[Feature]: Option to divide snaphu unwrapping into tiles #478
Comments
|
From my understanding of what SNAPHU does, it has to be a global solution (optimization problem). The tile mode seems to be dividing the interferogram and unwrap with some overlap. It may not affect unwrapping when images are with good quality, but may be problematic when lots of residues are on the boarder. I am not sure whether it'll work perfectly and this'll require lots of testing. |
If this gets implemented in GMTSAR I will definitely run some comparisons soon considering I'm overpaying for unused resources at the moment. |
|
Looks sort of OK but with 2x2 tiles. However it's not even reducing the time by a factor of two. (11min vs 6min) Could be problem size related.
|

I would still consider that a significant improvement considering I've been unwrapping for a week now. Could be the difference between 11 and 6 days (!) |
|
The script I sent have some parameters built inside. It requires some customization to run properly for a targeted problem. |
It works fine and much faster when we have enough tiles overlapping (ROWOVRLP and COLOVRLP). 400 pixel is the recommended overlapping but for faster processing 200 pixel overcalling works for many cases (the command below targeted for Google Colab environment): I think the main reasons to use tiling unwrapping are RAM management and the speedup. We can use all the 8 cores together for multiple tiling unwrapping processes on Apple iMac 16GB RAM and have the results ~10-100 times faster depending of the area. See the live example on Google Colab: |
|
Official support for this would be a huge improvement for both low end and high end systems. Low ram? Divide by more tiles. |
Yes, that's correct. SNAPHU memory management is straightforward and operates the full amount of the required memory always and that's costly everywhere. Split the entire image to N tiles and N CPU cores and you need to manage less then 1/N of the full memory. Try it on no-swap system like to Docker container and you will see the source of the problem: https://hub.docker.com/repository/docker/mobigroup/pygmtsar |
|
@mobigroup Where did you get the information about recommended 400 overlap? For Stamps I usually used 200 / 50 overlap in azimuth / range respectively. If there is a recommended 400 pixel overlap, then it would be important to know if the user is dividing into too many tiles for a given AOI. Small AOI might not have enough pixels to properly divide into N tiles. This could be done by finding the XY extents and ajusting |
|
@SteffanDavies As I remember SNAPHU shows it as warning when you use smaller overlap. By my experience this value is really robust but costly and we often can use 200 or even 100 pixel overlap with some small visible issues. |
|
@SteffanDavies We don't need tiling for small AOI of course. As you maybe remember I shared for you example PyGMTSAR notebooks for ~800 interferograms stack where tiling is really helpful for the grids like to below (cropped using pins) and ~3x larger without pinning: Without tiling you shouldn't expect to process all the data in one day on Apple Air :) |
|
@mobigroup I see. Maybe GMTSAR could default to 400 if no value is specified. Even at 400 it would still be a massive improvement for very large AOI (currently I'm working with 20.000 x 10.000) if divided into for ex. 4 rows 4 cols. |
|
@SteffanDavies I think that's bad assumption for everyone! SNAPHU tiling is valuable for well-selected tiles only. For many cases when decimation used or just a single sub swath processed or pinned subswaths processed SNAPHU tiling can produce weird artifacts and sometimes it works slowly. |
|
@SteffanDavies Also, we need to define the number of CPU cores for the tile-based processing and that's tricky for parallel unwrapping. Do you prefer on 8 core CPU host to have 4 unwrapping processed for 2 threads each or vice versa maybe?.. I use 4 and 4 sometimes (16 cores required in total but there is a trick) because it's much faster :) |
Maximum number of available cores can be obtained by:
If |
|
@SteffanDavies But how are you going to define SNAPHU NPROC parameter the best for all possible cases? The RAM consumption and CPU cores loading should be accounted to do it for the actual case. |
Shouldn't this be up to the user, considering it is entirely optional? It is already possible to run out of RAM using too many CPU in |
|
@SteffanDavies In my example notebooks I define these parameters separately for the each case and with lots of notes for user. The target is the configuration all all your CPU cores are busy and your RAM amount is sufficient. I'm sure you can't do it for every case automatically because it depends of CPU cores count and RAM amount the CPU speed and the RAM speed and the processing grids size and even the actual area! When our area is masked for some tiles unwrapping is fast and we can use more processing threads than we have CPU cores. |
This could be a case of premature optimization. Having the option to do it is better than not having a solution to all cases. User discretion is always advised. |
|
@SteffanDavies Unwrapping without tiling is the solution for most cases :) When you need to process the 20.000 x 10.000 grid you need to know more than you just processing a single-subswath with decimation. You are optimizing your own case which is outside of scope of use GMTSAR for most of users. For tiling unwrapping on slow HDD or on Google Colab user will really curse you because it works too SLOWWWWWWW always. In PyGMTSAR I just provide for user the easy interface to define any SNAPHU parameter plus some example configurations. |
|
@SteffanDavies "As I only have 250 GB of RAM" - that's equal to from 16 to 32 common user computers. Please do not optimise GMTSAR to use "only on 250 GB RAM" because it will be useless software! |
This is why by default there should be no tiling. That's fine. Only tile when user specifies.
