперь поговорим о конкретных ARM процессорах.

1) Fujitsu A64FX — 2019 год

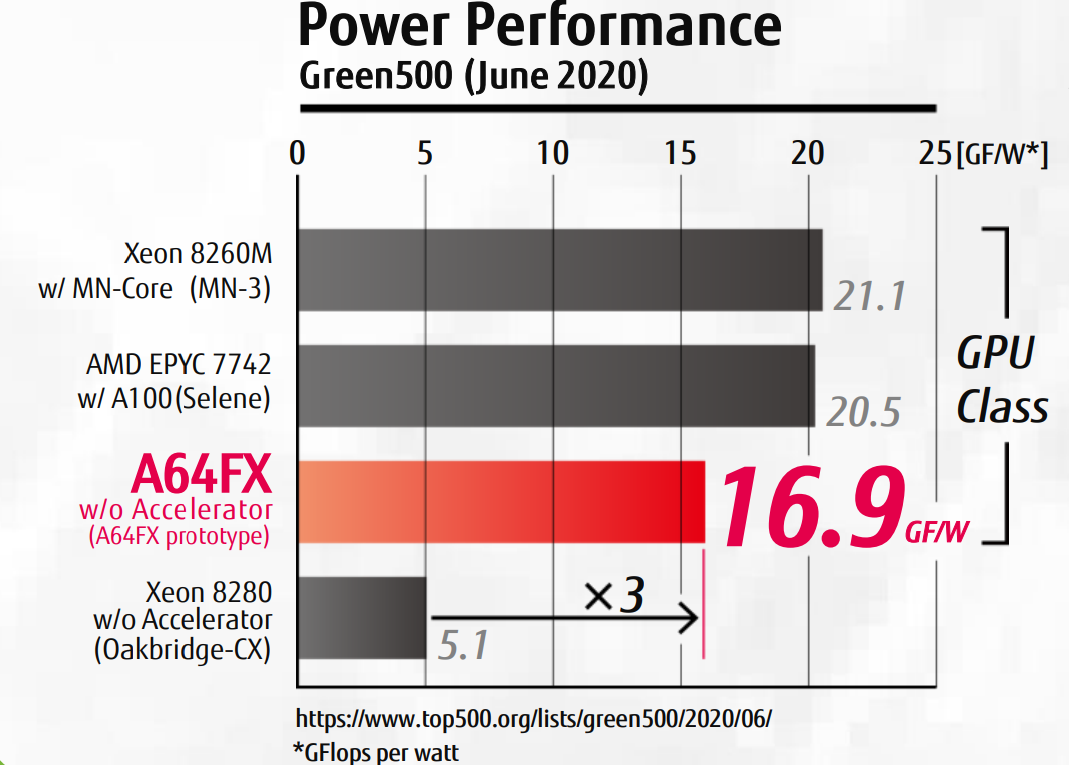
Чип A64FX реализован на архитектуре ARM v8.2A + SVE (Scalable Vector Extension, то есть масштабируемые векторные инструкции). Процессор изначально разрабатывался для суперкомпьютера Fujitsu Фугаку.
Суперкомпьютер на ARM? Почему бы и да.

Суперкомпьютеры — ещё одна ниша, где x86 властвовал годами. Слышали про мировой рейтинг Top500? Первое место с июня 2020 г. по июнь 2022 г. удерживал японский Fujitsu Фугаку. Интересно, что это первый суперкомпьютер с ARM-процессорами, попавший в рейтинг. И сразу вверх списка.
Суперкомпьютер — это не одно гигантское устройство размером с дом, а большой кластер соединённых между собой серверов или мейнфреймов, которые занимаются вычислениями одновременно. Например, в Фугаку установлено 158 976 процессоров Fujitsu A64FX (всё соединено по проприетарной шине Fujitsu Tofu Interconnect) с общей производительностью в 442,01 петафлопс в штатном режиме и более 540 в пике.
Примерно как 170 тысяч SoC Apple M1, 43 тысячи PS5 или 11 тысяч RTX 3090 Ti. Да, я понимаю, что прямые сравнения разных архитектур во флопсах некорректны (“А если слон и вдруг на кита налезет, кто кого сборет?”), но будем считать это жертвой во имя наглядности.
Итак, Fujitsu A64FX — это суперскалярный процессор с внепорядковым исполнением команд. Суперскалярность позволяет выполнять множество команд с низким уровнем зависимостей одновременно, что обеспечивает параллелизм на уровне инструкций (Instruction-level parallelism — ILP).