Optional arguments are there for specific cases and users. There is little consequence in adding the feature but huge benefit for some cases.
This is the correct approach. Like you said, most users will not use tiles, but for the ones that need it, it is there. Should be the same for standard GMTSAR. It looks like you are assuming I want to force tiling on most users, why?? |
|
@SteffanDavies Please understand me correct - that's much more easy to adjust the SNAPHU calls in GMTSAR shell scripts than select the right tiling configuration for a real case. That's not a problem to use tiling but that's the problem to use tiling correct. |
|
@SteffanDavies One more point - how are you going to define other SNAPHU parameters like to tile processing directory? It'd be on RAM drive for your case or on other disk maybe. For tiling unwrapping SNAPHU shows some suggestions and even requirements - and you need to tune some additional parameters before you will be able to start the processing. So you need to show these SNAPHU output lines (how do you define them and how are you going to do it for parallel processing?) and allow to re-define any SNAPHU parameter. |
I would say that expecting users to manually edit GMTSAR scripts is actually the wrong approach to software development and makes it much harder to operate the software. GMTSAR is already difficult to work with compared to other alternatives (such as SARPROZ), and on top of that users are expected to edit source code instead of being given a simple option to wrap Snaphu params? Even giving the user the ability to define these in a config file (like the batch_tops.config for
I guess a config file would be acceptable for this, no? |
So are you going to provide scripts parameters but using them user will need to manually check SNAPHU log files and manually rewrite SNAPHU configuration file! It doesn’t look as helpful option. I suppose if you will try SNAPHU tiling unwrapping on many examples probably you will think twice to possibility of using the feature by just adding some optional parameters but without any tools to check and debug the processing and without easy way to redefine any of SNAPHU parameters. As a result the tiling unwrapping will produce unreasonable crashes and wrong results when SNAPHU doesn’t work with the user-defined and the default parameters combinations and prints suggestions and requirements to the processing logs. At the end of the day, I’ve resolved it defining a custom config where all the parameters could be redefined and running a single interferogram unwrapping to test the processing and the results before the parallel unwrapping… but it doesn’t work for batch GMTSAR processing pipeline. It’d be nice if you have the solution but I’m afraid you’ll just spend your time and the new option will be mostly frustrating for users. Anyway, please think about the possible problems before you started to code the solution. GMTSAR is hard to use and it’s not actually suitable for high-level hardware configurations or clusters. Just for an example there is no fault-tolerance mechanism for hardware or random software errors in parallel processes which is important for your 32 cores and especially for non-ECC RAM. There is no resource management between the parallel processes and so on and so on. I don’t know how could you resolve the problems in the current software architecture. Actually, I’ve started from a set of bash scripts to replace GMTSAR shell scripts and ended by PyGMTSAR which is based on cluster and fault-tolerance resource manager and I already can work on the same tasks as you work on 32 cores and 256 GB RAM but on Apple Air 24 GB RAM and without so many hassles. Right now I’m building and testing Docker images for GMTSAR as I did for PyGMTSAR to simplify the deployment. There are some compilation and other issues on different hardware platforms which you ignore because it’s important for deployment but it’s not interesting and not related to your current tasks. Sorry, but additional SNAPHU option (which requires so much debugging skills from the users as we discussed above) can’t help anymore! Allow user to install GMTSAR in just one click on any hardware platform and OS and the user will be glad to change a few lines of code to process a huge stack of huge interferograms on a paid project. By my opinion it’d be valuable for GMTSAR project itself if you make some reproducible test cases and document your parameters but one more (or even worse more than one) and not well tested script option(s) will produce even more disappointments. I’m sorry for so long answer because my english is far away from perfect and sometimes it sounds rude I’m afraid but I only tried to explain my technical vision. I spent enough time resolving as I think the same problem and it was impossible to do in a way that satisfies me for GMTSAR shell scripts. I hope you’d do it better. |
I appreciate your insight and obviously you have experience with this issue. As you say GMTSAR is not mature yet for parallel processing, I have even had to make multiple changes myself to make some tasks run many times faster especially considering I run multiple SSD and HEDT / EPYC CPU and I/O or threads is not a bottleneck for me, but RAM is probably the primary factor in unwrapping and I have seen many users on this forum ask why unwrapping is very slow for large AOI, taking many days. And then atmospheric correction sometimes many more. However it looks like this project has made some advances towards parallelization and that's great. |
|
I will provide one such example:
This is a 16 thread system running standard GMTSAR Also notice how these have been unwrapping for 183 hours. |

|