То, как суперскалярность будет реализована, зависит от аппаратной составляющей и разработчиков софта. Параллелизм особенно актуален при нехватке памяти. Код с небольшими зависимостями инструкций называют кодом с высоким показателем ILP.
1) Совсем не разбираешься в коде? Пролистывай — дальше будет простой пример.
Пример кода с высоким показателем ILP:
for (int i = 0; i < n; i++) {
c[i] = a[i] + b[i];
}Для анализа ILP полезно разворачивать цикл дважды, так как часто встречаются самозависимости инструкций (сама от себя). Если развернуть цикл, то станет нагляднее, так что давайте перепишем цикл в виде псевдоассемблера:
for (int i = 0; i < n; i+=2) {
a_val_1 = load(a + i);
b_val_1 = load(b + i);
c_val_1 = a_val_1 + b_val_1;
store(c + i, c_val_1);
a_val_2 = load(a + i + 1);
b_bal_2 = load(b + i + 1);
c_val_2 = a_val_2 + b_val_2;
store(c + i + 1, c_val_2);
}В каждой итерации есть четыре псевдоинструкции: две load, одна addition и одна store. Если посмотреть на зависимости, то инструкции load(a + i)и load(b + i)могут выполняться независимо. Инструкция a_val + b_val зависит от двух предыдущих, поэтому ей нужно дождаться их завершения. Инструкция store(c + i, c_val)зависит от инструкции a_val + b_val. То есть получилась цепочка зависимостей.
Но если проанализировать несколько итераций, то получим другую картину: в коде нет зависимостей с переносом цикла, то есть данные, необходимые для текущей итерации, не вычисляются в предыдущей итерации. Другими словами, итерации полностью независимы друг от друга. Если CPU обрабатывает итерацию, где i = X, и застрял в ожидании завершения двух загрузок, он может начать выполнение загрузок из итерации, где i = X + 1, i = X + 2и т. д. Код без типичных зависимостей, переносимых циклом, демонстрирует относительно высокий уровень ILP.
2) Элементарный математический пример для наглядности, что такое параллелизм.
X = A – B
Y = C + D
Z = E / K
W = L * M
N = Z^W + X*Y
Чтобы рассчитать N, нужно узнать значение X, Y, Z и W. Предположим, что на каждую операцию уходит 1 мс. Если выполнять расчёты последовательно, то совокупно уйдёт 5 мс. Но так как значения X, Y, Z и W не зависят друг от друга, их можно рассчитать параллельно за 1 мс. То есть на всю операцию уйдёт 2 мс, вместо 5.
Получаем параллелизм, равный 5/2.
A64FX не устанавливают в смартфоны, планшеты или ПК, так как область применения совершенно другая — массово-параллельные и высокопроизводительные вычисления (HPC) в дата-центрах. Так, процессор можно встретить только в суперкомпьютерах или в серверах — например, HPE Apollo 80 System.
Он работает с 64-разрядными командами ARM и векторными инструкциями длиной до 512 бит. Под крышкой 48 высокопроизводительных и 2-4 вспомогательных ядра с частотой до 2.2 ГГц.
Одна из важнейших особенностей: 4 блока памяти HBM2 — по 8 Гбайт каждый, что в сумме даёт 32 Гбайта с пропускной способностью в 1 ТБ/с. Де-факто это кэш L3, так как внутренние шины в процессоре достаточно быстрые.
↓Технические характеристики процессора Fujitsu A64FX↓
|
ISA (архитектура набора команд) |
ARMv8.2-A + SVE |
|
|
Количество процессорных ядер |
48 вычислительных ядер, и 2 или 4 ядра вспомогательных |
|
|
Потоки |
48 |
|
|
Базовая частота (турбо-частоты нет) |
1,8 ГГц, 2,0 ГГц, 2,2 ГГц |
|
|
SIMD Width |
512 бит |
|
|
Размер кэша L1I |
3 Мбайт (64 кбайт / ядро) |
|
|
Размер кэша L1D |
3 Мбайт (64 Кбайт /ядро) |
|
|
Размер кэша L2 |
32 Мбайт (8 Мбайт x 4) |
|
|
Размер кэш-линии |
256 байт |
|
|
Контроллер памяти |
4 |
|
|
SVE-реализованная длина вектора |
128 / 256 / 512 бит |
|
|
Peak Flops; D / S / H [FLOPS] |
1,8 ГГц |
2,7648 / 5,5296 / 11,0592 TFLOPS |
|
2,0 ГГц |
3,072 / 6,144 / 12,288 TFLOPS |
|
|
2,2 ГГц |
3,3792 / 6,7584 / 13,5168 TFLOPS |
|
|
Peak Int Ops; 8 / 4 / 2 / 1B [OPS] |
1,8 ГГц |
2,7648 / 5,5296 / 11,0592 / 22,1184 TOPS |
|
2,0 ГГц |
3,072T/ 6,144 / 12,288 / 24.576 TOPS |
|
|
2,2 ГГц |
3,3792 / 6,7584 / 13,5168 / 27.0336 TOPS |
|
|
Сеть |
Tofu interconnect D [68 ГБ/с x2 (вход/выход)] (Только если частота составляет 2,2 ГГц) |
|
|
IO / Socket |
PCIe Gen3 16 полос [15.75GB/s (in/out)] (Необходимы чипсеты для USB/SATA) |
|
|
Технологический процесс |
7 нм CMOS FinFET |
|
|
Количество транзисторов |
8 786 000 000 |
|
2) Huawei Kunpeng 920 — 2019 год