@SteffanDavies I follow your changes and this one is very close to my recent attempts to automate the tiling unwrapping :) Some days ago I've removed the tiling from Google Colab notebook because it works 10-100 times slowly while 24 GB RAM is more than enough for this case but the disk storage is slow and so disk-stored tile processing files are the source of the problem. There are lots of sometimes unpredictable factors for the tiled processing success. The atmospheric correction is black box because we have no way to select the right parameters apriory... I have seen many users on this forum who ask about the right ones :) I think it means we need more documentation and examples and less code. With well-known gaussian filtering (detrending) and well-known correlation-weighted least squares solution I have better results (the example notebook to compare the common weighted least squares solution and GMTSAR SBAS is shared on Google Colab) than using the hard to understand atmospheric correction (ok, that's not so hard if we check the papers but in this case it's surprising that we spend so much resources to converge the measurement to to a linear trend... and miss all seasonal and other valuable changes). Is there any reproducible example when the atmospheric correction works well?.. I think no. And how could we argument user to use so slow and time/RAM/CPU consuming GMTSAR SBAS with magic parameters when the result doesn't look valuable? Obviously, that's not a problem which could be resolved by new code additions. At the same time I found lots of insights with the forum discussions but these insights are hard or impossible to realise using upstream GMTSAR. |
|
It's actually patch-to-patch processing, which usually refers to a pair-wise processing. And batch processing usually means working on a stack of data. You may have noticed that I added an option to p2p_processing.csh a couple of months ago called skip_master, which could either process the master image only or assume master image is done and proceed with the aligned image. Hopefully this'll lead to a universal batch code. It'll still need a couple of steps but those scripts could be easily connected later on. |
|
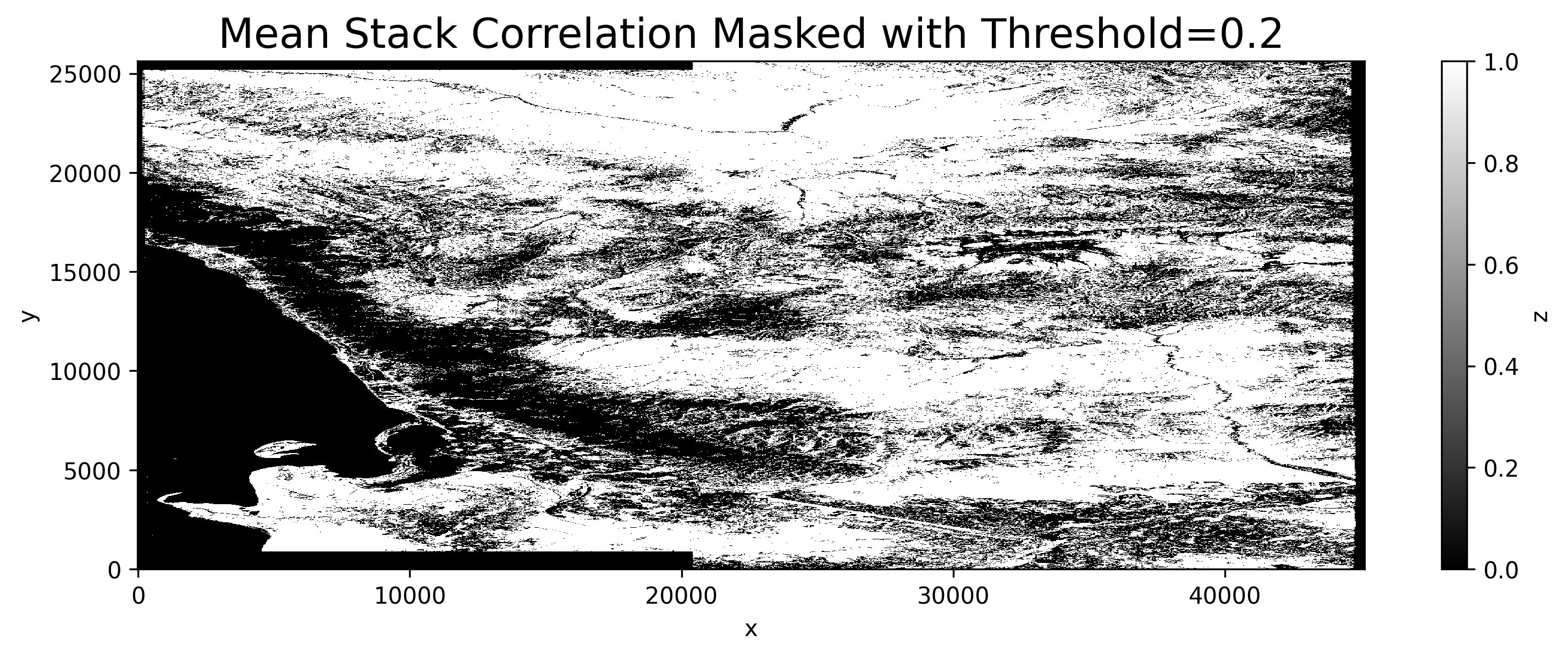
@SteffanDavies Ok, 63 merged interferograms are ready in ~8 hours using 4 CPU cores only (due to RAM limitations): It'd be ~8 times faster on your 32 CPU machine. That means you need ~3 hours to process 2 subswaths and 2 scenes together on your single host. Use stack correlation to unwrap well coherence pixels only (black areas excluded):
SNAPHU custom configuration defined below: SINGLETILEREOPTIMIZE is disabled because I don't have enough RAM for it and it's mostly useless on my tests.
A single interferogram unwrapping requires 14 minutes on 8 cores 16 GB RAM Apple Silicon iMac. On your 32 cores configuration (and almost unlimited RAM) it'd be ~3 minutes for a grid 2 times larger than yours. So you could unwrap ~200 interferograms for two scenes merged in one day (10 hours) on the single machine. And you don't need to run the separate processing on two hosts and merge the separately unwrapped results. But your prefer to spend a whole week for the computation on the two hosts and merge the results manually instead of a single day on one of them and you even reproach me in a premature optimisation. I'm really wondered what do you mean when I can get the results on Apple Air faster then you on your mini datacenter having 32+16 CPU cores and almost 1 TB RAM :) SBAS processing with atmospheric smoothing is not challenging too. I'll start all the interferograms (63) unwrapping for the night to check SBAS processing tomorrow. P.S. By the way, I need to optimise my function for reverse geocode grid calculation because it requires 42 GB RAM for 2 subswaths and 2 scenes with 15m resolution :) |
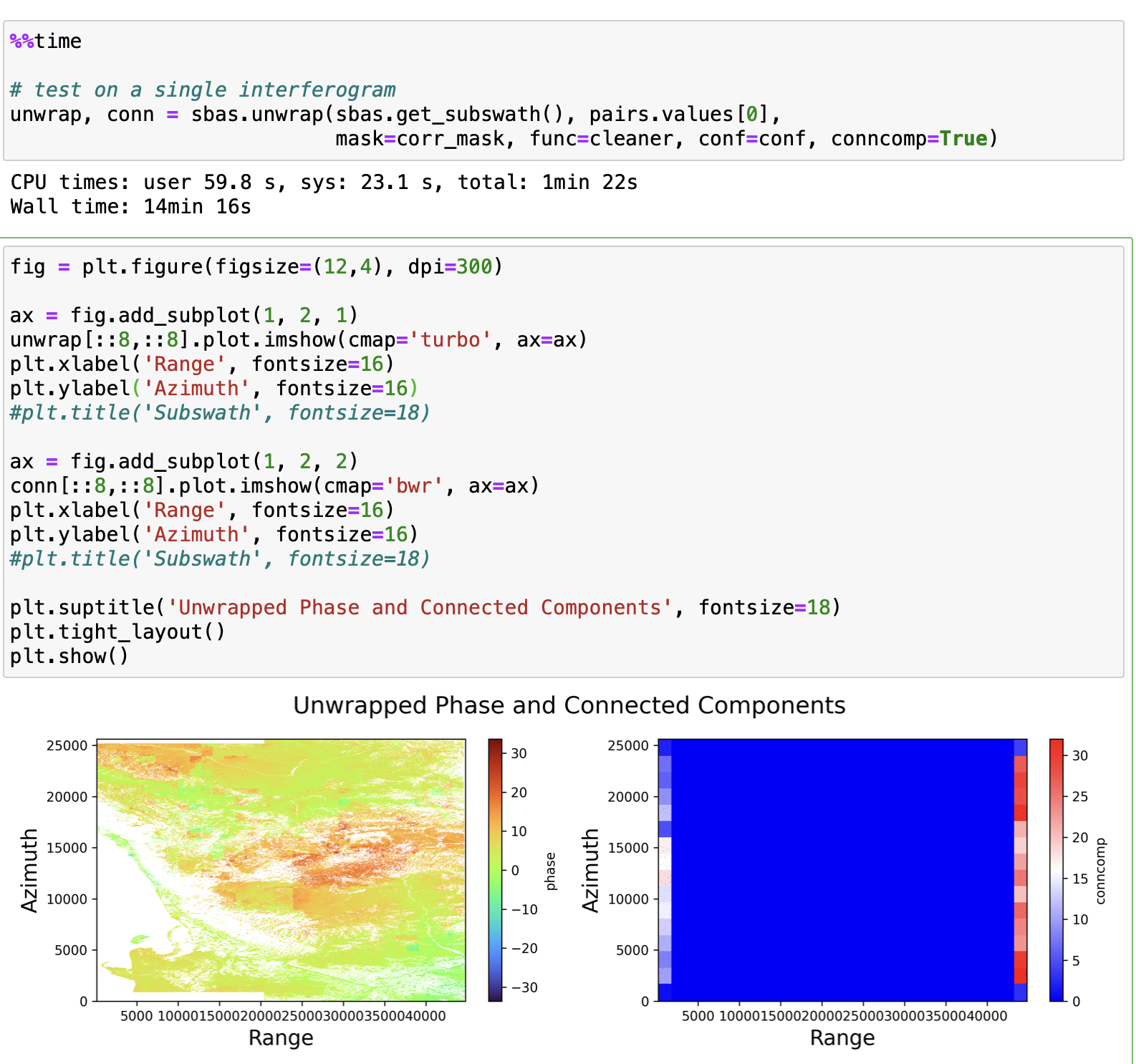
|
@Xiaohua-Eric-Xu I think there are many advantages for the current stack-based processing. Why do you want drop it? That' possible to optimise the stacked processing excluding SLC files creation and using on-the-fly processing on the source GeoTIFF and NetCDF scenes (the both data formats allow cloud-optimised tiling reading). The main GMTSAR problem is obviously GMT-based realisation but your algorithms are great. |
Are these 14 minutes unwrapping times based on the Snaphu tiling? How long would it take to unwrap 1 interferogram without tiles? Good work. |
|
Yes, sure, this is illustration of SNAPHU tiling approach- see the SNAPHU config parameters in my post. We’d make it faster because even tiles with small overlapping could be merged together, we just need to rewrite or optimize SNAPHU SINGLETILEREOPTIMIZE post-processing. I see it as full well decimated interferogram unwrapping plus tiled precision interferogram unwrapping and splitting to spatial components and checking them to define and fix tile-related issues. Also, you’d use SINGLETILEREOPTIMIZE option as is because you have enough RAM for it. Hmm, I didn’t try to run SNAPHU without tiling on this grid because the processing will use just one CPU core and lots of swap. Anyway, you still have a lot of disk operations and need to tune the tiling parameters. Let’s pay attention I can do it interactively using PyGMTSAR but you can’t do the same using GMTSAR batch processing. For the tiling unwrapped output I can do (in just one line of code) detrending with gaussian filtering and map the result to check if tiling works well. I have no idea how could you put all the mandatory possibilities in the new arguments for GMTSAR scripts… I’m afraid without these debugging and visualization tools you will be stacked to launch the full processing again and again to produce some valuable results. I tried to add similar options to my bash scripts based SBAS GMTSAR pipeline and it was not a good way. |
@Xiaohua-Eric-Xu I see that you enabled SNAPHU tile unwrapping with this command.