Чип Kunpeng 920 разработан компанией Huawei (подразделение HiSilicon) на серверной архитектуре TaiShan v110 (собственное ядро), в основе которой лежат инструкции ARMv8.2-A. Китайцы собирались развивать линейку Kunpeng и дальше, но после санкций США новостей не слышно. Хотя после окологолливудской истории с ARM China есть все шансы на возвращение Kunpeng в строй — это вам спойлер на третью статью из цикла 🙂
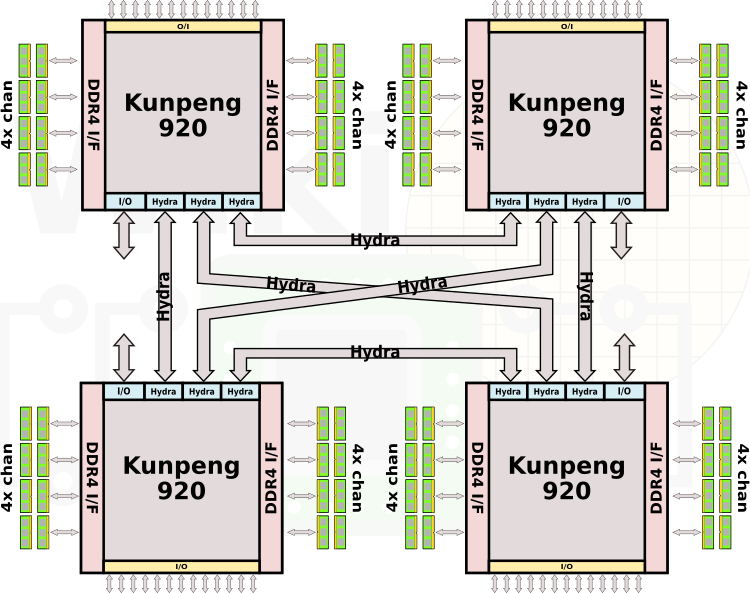
Итак, перед нами высокопроизводительный ARM процессор для серверов TaiShan. На момент выхода в 2019 году Huawei заявляла, что это мощнейшие ARM процессоры в мире. Всего есть пять модификаций: самая простая — 24 ядра; две по 32 ядра, одна на 48 и самая мощная на 64 ядра.
При этом 3 линии шины Hydra (30 ГТ/с, 240 Гбит/с) позволяют создавать двух и четырехсокетные комбинации без потерь, словно это MCM (multi-chip module или многочиповый модуль). Вообще масштабируемость — это фишка ARM процессоров. Kunpeng 920-6426 распаивают на плате по принципу BGA (Ball Grid Array), то есть замена процессора возможна только вместе с материнской платой.
Впечатляет и TDP — 195 Ватт. Это, конечно, меньше, чем у топового Intel Xeon Platinum 8380 (270 Ватт) и EPYC 7773X (280 Ватт), но для ARM очень нескромно.
↓Технические характеристики процессора Kunpeng 920-6426↓
|
ISA (архитектура набора команд) |
ARMv8.2 |
|
|
Количество процессорных ядер |
64 ядер |
|
|
Базовая частота (турбо-частоты нет) |
2,4-3.0 ГГц |
|
|
Размер кэша L1 |
8 Мбайт |
|
|
Размер кэша L1I |
4 Мбайт |
|
|
Размер кэша L1D |
4 Мбайт |
|
|
Размер кэша L2 |
32 Мбайт |
|
|
Размер кэша L3 |
64 Мбайт |
|
|
Память |
До 2 ТБ, поддержка ECC, DDR4-2933 |
|
|
IO |
PCIe 4.0, CCIX, 100G, SAS/SATA 3.0 |
|
|
Технологический процесс |
7 нм |
|
|
Количество транзисторов |
20 000 000 000 |
|
|
TDP |
195 Ватт |
|
3) Ampere Altra Max — 2021 год