I am curious to see the SNAPHU log, because single tile re-optimization is enabled with a -S flag
I had mentioned this previously in other thread that when you enable -S flag SNAPHU optimization runs on each tile individually and uses much less memory and time compared to serial SNAPHU optimization on a complete grid (or single tile). After individually unwrapping the tiles, it uses the overlap (in pixels) parameter to estimate offset from adjacent tiles, and then reconstructs a merged unwrap tile, which is then used as initialization for single tile unwrapping. so essentially unwrapping twice. For a two frame SLC with 2 subswath, it reduced unwrapping from 36+ hours on serial to ~2 hours in parallel (dense vegetation+poor coherence). and the parallel portion of SNAPHU only run for the first step, where each individual tiles are unwrapped. After merge the individual tiles, the second unwrapping is essentially single core. It is widely mentioned on forums that ideal pixel number is around 2000 to 3000 pixels per core, which could be used as guidance to estimate number of parallel instance. The tile control parameter can be set in snaphu.conf file (on the fly, by editing the conf file, uncomment and update tile numbers - can be done with another csh file) and invoke -S flag iin the csh script when n_proc is set to any other number than 1 (which could be in the parameter file such as batchtops config or so). And snaphu interp csh would not require much changes. You can have cpu count set to 4, but number of tile much higher and SNAPHU will que the tile unwrapping. |
I agree GMTSAR algorithms are great! but serial GMT operations with heavy IO, and serial C instances are bottlenecks. GMTSAR algorithms are ideal for learning and debugging. scaling and speedup would require customization on the user end. |
And don't forget upcoming satellites, NISAR :) |
As I show in PyGMTSAR the base GMTSAR tools are much faster than you could even think about them! And how about the new way to distribute GMTSAR for end users on Linux/MacOS/Linux arm64/amd64,... without so much hassle with installation: #484 |
No we don't want to drop it. The shell scripts will always be there and the newer development will focus on breaking the limitations and make things easier to use for non-linux-gurus. |
|
@SteffanDavies 63 interferograms tiled unwrapping completed in 14 hours:
|

I am currently testing PyGMTSAR with tilling on a test stack but am running into issues, can you take a look at what I posted in your repository? |
|
@SteffanDavies yes, sure, thanks for all the issue reports! |
|
@Xiaohua-Eric-Xu @SteffanDavies I have some results about unwrapping tricks. As SNAPHU doesn't support NAN values in the input grids we need to fill data gaps using zeroes. There are two ways here: to mask coherence only (i.e. phase is not valid when coherence is zero) and to mask by zeroes the both coherence and phase grids (i.e. masked area have no measurable changes). That's interesting that the second way is significantly faster and it's more stable (in terms of the results difference and the processing time) at the same time (intuitively the 1st one looks more stable I think). Zero-mask coherence onlyThe results are not stable for different tiles configuration (selected two different results):
Zero-mask coherence and phaseThe results are stable for different tiles configuration (the same as for the 1st case above):
The same interferograms unwrapping as aboveUsing the 2nd approach all the 63 interferograms (2 subswaths x 2 scenes on grid size 11157 x 25616) unwrapped in 10 hours on iMac 16 GB RAM.
GMTSAR wayGMTSAR mixes the two approaches for the set of applied masks. I'm surprised about the reasons to use the different ways for user-defined and landmask (there are 3 mask in total as I remember). |





This is expected. For most unwrapping algorithms that plays with residues, the number of residues basically determines how long the algorithm will run. The first approach does not reduce residues, only changes the weigh (coherence) which is to tell the algorithm that these places are not as important but still need a solution. The second approach removes pixels that are bad and will reduce the number of residues. For interseismic or slow changing scenario, the second is always recommended (similar to snaphu_interp.csh). However, if you would like to solve for unreliable locations, e.g., near an earthquake rupture, the first is a better masking approach, though it takes longer to run (snaphu.csh). For cases with good coherence, the two are about the same. |
|
@Xiaohua-Eric-Xu That’s still not obvious for me why the fastest solution is the most accurate too. When we resolve the low-coherence areas the result is (potentially) more accurate because we save the changes for these areas but actually the solution is not stable even for large well-coherent areas. And the numerical instability is not related to rectangular tiles here. While I don’t know which solution is more accurate I always prefer more stable and predictable numerical solution of course. Anyway, SNAPHU tiled unwrapping looks good I think. Maybe do you know some alternative unwrapping engine to compare the results? SNAPHU code looks too weird for me. Mainly it works very well but that’s extremely hard to debug some issues. NODATA values support would be the key to just ignore some areas while it might produce a set of not connected and separately unwrapped areas. |
They may not be. Your "accurate" definition seems to be "spatially smooth" while a lot of natural processes may give you "non-smooth" signals, e.g., earthquakes. And since phase unwrapping is basically solving for the path to integrate phase, less residues usually means the path is easier to solve (or optimize) and more predictable.
I heard there being quite a number of Matlab code for phase unwrapping but I am not sure which one to use. |
|
@Xiaohua-Eric-Xu That's not related to visual properties (like to smoothness) because I mean the numerical stability only - fundamentally, we can't believe to algorithm which produces too different results for a bit different processing parameters. For the practical usage that's more complicated because we can have almost the same detrended results for different unwrapped phase obtained for the same interferogram using different parameters:
You always advice to use detrending and the results above look as the prove why the detrending is so valuable (to resolve unwrapping issues). @SteffanDavies Maybe do you compare your unwrapped detrended results for different unwrapping parameters and resolutions? It'd be insightful to know ho it works for your case. |


Yeah, maybe phase unwrapping is more like art :). Especially for an area filled with residues. I guess the major problem is that we don't really know the ground truth, i.e. the real propagation delay that includes deformation, atmospheric noise, orbit error, ... So when you show different solutions from phase unwrapping, there could always be an argument. |
|
How do you think is it valuable to test PyGMTSAR for more than 2 full scenes (6 subswaths in total, grid size 25617 x 17029)? Potentially I think we can process 5 full scenes using GMTSAR phasediff & phasefilt binaries on Apple Air 16 GB RAM but I'm not sure if the case is practically useful.
|

It'll be useful if someone would like to investigate the deformation over a large area such as the Tibet plateau. |
|
Thanks, understand. As I suppose 30 meters resolution is more than enough for the plateau deformation analysis, right? We can merge 8 full scenes with resolution 30m for the same grid size as 2 scenes with resolution 15 meters. Actually, I didn’t think before that someone could use 15 meters resolution for a large area analysis but the roads analysis is the case. |
|
@SteffanDavies @Xiaohua-Eric-Xu Recent PyGMTSAR update allows to process the examples using 4 GB RAM in Docker container on Windows/MacOS/Linux/etc. (where the RAM and swap are hard limited), see the image on DockerHub https://hub.docker.com/r/mobigroup/pygmtsar I could build Docker image for 2 stitched scenes processing on 8 or 16 GB RAM if it'd be helpful (8 GB RAM limit allows to run the processing on 10 years old laptops). Please let me know what do you think about it. |

|
@SteffanDavies @Xiaohua-Eric-Xu
PyGMTSAR (Python GMTSAR) - Sentinel-1 Satellite Interferometry (SBAS InSAR) for Experts - see Live Jupyter Notebooks to know how to process 34 large interferograms using high resolution 15 meters (2 stitched SLC scenes 3 subswath each and the grid size ~25000x25000 pixels) using 16 GB RAM only. I test this example on Apple Air laptop and even in reproducible Docker container (to be sure swap is not used) and it works well. Use 50 GB Docker image available on DockerHub or download the example dataset (50 GB zipped size) and the notebooks as described by the link: https://hub.docker.com/repository/docker/mobigroup/pygmtsar-large |

|