SoC Ampere Altra Max разработан на архитектуре ARMv8.2-A+. Это один из самых высокопроизводительных ARM серверных процессоров на сегодня. Его разработкой занималась компания Ampere Computing, которую в 2018 году основала бывший президент Intel — Рене Джеймс.

Итак, у Altra Max отличная масштабируемость, энергоэффективность и производительность на Вт. Подходит для большинства задач: аналитика данных, ИИ, медиакодирование, веб-сервисы, базы данных, хостинг, стриминг, HPC и многое другое.
Всего 128 ядер с частотой 3.0 ГГц, большой объем кэша, PCIe 4.0, EСС-память и какой-то невероятный для ARM процессоров TDP в 250 Ватт. Это ещё раз доказывает, что для большой производительности приходится жертвовать нагревом, и одна лишь архитектура здесь не спасёт.
↓Технические характеристики процессора ARM Ampere Altra Max↓
|
ISA (архитектура набора команд) |
ARMv8.2+ |
|
|
Количество процессорных ядер |
128 ядер |
|
|
Базовая частота (турбо-частоты нет) |
3.0 ГГц |
|
|
Размер кэша L1I |
8 Мбайт |
|
|
Размер кэша L1D |
8 Мбайт |
|
|
Размер кэша L2 |
128 Мбайт |
|
|
SLC (System Level Cache) |
16 Мбайт |
|
|
SIMD Width |
2x full-width 128 бит |
|
|
Память |
До 4 ТБ, поддержка ECC, DDR4-3200 |
|
|
IO |
• 128 lanes of PCIe Gen4 – 4 x16 PCIe + 4 x16 PCIe/CCIX with Extended Speed Mode (ESM) support for data transfers at 20/25 GT/s – 32 controllers to support up to 32 x4 links • 128 PCIe lanes in 1P configuration • 192 PCIe lanes in 2P configuration • Coherent multi-socket support • 4 x16 CCIX lanes |
|
|
Технологический процесс |
TSMC 7 нм FinFET |
|
|
TDP |
250 Ватт |
|
Но самое главное, что Altra Max — это не прототип-вундервафля, а вполне себе работающий чип, который можно найти, например, у HPE в модели ProLiant RL300 Gen11. Да, купить его в России официально не получится (если ничего не изменится в ближайшем будущем), но параллельный импорт нас спасёт. Надеюсь.
4) AWS Graviton3 — 2021 год

Другой интересный чип — это Graviton3 от Amazon. На нём работают инстансы EC2 C7g и соответсвенно дата-центры AWS (Amazon Web Services).

Здесь всё по высшему разряду: 5нм, 50 миллиардов транзисторов, 64 ядра, 2.6 ГГц, пропускная способность до 300 ГБ/c, DDR5, новейшая ARM архитектура «Perseus» Neoverse N2. Чтобы снизить себестоимость, чип распаивают на плате по принципу BGA (Ball Grid Array), как и Kunpeng 920 от Huawei.
Интересно, что в Graviton3 не заоблачное количество ядер, но их производительность очень хороша — за один такт обрабатывается до 15 инструкций (благодаря декодированию 5-8).
Инстансы C7g, как утверждает Amazon (а плохого о себе они точно не скажут), идеально подходят для высокопроизводительных вычислений (HPC), пакетной обработки, автоматизации проектирования электроники (EDA), игр, кодирования видео, научного моделирования, распределенной аналитики, выводов машинного обучения (ML) на базе процессора и рекламы. Они дают до 25% прироста производительности по сравнению с предыдущим поколением — C6g на AWS Graviton2.
↓Технические характеристики процессора AWS Graviton3↓
|
ISA (архитектура набора команд) |
ARMv8.5 |
|
|
Количество процессорных ядер |
64 ядер |
|
|
Базовая частота (турбо-частоты нет) |
2.6 ГГц |
|
|
Размер кэша L1 total |
8 Мбайт |
|
|
Размер кэша L2 total |
64 Мбайт |
|
|
Размер кэша L2 total |
64 Мбайт |
|
|
Пропускная способность памяти |
307,2 ГБ/c |
|
|
Память |
До 4 ТБ, поддержка ECC, DDR5-4800 |
|
|
IO |
32 линии PCIe Gen5 |
|
|
Технологический процесс |
TSMC 5 нм |
|
|
TDP |
100 Ватт |
|
Подведу небольшой итог по серверным процессорам на ARM
Модели выше — далеко не единственные, есть Marvell ThunderX3 (Arm v8.3+, 96 ядер с поддержкой 4 потоков на каждое), Yitian от Alibaba Cloud (про него хоть отдельную статью пиши, монстр на ARMv9) и другие. Для всех характеры современные технологические процессы в производстве (7 нм, 5 нм), большая плотность ядер, относительно низкое энергопотребление. Да, пиковая производительность у Intel и AMD всё ещё выше, но соотношение производительность/стоимость на Ватт у ARM-процессоров вне конкуренции.
А теперь вспомните x86. Большой ли там выбор? Много ли вендоров? Серверы Dell, HPE и других крупных вендоров до сих пор топчутся на DDR4 и PCIe 4.0 — там эти технологии появились совсем недавно, в последнем поколении.
Не знаю, как у вас, но у меня напрашивается банальная фраза: “конкуренция — двигатель прогресса”.
Но есть обратная сторона конкуренции — в консьюмерском ПК сегменте только Apple зарабатывает деньги на ARM чипах, и где-то поодаль плетётся Qualcomm.
Apple сделали хороший консьюмерский чип, который удачно интегрировали в свои продукты из-за проприетарного софта и оптимизированного транслятора Rosetta 2. Но как я и говорил, революцию Apple не совершала, а до выхода M1 уже были высокопроизводительные чипы на ARM, которые показывали себя в серверном сегменте:
-
Fujitsu A64FX — 2019 год;
-
Kunpeng 920 — 2019;
-
ARM Ampere Altra Max — 2020;
-
Apple silicon M1 — конец 2020.
Ну а будущее будет интересным. Huawei, вероятно, вернётся в серверный сегмент со своими HiSilicon процессорами. Нет, санкции никто не снимет, скорее наоборот — ужмут ещё сильнее. Вот только ARM China теперь самостоятельная компания, а в портфеле у неё все наработки ARM. Но этот китайский рэкет заслуживает отдельного материала.
Если вкратце, то мысли такие: в будущем это может привести к расколу на “америкоцентрическую” и “китаецентрическую” модели развития микроэлектроники. Особенно в условиях нынешней геополитики.
Какие преимущества в серверном сегменте у ARM для бизнеса

Начнём с того, что архитектура набора команд (ISA) обеих архитектур постоянно дорабатывается и обновляется. Например, iPhone 5 работал на Apple A6 с архитектурой ARMv7s (32-bit), а следующий iPhone 5S на ARMv8.0-A (64-bit). Актуальный ныне Apple A15 построен на ARMv8.5-A.
Начиная с ARMv8 был сделан архитектурный шаг в сторону ПК и серверов.
Многие актуальные на 2022 год серверные чипы построены на ISA версии ARMv8.2 и старше. В лагере x86 также есть поколения и расширения:
-
IA-32 (Intel Architecture, 32-bit);
-
IA-64 (сейчас официально называется Intel64);
-
x86-64 (разработка AMD в 2000 году, на которой и основана Intel64, называлась именно так);
-
AMD64 (название в рядах AMD после появления оригинального ядра Athlon 64 под рабочим именем “Clawhammer”).
Но здесь важно не только привнести новое, но и сохранить поддержку старого.
В комментариях к первой статье мне писали: “x86 — это ещё и громадная legacy-архитектура из большого количества древних команд, которые тянут ради совместимости с прошлыми версиями. Мне кажется, что именно это сейчас является одним из основных препятствий для развития данной архитектуры”.
Objection!
Сам тезис в первом предложении верен, но ARM также своего рода энциклопедия функций. ARM делит процессорные ядра на классы, которые включают в себя базовый и расширенный функционал, а также узкоспециализированные функции. Компания, покупающая лицензию, создаёт свой дизайн на основе нужных ядер — Applications, Real-time, Microcontroller (A.R.M):
-
Cortex-A, а также Cortex-X (слегка улучшенная версия Cortex-A);
-
Cortex-R;
-
Cortex-M.
Далее ARM сертифицирует разработанный сторонней компанией дизайн, чтобы убедиться, что он соответствует всем принципам работы, безопасности и совместимости. Если ПО создано для ARMv8, то оно должно работать на всех чипах этого поколения, иначе ARM не пропустит дизайн. Такие дела.
А самое интересное, что новая ARMv9 (на ней уже спроектирован чип от Alibaba Cloud) обратно совместима с ARMv8. Так что унаследованные системы — это бич не только x86. Но да, ARM-архитектура только раскручивается, поэтому legacy-хвост у неё не такой длинный.
Мы живём в мире фрагментированных платформ: в комментариях к первой статье это подтвердили хабровчане, которые до сих пор используют неподдерживаемые смартфоны и планшеты.
Но вас, наверное, интересует, какой вообще смысл бизнесу переходить с привычного на что-то новое. Давайте разбираться.
Во-первых, ARM дешевле

Ampere Altra Max M128-30 (128-ядерный процессор) отпускают по цене в $5800. Напомню, что 40-ядерный Intel Xeon Platinum 8380 и 64-ядерный AMD EPYC 7773X стоят приблизительно $8000-8600.
При этом ничто не мешает компании разработать собственный дизайн чипа и заказать производство на мощностях TSMC, как это делает Amazon или Alibaba. Со временем, когда вложенные в исследования средства окупятся, такой подход становится ещё дешевле, чем покупать готовый продукт у других вендоров. Плюс можно лучше оптимизировать связку железо-софт и создавать более узкоспециализированные продукты.
Во-вторых, на ARM больше ядер на сокет

Да, ядра в том же Ampere Altra Max M128-30 не такие производительные, как в Intel Xeon Platinum 8380 (хотя вопрос в задачах), но достаточно компактные, чтобы разместить 128 ядер на сокет. К слову, у AMD в семействе EPYC на 2023 год анонсированы процессоры Bergamo со 128 ядерами. Вот только TDP будет 320 Вт, а цена — страшно представить.
Ну и не забываем, что ARM-чипы тоже буду прогрессировать и увеличивать плотность ядер на сокет, пока это позволяет техпроцесс. Впрочем, уже прорабатываются идеи, как прогрессировать после преодоления планки в 1 нм — ASML и imec включили это в свою дорожную карту, поэтому мутировавший закон Мура не умрёт в ближайшем будущем.
В третьих, у ARM лучше показатели производительность/cтоимость на Вт

Та же Ampere Computing даёт примерно 20-процентное преимущество в цене/производительности, если сравнивать с прямыми конкурентами от Intel и AMD. Так что на рынке поставщиков облачных услуг у архитектуры x86 серьёзная конкуренция прямо сейчас.
Всё это позволяет поставщикам облачных услуг, которые перешли на ARM, демпинговать. Например, ядро ARM общего назначения в серверах Ampere на базе Altra Oracle стоит около цента в час, что составляет 30,72 доллара за два 128-ядерных процессора в день. Цена за ядро — вот где ARM-архитектура раскрывается на полную.
Выводы + ещё одно голосование

У x86 большие проблемы. Если тенденция не изменится, то есть шанс, что привычные нам процессоры Intel и AMD станут нишевыми. Может, на это уйдут десятки лет, а может, я просто преувеличиваю, и у x86 ещё есть тузы в рукаве. Время всё расставит на свои полочки, но векторы развития, как мне кажется, очевидны.
Спасибо, что прочитали статью. Если вам есть что добавить, или я где-то ошибся — комментарии всегда открыты 🙂