@SteffanDavies 34 interferograms processing requires 2 days on Apple Air in 16 GB RAM Docker container and it is about 2 times faster without the container. So your ~200 interferograms could be processed in ~1 week on Apple Air 16 GB RAM instead of the separate scenes processing on your two hosts (32 cores 512 GB RAM + 16 cores 256 GB RAM) what requires the same time. |
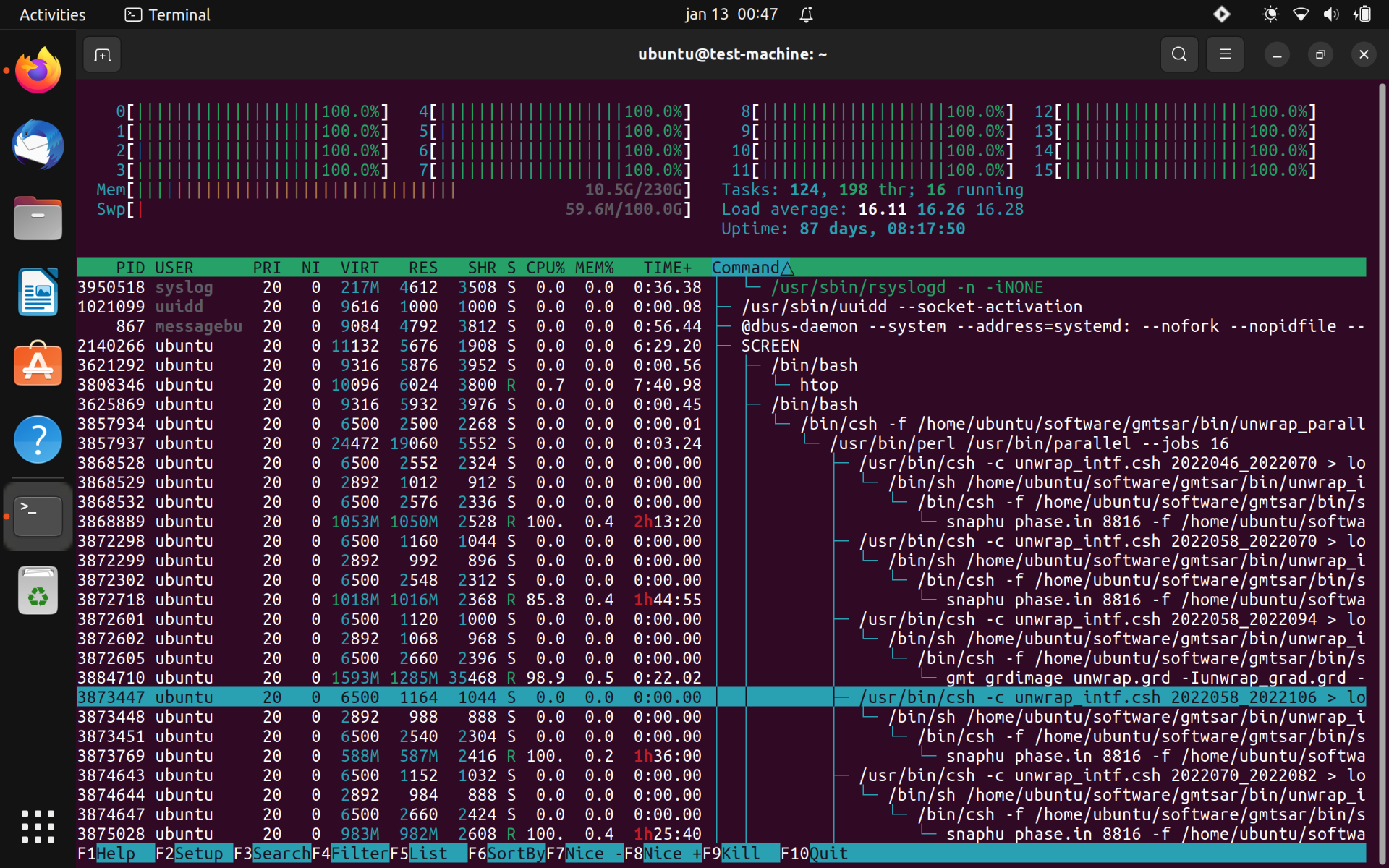
@chintals You mention enabling -S flag when --nproc > 1, however I believe it can be more efficient in some cases to run parallel tiled unwrapping of multiple interferograms using only 1 CPU for each unwrapping process. This is because, at least on my tests, snaphu does not use full 100% cpu utilization 100% of the time when unwrapping a tiled interferogram using multiple cores, however when using single core it is always 100% and also does not need to wait for final tiles to finish before moving onto the next interferogram. See here for example:
I am unwrapping 16 interferograms in parallel using 1 core each and a custom tile configuration that gives me between 2000-3000 pixels per tile. Memory usage can spike up which I assume is due to the -S single tile unwrapping. The idea is to maximize CPU usage at all times while maintaining RAM manageable. |
|
@SteffanDavies You’d use 1.5N SNAPHU processes on N cores CPU for the effective CPU utilization. Also, the main complexity is to select the right amount of SNAPHU processes and tiles number for your available RAM amount. See the Docker image for the illustration: https://hub.docker.com/r/mobigroup/pygmtsar-large There is no way to do it in GMTSAR batch processing because we need to perform multiple test runs and check SNAPHU logs and output results. Are you ready to start the full processing including interferograms creation for the every test? Or maybe are you going to do the tests manually in command line substituting all the parameters by your hands? Sure, that’s not a reproducible way which can be used regularly. While you have no reproducible way which is completely coded in a single script or Jupyter notebook it does not work for users. Probably, you will not be able to repeat your own steps a few months later. |
Completing unwrapping of very large areas can take many days or even weeks when working with large numbers of interferograms, even when unwrapping in parallel. This is a serious bottleneck for GMTSAR. Snaphu has optional tiling parameters which are compatible with multithreading, and unwrapping of multiple smaller tiles will generally be much faster than a single large product.
Some tilling parameters available for Snaphu, according to documentation:
I'm currently not sure how tiling could affect unwrapping quality especially in tile borders. However if this option were available it would be simple to run some tests and it would be optional anyway.
Tiling would also provide an advantage in RAM bottlenecks. For example I am currently unwrapping a large area which requires ~10GB RAM for each interferogram. As I only have 250 GB of RAM, this will limit the number of CPUs I can use to around 20, which is wasting the other 12 available cores.
I would suggest adding additional optional arguments to unwrap_parallel.csh, which would relate to the above Snaphu options. Thus it would be possible to, for example, divide each interferogram into 8 tiles and run 4 parallel snaphu processes for a total of 32 cores or some other combination.
The text was updated successfully, but these errors were encountered: